273 Repositories
Latest Python Libraries
Trained T5 and T5-large model for creating keywords from text
text to keywords Trained T5-base and T5-large model for creating keywords from text. Supported languages: ru Pretraining Large version | Pretraining B
 61 Nov 24, 2022
61 Nov 24, 2022
Huggingface Transformers + Adapters = ❤️
adapter-transformers A friendly fork of HuggingFace's Transformers, adding Adapters to PyTorch language models adapter-transformers is an extension of
 1.2k Jan 09, 2023
1.2k Jan 09, 2023
Built a deep neural network (DNN) that functions as an end-to-end machine translation pipeline
Built a deep neural network (DNN) that functions as an end-to-end machine translation pipeline. The pipeline accepts english text as input and returns the French translation.
 1 Jan 24, 2022
1 Jan 24, 2022
Towards Fine-Grained Reasoning for Fake News Detection
FinerFact This is the PyTorch implementation for the FinerFact model in the AAAI 2022 paper Towards Fine-Grained Reasoning for Fake News Detection (Ar
 15 Dec 15, 2022
15 Dec 15, 2022
The official implementation for ACL 2021 "Challenges in Information Seeking QA: Unanswerable Questions and Paragraph Retrieval".
Code for "Challenges in Information Seeking QA: Unanswerable Questions and Paragraph Retrieval" (ACL 2021, Long) This is the repository for baseline m
 25 Oct 30, 2022
25 Oct 30, 2022
A Multilingual Latent Dirichlet Allocation (LDA) Pipeline with Stop Words Removal, n-gram features, and Inverse Stemming, in Python.
Multilingual Latent Dirichlet Allocation (LDA) Pipeline This project is for text clustering using the Latent Dirichlet Allocation (LDA) algorithm. It
 74 Oct 07, 2022
74 Oct 07, 2022

TorchFlare is a simple, beginner-friendly, and easy-to-use PyTorch Framework train your models effortlessly.
TorchFlare TorchFlare is a simple, beginner-friendly and an easy-to-use PyTorch Framework train your models without much effort. It provides an almost
 85 Dec 26, 2022
85 Dec 26, 2022

Korean Simple Contrastive Learning of Sentence Embeddings using SKT KoBERT and kakaobrain KorNLU dataset
KoSimCSE Korean Simple Contrastive Learning of Sentence Embeddings implementation using pytorch SimCSE Installation git clone https://github.com/BM-K/
 34 Nov 24, 2022
34 Nov 24, 2022

Data and evaluation code for the paper WikiNEuRal: Combined Neural and Knowledge-based Silver Data Creation for Multilingual NER (EMNLP 2021).
Data and evaluation code for the paper WikiNEuRal: Combined Neural and Knowledge-based Silver Data Creation for Multilingual NER. @inproceedings{tedes
 40 Dec 11, 2022
40 Dec 11, 2022

Multilingual word vectors in 78 languages
Aligning the fastText vectors of 78 languages Facebook recently open-sourced word vectors in 89 languages. However these vectors are monolingual; mean
 1.2k Dec 17, 2022
1.2k Dec 17, 2022
Blue Brain text mining toolbox for semantic search and structured information extraction
Blue Brain Search Source Code DOI Data & Models DOI Documentation Latest Release Python Versions License Build Status Static Typing Code Style Securit
 29 Dec 01, 2022
29 Dec 01, 2022
NaturalCC is a sequence modeling toolkit that allows researchers and developers to train custom models
NaturalCC NaturalCC is a sequence modeling toolkit that allows researchers and developers to train custom models for many software engineering tasks,
 159 Dec 28, 2022
159 Dec 28, 2022

⚡ Automatically decrypt encryptions without knowing the key or cipher, decode encodings, and crack hashes ⚡
⚡ Automatically decrypt encryptions without knowing the key or cipher, decode encodings, and crack hashes ⚡
 11.2k Jan 09, 2023
11.2k Jan 09, 2023
⚡ Automatically decrypt encryptions without knowing the key or cipher, decode encodings, and crack hashes ⚡
Translations 🇩🇪 DE 🇫🇷 FR 🇭🇺 HU 🇮🇩 ID 🇮🇹 IT 🇳🇱 NL 🇧🇷 PT-BR 🇷🇺 RU 🇨🇳 ZH ➡️ Documentation | Discord | Installation Guide ⬅️ Fully autom
11.2k Jan 05, 2023
Collection of NLP model explanations and accompanying analysis tools
Thermostat is a large collection of NLP model explanations and accompanying analysis tools. Combines explainability methods from the captum library wi
 126 Nov 22, 2022
126 Nov 22, 2022
Pytorch implementations of various Deep NLP models in cs-224n(Stanford Univ)
DeepNLP-models-Pytorch Pytorch implementations of various Deep NLP models in cs-224n(Stanford Univ: NLP with Deep Learning) This is not for Pytorch be
 2.9k Dec 24, 2022
2.9k Dec 24, 2022

Python implementation of TextRank for phrase extraction and summarization of text documents
PyTextRank PyTextRank is a Python implementation of TextRank as a spaCy pipeline extension, used to: extract the top-ranked phrases from text document
 1.9k Jan 06, 2023
1.9k Jan 06, 2023

FedNLP: A Benchmarking Framework for Federated Learning in Natural Language Processing
FedNLP is a research-oriented benchmarking framework for advancing federated learning (FL) in natural language processing (NLP). It uses FedML repository as the git submodule. In other words, FedNLP
 216 Nov 27, 2022
216 Nov 27, 2022

This project uses unsupervised machine learning to identify correlations between daily inoculation rates in the USA and twitter sentiment in regards to COVID-19.
Twitter COVID-19 Sentiment Analysis Members: Christopher Bach | Khalid Hamid Fallous | Jay Hirpara | Jing Tang | Graham Thomas | David Wetherhold Pro
 4 Oct 15, 2022
4 Oct 15, 2022
MixText: Linguistically-Informed Interpolation of Hidden Space for Semi-Supervised Text Classification
MixText This repo contains codes for the following paper: Jiaao Chen, Zichao Yang, Diyi Yang: MixText: Linguistically-Informed Interpolation of Hidden
 309 Dec 12, 2022
309 Dec 12, 2022
Learn how to responsibly deliver value with ML.
Made With ML Applied ML · MLOps · Production Join 30K+ developers in learning how to responsibly deliver value with ML. 🔥 Among the top MLOps reposit
 32k Dec 30, 2022
32k Dec 30, 2022

A Unified Framework and Analysis for Structured Knowledge Grounding
UnifiedSKG 📚 : Unifying and Multi-Tasking Structured Knowledge Grounding with Text-to-Text Language Models Code for paper UnifiedSKG: Unifying and Mu
 370 Dec 21, 2022
370 Dec 21, 2022
Training open neural machine translation models
Train Opus-MT models This package includes scripts for training NMT models using MarianNMT and OPUS data for OPUS-MT. More details are given in the Ma
 167 Jan 03, 2023
167 Jan 03, 2023

Bidirectional LSTM-CRF and ELMo for Named-Entity Recognition, Part-of-Speech Tagging and so on.
anaGo anaGo is a Python library for sequence labeling(NER, PoS Tagging,...), implemented in Keras. anaGo can solve sequence labeling tasks such as nam
 1.5k Dec 05, 2022
1.5k Dec 05, 2022

A text augmentation tool for named entity recognition.
neraug This python library helps you with augmenting text data for named entity recognition. Augmentation Example Reference from An Analysis of Simple
48 Oct 11, 2022

FactSumm: Factual Consistency Scorer for Abstractive Summarization
FactSumm: Factual Consistency Scorer for Abstractive Summarization FactSumm is a toolkit that scores Factualy Consistency for Abstract Summarization W
 83 Jan 09, 2023
83 Jan 09, 2023

Training and evaluation codes for the BertGen paper (ACL-IJCNLP 2021)
BERTGEN This repository is the implementation of the paper "BERTGEN: Multi-task Generation through BERT" (https://arxiv.org/abs/2106.03484). The codeb
 [email protected]">
9 Oct 26, 2022
[email protected]">
9 Oct 26, 2022
A Chinese to English Neural Model Translation Project
ZH-EN NMT Chinese to English Neural Machine Translation This project is inspired by Stanford's CS224N NMT Project Dataset used in this project: News C
 29 Nov 26, 2022
29 Nov 26, 2022
A Chinese to English Neural Model Translation Project
ZH-EN NMT Chinese to English Neural Machine Translation This project is inspired by Stanford's CS224N NMT Project Dataset used in this project: News C
29 Nov 26, 2022

Beautiful visualizations of how language differs among document types.
Scattertext 0.1.0.0 A tool for finding distinguishing terms in corpora and displaying them in an interactive HTML scatter plot. Points corresponding t
 2k Dec 27, 2022
2k Dec 27, 2022
State of the Art Natural Language Processing
Spark NLP: State of the Art Natural Language Processing Spark NLP is a Natural Language Processing library built on top of Apache Spark ML. It provide
 3k Jan 05, 2023
3k Jan 05, 2023
Augmenty is an augmentation library based on spaCy for augmenting texts.
Augmenty: The cherry on top of your NLP pipeline Augmenty is an augmentation library based on spaCy for augmenting texts. Besides a wide array of high
 124 Dec 29, 2022
124 Dec 29, 2022
spaCy-wrap: For Wrapping fine-tuned transformers in spaCy pipelines
spaCy-wrap: For Wrapping fine-tuned transformers in spaCy pipelines spaCy-wrap is minimal library intended for wrapping fine-tuned transformers from t
32 Dec 29, 2022
OCTIS: Comparing Topic Models is Simple! A python package to optimize and evaluate topic models (accepted at EACL2021 demo track)
OCTIS : Optimizing and Comparing Topic Models is Simple! OCTIS (Optimizing and Comparing Topic models Is Simple) aims at training, analyzing and compa
 478 Jan 01, 2023
478 Jan 01, 2023

Speech-Emotion-Analyzer - The neural network model is capable of detecting five different male/female emotions from audio speeches. (Deep Learning, NLP, Python)
Speech Emotion Analyzer The idea behind creating this project was to build a machine learning model that could detect emotions from the speech we have
 965 Dec 24, 2022
965 Dec 24, 2022

TCube generates rich and fluent narratives that describes the characteristics, trends, and anomalies of any time-series data (domain-agnostic) using the transfer learning capabilities of PLMs.
TCube: Domain-Agnostic Neural Time series Narration This repository contains the code for the paper: "TCube: Domain-Agnostic Neural Time series Narrat
 7 Oct 31, 2021
7 Oct 31, 2021
Mycroft Core, the Mycroft Artificial Intelligence platform.
Mycroft Mycroft is a hackable open source voice assistant. Table of Contents Getting Started Running Mycroft Using Mycroft Home Device and Account Man
 6.1k Jan 09, 2023
6.1k Jan 09, 2023
Facilitating the design, comparison and sharing of deep text matching models.
MatchZoo Facilitating the design, comparison and sharing of deep text matching models. MatchZoo 是一个通用的文本匹配工具包,它旨在方便大家快速的实现、比较、以及分享最新的深度文本匹配模型。 🔥 News
 3.7k Jan 02, 2023
3.7k Jan 02, 2023
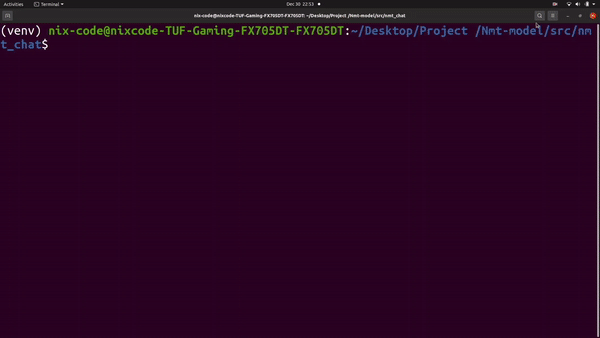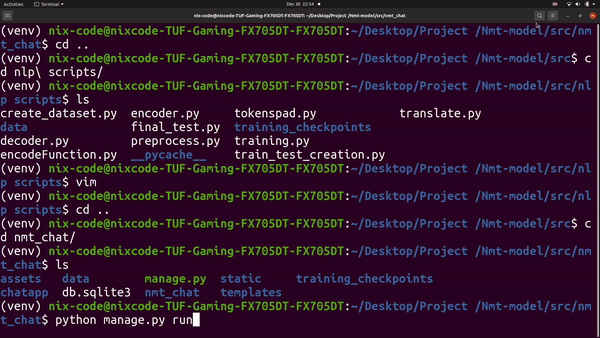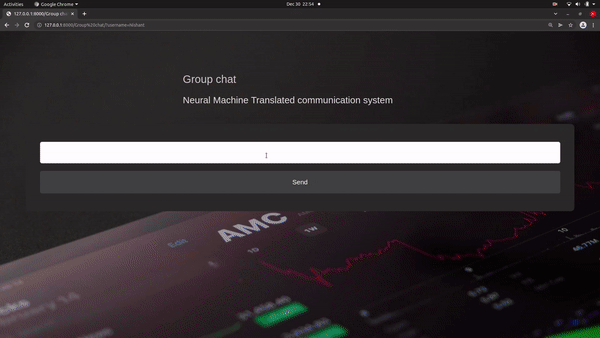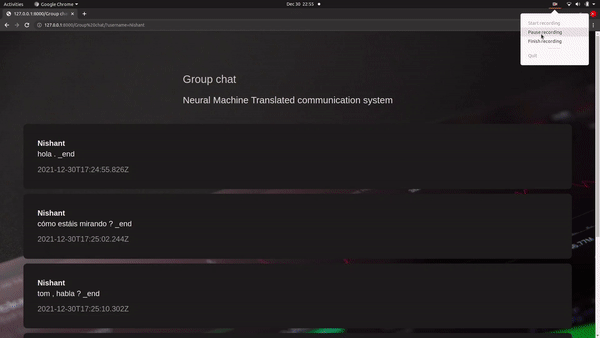
The model is designed to train a single and large neural network in order to predict correct translation by reading the given sentence.
Neural Machine Translation communication system The model is basically direct to convert one source language to another targeted language using encode
 7 Sep 22, 2022
7 Sep 22, 2022
The model is designed to train a single and large neural network in order to predict correct translation by reading the given sentence.
Neural Machine Translation communication system The model is basically direct to convert one source language to another targeted language using encode
7 Sep 22, 2022
skweak: A software toolkit for weak supervision applied to NLP tasks
Labelled data remains a scarce resource in many practical NLP scenarios. This is especially the case when working with resource-poor languages (or text domains), or when using task-specific labels wi
 850 Dec 28, 2022
850 Dec 28, 2022
An easy to use Natural Language Processing library and framework for predicting, training, fine-tuning, and serving up state-of-the-art NLP models.
Welcome to AdaptNLP A high level framework and library for running, training, and deploying state-of-the-art Natural Language Processing (NLP) models
 407 Jan 03, 2023
407 Jan 03, 2023

Official implementations for various pre-training models of ERNIE-family, covering topics of Language Understanding & Generation, Multimodal Understanding & Generation, and beyond.
English|简体中文 ERNIE是百度开创性提出的基于知识增强的持续学习语义理解框架,该框架将大数据预训练与多源丰富知识相结合,通过持续学习技术,不断吸收海量文本数据中词汇、结构、语义等方面的知识,实现模型效果不断进化。ERNIE在累积 40 余个典型 NLP 任务取得 SOTA 效果,并在 G
 5.4k Jan 03, 2023
5.4k Jan 03, 2023
Basic Utilities for PyTorch Natural Language Processing (NLP)
Basic Utilities for PyTorch Natural Language Processing (NLP) PyTorch-NLP, or torchnlp for short, is a library of basic utilities for PyTorch NLP. tor
 2.1k Jan 01, 2023
2.1k Jan 01, 2023
Pretrained SOTA Deep Learning models, callbacks and more for research and production with PyTorch Lightning and PyTorch
Pretrained SOTA Deep Learning models, callbacks and more for research and production with PyTorch Lightning and PyTorch
 1.4k Jan 01, 2023
1.4k Jan 01, 2023
Toolbox of models, callbacks, and datasets for AI/ML researchers.
Pretrained SOTA Deep Learning models, callbacks and more for research and production with PyTorch Lightning and PyTorch Website • Installation • Main
1.4k Dec 30, 2022

TextAttack 🐙 is a Python framework for adversarial attacks, data augmentation, and model training in NLP
TextAttack 🐙 Generating adversarial examples for NLP models [TextAttack Documentation on ReadTheDocs] About • Setup • Usage • Design About TextAttack
 2.2k Jan 03, 2023
2.2k Jan 03, 2023
A paper list of pre-trained language models (PLMs).
Large-scale pre-trained language models (PLMs) such as BERT and GPT have achieved great success and become a milestone in NLP.
 124 Jan 02, 2023
124 Jan 02, 2023
Topic Modelling for Humans
gensim – Topic Modelling in Python Gensim is a Python library for topic modelling, document indexing and similarity retrieval with large corpora. Targ
 13.8k Jan 03, 2023
13.8k Jan 03, 2023
Topic Modelling for Humans
gensim – Topic Modelling in Python Gensim is a Python library for topic modelling, document indexing and similarity retrieval with large corpora. Targ
13.8k Jan 02, 2023
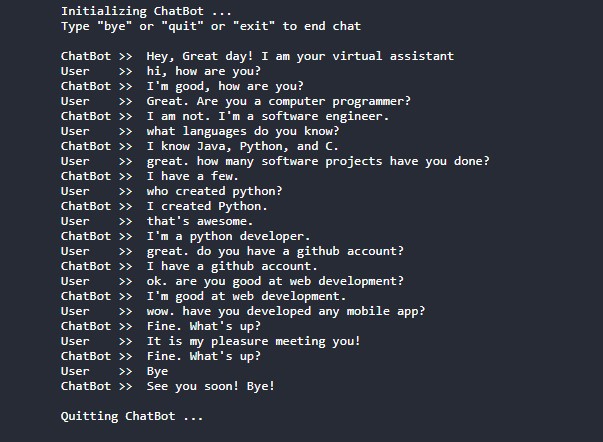
Conversational-AI-ChatBot - Intelligent ChatBot built with Microsoft's DialoGPT transformer to make conversations with human users!
Conversational AI ChatBot Intelligent ChatBot built with Microsoft's DialoGPT transformer to make conversations with human users! In this project? Thi
 6 Nov 30, 2022
6 Nov 30, 2022
💬 Open source machine learning framework to automate text- and voice-based conversations: NLU, dialogue management, connect to Slack, Facebook, and more - Create chatbots and voice assistants
Rasa Open Source Rasa is an open source machine learning framework to automate text-and voice-based conversations. With Rasa, you can build contextual
 15.3k Jan 03, 2023
15.3k Jan 03, 2023
💬 Open source machine learning framework to automate text- and voice-based conversations: NLU, dialogue management, connect to Slack, Facebook, and more - Create chatbots and voice assistants
Rasa Open Source Rasa is an open source machine learning framework to automate text-and voice-based conversations. With Rasa, you can build contextual
15.3k Dec 30, 2022
A Word Level Transformer layer based on PyTorch and 🤗 Transformers.
Transformer Embedder A Word Level Transformer layer based on PyTorch and 🤗 Transformers. How to use Install the library from PyPI: pip install transf
 27 Nov 20, 2022
27 Nov 20, 2022
Library for faster pinned CPU <-> GPU transfer in Pytorch
SpeedTorch Faster pinned CPU tensor - GPU Pytorch variabe transfer and GPU tensor - GPU Pytorch variable transfer, in certain cases. Update 9-29-1
 657 Dec 19, 2022
657 Dec 19, 2022
SPRING is a seq2seq model for Text-to-AMR and AMR-to-Text (AAAI2021).
SPRING This is the repo for SPRING (Symmetric ParsIng aNd Generation), a novel approach to semantic parsing and generation, presented at AAAI 2021. Wi
 98 Dec 21, 2022
98 Dec 21, 2022
Code for our paper "Transfer Learning for Sequence Generation: from Single-source to Multi-source" in ACL 2021.
TRICE: a task-agnostic transferring framework for multi-source sequence generation This is the source code of our work Transfer Learning for Sequence
 9 Jun 27, 2022
9 Jun 27, 2022

BERT score for text generation
BERTScore Automatic Evaluation Metric described in the paper BERTScore: Evaluating Text Generation with BERT (ICLR 2020). News: Features to appear in
 1k Jan 08, 2023
1k Jan 08, 2023
Unified MultiWOZ evaluation scripts for the context-to-response task.
MultiWOZ Context-to-Response Evaluation Standardized and easy to use Inform, Success, BLEU ~ See the paper ~ Easy-to-use scripts for standardized eval
 38 Dec 13, 2022
38 Dec 13, 2022
Unsupervised text tokenizer focused on computational efficiency
YouTokenToMe YouTokenToMe is an unsupervised text tokenizer focused on computational efficiency. It currently implements fast Byte Pair Encoding (BPE)
 847 Dec 19, 2022
847 Dec 19, 2022