64 Repositories
Latest Python Libraries

Any-to-any voice conversion using synthetic specific-speaker speeches as intermedium features
MediumVC MediumVC is an utterance-level method towards any-to-any VC. Before that, we propose SingleVC to perform A2O tasks(Xi → Ŷi) , Xi means utter
 47 Dec 25, 2022
47 Dec 25, 2022

SingleVC performs any-to-one VC, which is an important component of MediumVC project.
SingleVC performs any-to-one VC, which is an important component of MediumVC project. Here is the official implementation of the paper, MediumVC.
26 Dec 28, 2022

IMS-Toucan is a toolkit to train state-of-the-art Speech Synthesis models
IMS-Toucan is a toolkit to train state-of-the-art Speech Synthesis models. Everything is pure Python and PyTorch based to keep it as simple and beginner-friendly, yet powerful as possible.
 247 Jan 05, 2023
247 Jan 05, 2023
YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for everyone
YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for everyone In our recent paper we propose the YourTTS model. YourTTS bri
 390 Dec 29, 2022
390 Dec 29, 2022

Meta-TTS: Meta-Learning for Few-shot SpeakerAdaptive Text-to-Speech
Meta-TTS: Meta-Learning for Few-shot SpeakerAdaptive Text-to-Speech This repository is the official implementation of "Meta-TTS: Meta-Learning for Few
 128 Dec 25, 2022
128 Dec 25, 2022
TensorFlowTTS: Real-Time State-of-the-art Speech Synthesis for Tensorflow 2 (supported including English, Korean, Chinese, German and Easy to adapt for other languages)
🤪 TensorFlowTTS provides real-time state-of-the-art speech synthesis architectures such as Tacotron-2, Melgan, Multiband-Melgan, FastSpeech, FastSpeech2 based-on TensorFlow 2. With Tensorflow 2, we c
 3k Jan 04, 2023
3k Jan 04, 2023
StarGAN-ZSVC: Unofficial PyTorch Implementation
This repository is an unofficial PyTorch implementation of StarGAN-ZSVC by Matthew Baas and Herman Kamper. This repository provides both model architectures and the code to inference or train them.
 11 Aug 28, 2022
11 Aug 28, 2022

Official implementation of FCL-taco2: Fast, Controllable and Lightweight version of Tacotron2 @ ICASSP 2021
FCL-Taco2: Towards Fast, Controllable and Lightweight Text-to-Speech synthesis (ICASSP 2021) Paper | Demo Block diagram of FCL-taco2, where the decode
 39 Sep 28, 2022
39 Sep 28, 2022

Global Rhythm Style Transfer Without Text Transcriptions
Global Prosody Style Transfer Without Text Transcriptions This repository provides a PyTorch implementation of AutoPST, which enables unsupervised glo
 193 Dec 30, 2022
193 Dec 30, 2022
Global Rhythm Style Transfer Without Text Transcriptions
Global Prosody Style Transfer Without Text Transcriptions This repository provides a PyTorch implementation of AutoPST, which enables unsupervised glo
193 Dec 30, 2022
Any-to-any voice conversion using synthetic specific-speaker speeches as intermedium features
MediumVC MediumVC is an utterance-level method towards any-to-any VC. Before that, we propose SingleVC to perform A2O tasks(Xi → Ŷi) , Xi means utter
47 Dec 25, 2022
An 16kHz implementation of HiFi-GAN for soft-vc.
HiFi-GAN An 16kHz implementation of HiFi-GAN for soft-vc. Relevant links: Official HiFi-GAN repo HiFi-GAN paper Soft-VC repo Soft-VC paper Example Usa
 42 Dec 27, 2022
42 Dec 27, 2022
End-to-End Speech Processing Toolkit
ESPnet: end-to-end speech processing toolkit system/pytorch ver. 1.3.1 1.4.0 1.5.1 1.6.0 1.7.1 1.8.1 1.9.0 ubuntu20/python3.9/pip ubuntu20/python3.8/p
 5.9k Jan 04, 2023
5.9k Jan 04, 2023
End-to-End Speech Processing Toolkit
ESPnet: end-to-end speech processing toolkit system/pytorch ver. 1.0.1 1.1.0 1.2.0 1.3.1 1.4.0 1.5.1 1.6.0 1.7.1 1.8.1 ubuntu18/python3.8/pip ubuntu18
5.9k Jan 03, 2023
HF's ML for Audio study group
Hugging Face Machine Learning for Audio Study Group Welcome to the ML for Audio Study Group. Through a series of presentations, paper reading and disc
 110 Jan 01, 2023
110 Jan 01, 2023
This is the main repository of open-sourced speech technology by Huawei Noah's Ark Lab.
Speech-Backbones This is the main repository of open-sourced speech technology by Huawei Noah's Ark Lab. Grad-TTS Official implementation of the Grad-
 295 Jan 07, 2023
295 Jan 07, 2023

iSTFTNet : Fast and Lightweight Mel-spectrogram Vocoder Incorporating Inverse Short-time Fourier Transform
iSTFTNet : Fast and Lightweight Mel-spectrogram Vocoder Incorporating Inverse Short-time Fourier Transform This repo try to implement iSTFTNet : Fast
 126 Jan 02, 2023
126 Jan 02, 2023

Implementation of Google Brain's WaveGrad high-fidelity vocoder
WaveGrad Implementation (PyTorch) of Google Brain's high-fidelity WaveGrad vocoder (paper). First implementation on GitHub with high-quality generatio
 363 Dec 27, 2022
363 Dec 27, 2022

HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis Jungil Kong, Jaehyeon Kim, Jaekyoung Bae In our paper, we p
 1.1k Jan 02, 2023
1.1k Jan 02, 2023
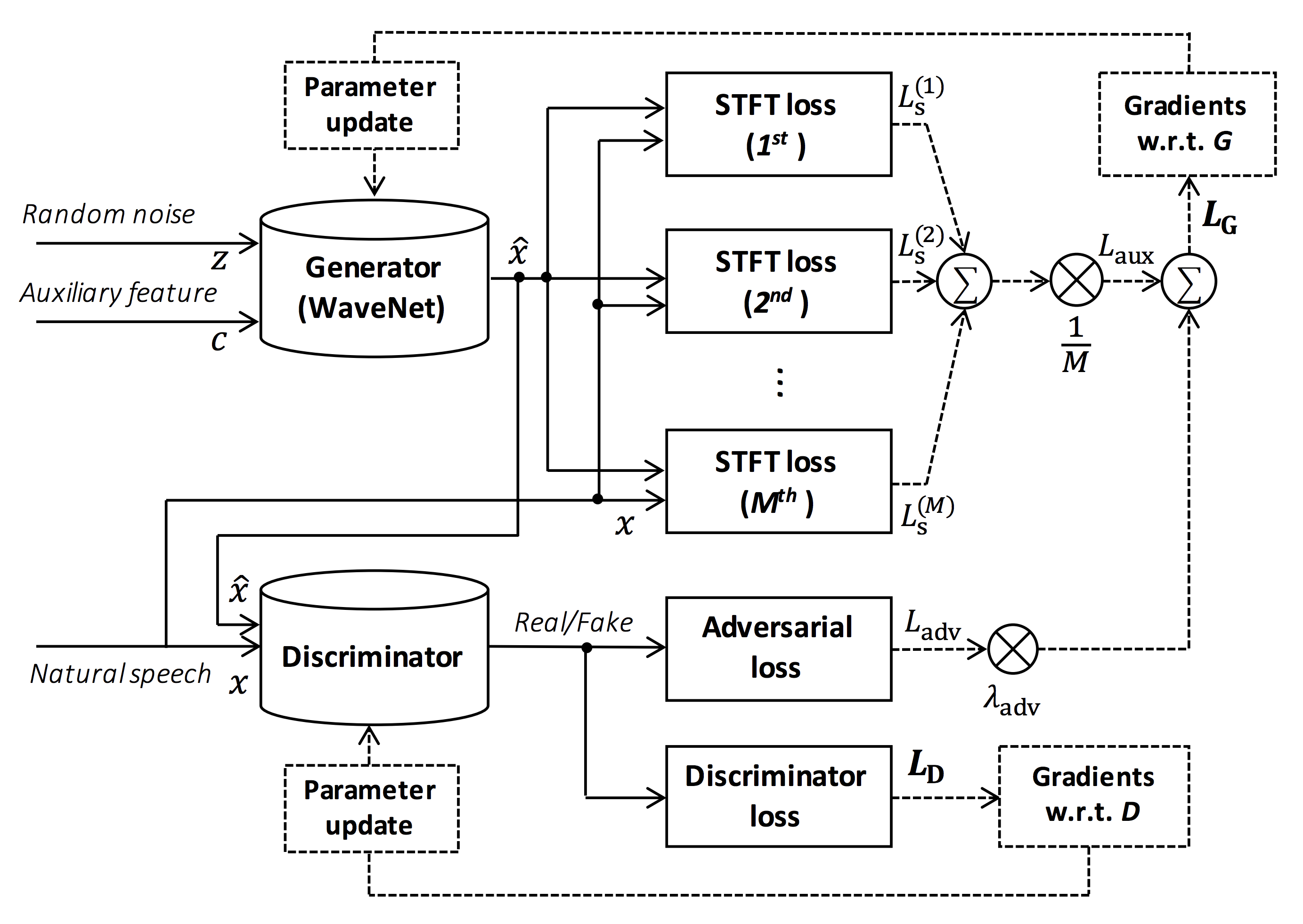
Unofficial Parallel WaveGAN (+ MelGAN & Multi-band MelGAN & HiFi-GAN & StyleMelGAN) with Pytorch
Parallel WaveGAN implementation with Pytorch This repository provides UNOFFICIAL pytorch implementations of the following models: Parallel WaveGAN Mel
 1.2k Dec 23, 2022
1.2k Dec 23, 2022

Comprehensive-E2E-TTS - PyTorch Implementation
A Non-Autoregressive End-to-End Text-to-Speech (text-to-wav), supporting a family of SOTA unsupervised duration modelings. This project grows with the research community, aiming to achieve the ultima
 114 Nov 13, 2022
114 Nov 13, 2022

A Non-Autoregressive Transformer based TTS, supporting a family of SOTA transformers with supervised and unsupervised duration modelings. This project grows with the research community, aiming to achieve the ultimate TTS.
A Non-Autoregressive Transformer based TTS, supporting a family of SOTA transformers with supervised and unsupervised duration modelings. This project grows with the research community, aiming to ach
237 Jan 02, 2023

PyTorch Implementation of ByteDance's Cross-speaker Emotion Transfer Based on Speaker Condition Layer Normalization and Semi-Supervised Training in Text-To-Speech
Cross-Speaker-Emotion-Transfer - PyTorch Implementation PyTorch Implementation of ByteDance's Cross-speaker Emotion Transfer Based on Speaker Conditio
114 Jan 08, 2023

PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis
Daft-Exprt - PyTorch Implementation PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis The
47 Dec 18, 2022
This is a template for the Non-autoregressive Deep Learning-Based TTS model (in PyTorch).
Non-autoregressive Deep Learning-Based TTS Template This is a template for the Non-autoregressive TTS model. It contains Data Preprocessing Pipeline D
13 Dec 05, 2022

PyTorch Implementation of DiffGAN-TTS: High-Fidelity and Efficient Text-to-Speech with Denoising Diffusion GANs
DiffGAN-TTS - PyTorch Implementation PyTorch implementation of DiffGAN-TTS: High
157 Jan 01, 2023

Pytorch Implementation of DiffSinger: Diffusion Acoustic Model for Singing Voice Synthesis (TTS Extension)
DiffSinger - PyTorch Implementation PyTorch implementation of DiffSinger: Diffusion Acoustic Model for Singing Voice Synthesis (TTS Extension). Status
152 Jan 02, 2023

PyTorch Implementation of NCSOFT's FastPitchFormant: Source-filter based Decomposed Modeling for Speech Synthesis
FastPitchFormant - PyTorch Implementation PyTorch Implementation of FastPitchFormant: Source-filter based Decomposed Modeling for Speech Synthesis. Qu
63 Jan 02, 2023

Pytorch Implementation of Google's Parallel Tacotron 2: A Non-Autoregressive Neural TTS Model with Differentiable Duration Modeling
Parallel Tacotron2 Pytorch Implementation of Google's Parallel Tacotron 2: A Non-Autoregressive Neural TTS Model with Differentiable Duration Modeling
170 Dec 27, 2022

PyTorch Implementation of PortaSpeech: Portable and High-Quality Generative Text-to-Speech
PortaSpeech - PyTorch Implementation PyTorch Implementation of PortaSpeech: Portable and High-Quality Generative Text-to-Speech. Model Size Module Nor
279 Jan 04, 2023
PortaSpeech - PyTorch Implementation
PortaSpeech - PyTorch Implementation PyTorch Implementation of PortaSpeech: Portable and High-Quality Generative Text-to-Speech. Model Size Module Nor
276 Dec 26, 2022

PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation
StyleSpeech - PyTorch Implementation PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation. Status (2021.06.09
142 Jan 06, 2023
PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation
StyleSpeech - PyTorch Implementation PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation. Status (2021.06.13
140 Dec 21, 2022

PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
VAENAR-TTS - PyTorch Implementation PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
67 Nov 14, 2022
PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
VAENAR-TTS - PyTorch Implementation PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
67 Nov 14, 2022

PyTorch Implementation of Google Brain's WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis
WaveGrad2 - PyTorch Implementation PyTorch Implementation of Google Brain's WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis. Status (202
59 Dec 06, 2022
Leon is an open-source personal assistant who can live on your server.
Leon Your open-source personal assistant. Website :: Documentation :: Roadmap :: Contributing :: Story 👋 Introduction Leon is an open-source personal
 11.7k Dec 30, 2022
11.7k Dec 30, 2022
DiffWave is a fast, high-quality neural vocoder and waveform synthesizer.
DiffWave DiffWave is a fast, high-quality neural vocoder and waveform synthesizer. It starts with Gaussian noise and converts it into speech via itera
 498 Jan 03, 2023
498 Jan 03, 2023

Unofficial PyTorch Implementation of UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
UnivNet UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation This is an unofficial PyTorch
 170 Jan 04, 2023
170 Jan 04, 2023

Unofficial Pytorch Implementation of WaveGrad2
WaveGrad 2 — Unofficial PyTorch Implementation WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis Unofficial PyTorch+Lightning Implementati
104 Nov 29, 2022
Byte-based multilingual transformer TTS for low-resource/few-shot language adaptation.
One model to speak them all 🌎 Audio Language Text ▷ Chinese 人人生而自由,在尊严和权利上一律平等。 ▷ English All human beings are born free and equal in dignity and rig
 60 Nov 14, 2022
60 Nov 14, 2022
Neural Lexicon Reader: Reduce Pronunciation Errors in End-to-end TTS by Leveraging External Textual Knowledge
Neural Lexicon Reader: Reduce Pronunciation Errors in End-to-end TTS by Leveraging External Textual Knowledge This is an implementation of the paper,
19 Oct 14, 2022
Neural Lexicon Reader: Reduce Pronunciation Errors in End-to-end TTS by Leveraging External Textual Knowledge
Neural Lexicon Reader: Reduce Pronunciation Errors in End-to-end TTS by Leveraging External Textual Knowledge This is an implementation of the paper,
19 Oct 14, 2022
EdiTTS: Score-based Editing for Controllable Text-to-Speech
Official implementation of EdiTTS: Score-based Editing for Controllable Text-to-Speech
 99 Jan 02, 2023
99 Jan 02, 2023
Official implementation of EdiTTS: Score-based Editing for Controllable Text-to-Speech
EdiTTS: Score-based Editing for Controllable Text-to-Speech Official implementation of EdiTTS: Score-based Editing for Controllable Text-to-Speech. Au
98 Dec 25, 2022
🐤 Nix-TTS: An Incredibly Lightweight End-to-End Text-to-Speech Model via Non End-to-End Distillation
🐤 Nix-TTS An Incredibly Lightweight End-to-End Text-to-Speech Model via Non End-to-End Distillation Rendi Chevi, Radityo Eko Prasojo, Alham Fikri Aji
 156 Jan 09, 2023
156 Jan 09, 2023

PyTorch implementation of convolutional neural networks-based text-to-speech synthesis models
Deepvoice3_pytorch PyTorch implementation of convolutional networks-based text-to-speech synthesis models: arXiv:1710.07654: Deep Voice 3: Scaling Tex
 1.8k Dec 30, 2022
1.8k Dec 30, 2022
PyTorch implementation of convolutional neural networks-based text-to-speech synthesis models
Deepvoice3_pytorch PyTorch implementation of convolutional networks-based text-to-speech synthesis models: arXiv:1710.07654: Deep Voice 3: Scaling Tex
1.8k Jan 08, 2023
PyTorch implementation of Tacotron speech synthesis model.
tacotron_pytorch PyTorch implementation of Tacotron speech synthesis model. Inspired from keithito/tacotron. Currently not as much good speech quality
279 Dec 09, 2022
PyTorch implementation of Tacotron speech synthesis model.
tacotron_pytorch PyTorch implementation of Tacotron speech synthesis model. Inspired from keithito/tacotron. Currently not as much good speech quality
279 Dec 09, 2022

ttslearn: Library for Pythonで学ぶ音声合成 (Text-to-speech with Python)
ttslearn: Library for Pythonで学ぶ音声合成 (Text-to-speech with Python) 日本語は以下に続きます (Japanese follows) English: This book is written in Japanese and primaril
189 Dec 29, 2022
Fre-GAN: Adversarial Frequency-consistent Audio Synthesis
Fre-GAN Vocoder Fre-GAN: Adversarial Frequency-consistent Audio Synthesis Training: python train.py --config config.json Citation: @misc{kim2021frega
93 Dec 17, 2022
LightSpeech: Lightweight and Fast Text to Speech with Neural Architecture Search
LightSpeech UnOfficial PyTorch implementation of LightSpeech: Lightweight and Fast Text to Speech with Neural Architecture Search.
54 Dec 03, 2022
TalkNet 2: Non-Autoregressive Depth-Wise Separable Convolutional Model for Speech Synthesis with Explicit Pitch and Duration Prediction.
TalkNet 2 [WIP] TalkNet 2: Non-Autoregressive Depth-Wise Separable Convolutional Model for Speech Synthesis with Explicit Pitch and Duration Predictio
69 Dec 17, 2022
UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
UnivNet UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation. Training python train.py --c
55 Dec 26, 2022

Unofficial Implementation of Zero-Shot Text-to-Speech for Text-Based Insertion in Audio Narration
Zero-Shot Text-to-Speech for Text-Based Insertion in Audio Narration This repo contains only model Implementation of Zero-Shot Text-to-Speech for Text
33 Sep 22, 2022

HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis Jungil Kong, Jaehyeon Kim, Jaekyoung Bae In our paper, we p
31 Dec 08, 2022
SelfRemaster: SSL Speech Restoration
SelfRemaster: Self-Supervised Speech Restoration Official implementation of SelfRemaster: Self-Supervised Speech Restoration with Analysis-by-Synthesi
 46 Jan 07, 2023
46 Jan 07, 2023
Neural HMMs are all you need (for high-quality attention-free TTS)
Neural HMMs are all you need (for high-quality attention-free TTS) Shivam Mehta, Éva Székely, Jonas Beskow, and Gustav Eje Henter This is the official
 0 Oct 28, 2022
0 Oct 28, 2022

Spokestack is a library that allows a user to easily incorporate a voice interface into any Python application with a focus on embedded systems.
Welcome to Spokestack Python! This library is intended for developing voice interfaces in Python. This can include anything from Raspberry Pi applicat
 133 Sep 20, 2022
133 Sep 20, 2022