418 Repositories
Latest Python Libraries
Trained T5 and T5-large model for creating keywords from text
text to keywords Trained T5-base and T5-large model for creating keywords from text. Supported languages: ru Pretraining Large version | Pretraining B
 61 Nov 24, 2022
61 Nov 24, 2022
机器学习、深度学习、自然语言处理等人工智能基础知识总结。
说明 机器学习、深度学习、自然语言处理基础知识总结。 目前主要参考李航老师的《统计学习方法》一书,也有一些内容例如XGBoost、聚类、深度学习相关内容、NLP相关内容等是书中未提及的。
 445 Dec 12, 2022
445 Dec 12, 2022
中文空间语义理解评测
中文空间语义理解评测 最新消息 2021-04-10 🚩 排行榜发布: Leaderboard 2021-04-05 基线系统发布: SpaCE2021-Baseline 2021-04-05 开放数据提交: 提交结果 2021-04-01 开放报名: 我要报名 2021-04-01 数据集 pa
 40 Jan 04, 2023
40 Jan 04, 2023

Official Code For TDEER: An Efficient Translating Decoding Schema for Joint Extraction of Entities and Relations (EMNLP2021)
TDEER 🦌 🦒 Official Code For TDEER: An Efficient Translating Decoding Schema for Joint Extraction of Entities and Relations (EMNLP2021) Overview TDEE
 33 Dec 23, 2022
33 Dec 23, 2022
Huggingface Transformers + Adapters = ❤️
adapter-transformers A friendly fork of HuggingFace's Transformers, adding Adapters to PyTorch language models adapter-transformers is an extension of
 1.2k Jan 09, 2023
1.2k Jan 09, 2023
Research code for "What to Pre-Train on? Efficient Intermediate Task Selection", EMNLP 2021
efficient-task-transfer This repository contains code for the experiments in our paper "What to Pre-Train on? Efficient Intermediate Task Selection".
26 Dec 24, 2022

Quick insights from Zoom meeting transcripts using Graph + NLP
Transcript Analysis - Graph + NLP This program extracts insights from Zoom Meeting Transcripts (.vtt) using TigerGraph and NLTK. In order to run this
 7 Sep 17, 2022
7 Sep 17, 2022
A curated list of awesome resources related to Semantic Search🔎 and Semantic Similarity tasks.
A curated list of awesome resources related to Semantic Search🔎 and Semantic Similarity tasks.
 224 Jan 04, 2023
224 Jan 04, 2023

Conversational text Analysis using various NLP techniques
PyConverse Let me try first Installation pip install pyconverse Usage Please try this notebook that demos the core functionalities: basic usage noteb
 158 Dec 25, 2022
158 Dec 25, 2022

Multilingual word vectors in 78 languages
Aligning the fastText vectors of 78 languages Facebook recently open-sourced word vectors in 89 languages. However these vectors are monolingual; mean
 1.2k Dec 17, 2022
1.2k Dec 17, 2022
Blue Brain text mining toolbox for semantic search and structured information extraction
Blue Brain Search Source Code DOI Data & Models DOI Documentation Latest Release Python Versions License Build Status Static Typing Code Style Securit
 29 Dec 01, 2022
29 Dec 01, 2022
Kashgari is a production-level NLP Transfer learning framework built on top of tf.keras for text-labeling and text-classification, includes Word2Vec, BERT, and GPT2 Language Embedding.
Kashgari Overview | Performance | Installation | Documentation | Contributing 🎉 🎉 🎉 We released the 2.0.0 version with TF2 Support. 🎉 🎉 🎉 If you
 2.3k Dec 29, 2022
2.3k Dec 29, 2022

DataCLUE: 国内首个以数据为中心的AI测评(含模型分析报告)
DataCLUE 以数据为中心的AI测评(DataCLUE) DataCLUE: A Chinese Data-centric Language Evaluation Benchmark 内容导引 章节 描述 简介 介绍以数据为中心的AI测评(DataCLUE)的背景 任务描述 任务描述 实验结果
 135 Dec 22, 2022
135 Dec 22, 2022
WikiPron - a command-line tool and Python API for mining multilingual pronunciation data from Wiktionary
WikiPron WikiPron is a command-line tool and Python API for mining multilingual pronunciation data from Wiktionary, as well as a database of pronuncia
 213 Jan 01, 2023
213 Jan 01, 2023

A Partition Filter Network for Joint Entity and Relation Extraction EMNLP 2021
EMNLP 2021 - A Partition Filter Network for Joint Entity and Relation Extraction
 127 Jan 04, 2023
127 Jan 04, 2023
Pytorch implementations of various Deep NLP models in cs-224n(Stanford Univ)
DeepNLP-models-Pytorch Pytorch implementations of various Deep NLP models in cs-224n(Stanford Univ: NLP with Deep Learning) This is not for Pytorch be
 2.9k Dec 24, 2022
2.9k Dec 24, 2022

Pytorch implementation of "Get To The Point: Summarization with Pointer-Generator Networks"
About this repository This repo contains an Pytorch implementation for the ACL 2017 paper Get To The Point: Summarization with Pointer-Generator Netwo
 7 Oct 14, 2022
7 Oct 14, 2022
Deep learning for NLP crash course at ABBYY.
Deep NLP Course at ABBYY Deep learning for NLP crash course at ABBYY. Suggested textbook: Neural Network Methods in Natural Language Processing by Yoa
 597 Dec 18, 2022
597 Dec 18, 2022

Image Captioning using CNN and Transformers
Image-Captioning Keras/Tensorflow Image Captioning application using CNN and Transformer as encoder/decoder. In particulary, the architecture consists
 24 Dec 28, 2022
24 Dec 28, 2022
A simple Streamlit App to classify swahili news into different categories.
Swahili News Classifier Streamlit App A simple app to classify swahili news into different categories. Installation Install all streamlit requirements
 4 May 01, 2022
4 May 01, 2022
DELTA is a deep learning based natural language and speech processing platform.
DELTA - A DEep learning Language Technology plAtform What is DELTA? DELTA is a deep learning based end-to-end natural language and speech processing p
 1.5k Dec 26, 2022
1.5k Dec 26, 2022

Python implementation of TextRank for phrase extraction and summarization of text documents
PyTextRank PyTextRank is a Python implementation of TextRank as a spaCy pipeline extension, used to: extract the top-ranked phrases from text document
 1.9k Jan 06, 2023
1.9k Jan 06, 2023
This is a Prototype of an Ai ChatBot "Tea and Coffee Supplier" using python.
Ai-ChatBot-Python A chatbot is an intelligent system which can hold a conversation with a human using natural language in real time. Due to the rise o
 1 Oct 30, 2021
1 Oct 30, 2021
🍊 PAUSE (Positive and Annealed Unlabeled Sentence Embedding), accepted by EMNLP'2021 🌴
PAUSE: Positive and Annealed Unlabeled Sentence Embedding Sentence embedding refers to a set of effective and versatile techniques for converting raw
 21 Dec 15, 2022
21 Dec 15, 2022

Anuvada: Interpretable Models for NLP using PyTorch
Anuvada: Interpretable Models for NLP using PyTorch So, you want to know why your classifier arrived at a particular decision or why your flashy new d
 102 Oct 01, 2022
102 Oct 01, 2022

FairyTailor: Multimodal Generative Framework for Storytelling
FairyTailor: Multimodal Generative Framework for Storytelling
 172 Dec 30, 2022
172 Dec 30, 2022

FedNLP: A Benchmarking Framework for Federated Learning in Natural Language Processing
FedNLP is a research-oriented benchmarking framework for advancing federated learning (FL) in natural language processing (NLP). It uses FedML repository as the git submodule. In other words, FedNLP
 216 Nov 27, 2022
216 Nov 27, 2022
Named-entity recognition using neural networks. Easy-to-use and state-of-the-art results.
NeuroNER NeuroNER is a program that performs named-entity recognition (NER). Website: neuroner.com. This page gives step-by-step instructions to insta
 1.6k Dec 27, 2022
1.6k Dec 27, 2022
Solución al reto BBVA Contigo, Hack BBVA 2021
Solution Solución propuesta para el reto BBVA Contigo del Hackathon BBVA 2021. Equipo Mexdapy. Integrantes: David Pedroza Segoviano Regina Priscila Ba
 2 Dec 06, 2021
2 Dec 06, 2021

Two-stage text summarization with BERT and BART
Two-Stage Text Summarization Description We experiment with a 2-stage summarization model on CNN/DailyMail dataset that combines the ability to filter
 6 Oct 22, 2022
6 Oct 22, 2022
Load What You Need: Smaller Multilingual Transformers for Pytorch and TensorFlow 2.0.
Smaller Multilingual Transformers This repository shares smaller versions of multilingual transformers that keep the same representations offered by t
 79 Dec 28, 2022
79 Dec 28, 2022
TextDescriptives - A Python library for calculating a large variety of statistics from text
A Python library for calculating a large variety of statistics from text(s) using spaCy v.3 pipeline components and extensions. TextDescriptives can be used to calculate several descriptive statistic
 150 Dec 30, 2022
150 Dec 30, 2022

A text augmentation tool for named entity recognition.
neraug This python library helps you with augmenting text data for named entity recognition. Augmentation Example Reference from An Analysis of Simple
 48 Oct 11, 2022
48 Oct 11, 2022

Keras implementation of "One pixel attack for fooling deep neural networks" using differential evolution on Cifar10 and ImageNet
One Pixel Attack How simple is it to cause a deep neural network to misclassify an image if an attacker is only allowed to modify the color of one pix
 1.2k Dec 26, 2022
1.2k Dec 26, 2022
Blackstone is a spaCy model and library for processing long-form, unstructured legal text
Blackstone Blackstone is a spaCy model and library for processing long-form, unstructured legal text. Blackstone is an experimental research project f
 579 Jan 08, 2023
579 Jan 08, 2023
A model library for exploring state-of-the-art deep learning topologies and techniques for optimizing Natural Language Processing neural networks
A Deep Learning NLP/NLU library by Intel® AI Lab Overview | Models | Installation | Examples | Documentation | Tutorials | Contributing NLP Architect
 2.9k Jan 02, 2023
2.9k Jan 02, 2023
NLP Text Classification
多标签文本分类任务 近年来随着深度学习的发展,模型参数的数量飞速增长。为了训练这些参数,需要更大的数据集来避免过拟合。然而,对于大部分NLP任务来说,构建大规模的标注数据集非常困难(成本过高),特别是对于句法和语义相关的任务。相比之下,大规模的未标注语料库的构建则相对容易。为了利用这些数据,我们可以
 1 Nov 11, 2021
1 Nov 11, 2021
A Chinese to English Neural Model Translation Project
ZH-EN NMT Chinese to English Neural Machine Translation This project is inspired by Stanford's CS224N NMT Project Dataset used in this project: News C
 29 Nov 26, 2022
29 Nov 26, 2022
A Chinese to English Neural Model Translation Project
ZH-EN NMT Chinese to English Neural Machine Translation This project is inspired by Stanford's CS224N NMT Project Dataset used in this project: News C
29 Nov 26, 2022

Beautiful visualizations of how language differs among document types.
Scattertext 0.1.0.0 A tool for finding distinguishing terms in corpora and displaying them in an interactive HTML scatter plot. Points corresponding t
 2k Dec 27, 2022
2k Dec 27, 2022

⛵️The official PyTorch implementation for "BERT-of-Theseus: Compressing BERT by Progressive Module Replacing" (EMNLP 2020).
BERT-of-Theseus Code for paper "BERT-of-Theseus: Compressing BERT by Progressive Module Replacing". BERT-of-Theseus is a new compressed BERT by progre
 284 Nov 25, 2022
284 Nov 25, 2022
State of the Art Natural Language Processing
Spark NLP: State of the Art Natural Language Processing Spark NLP is a Natural Language Processing library built on top of Apache Spark ML. It provide
 3k Jan 05, 2023
3k Jan 05, 2023

🛠️ Tools for Transformers compression using Lightning ⚡
Bert-squeeze is a repository aiming to provide code to reduce the size of Transformer-based models or decrease their latency at inference time.
 66 Dec 11, 2022
66 Dec 11, 2022

Türkçe küfürlü içerikleri bulan bir yapay zeka kütüphanesi / An ML library for profanity detection in Turkish sentences
"Kötü söz sahibine aittir." -Anonim Nedir? sinkaf uygunsuz yorumların bulunmasını sağlayan bir python kütüphanesidir. Farkı nedir? Diğer algoritmalard
 4 Feb 18, 2022
4 Feb 18, 2022

In this project, we aim to achieve the task of predicting emojis from tweets. We aim to investigate the relationship between words and emojis.
Making Emojis More Predictable by Karan Abrol, Karanjot Singh and Pritish Wadhwa, Natural Language Processing (CSE546) under the guidance of Dr. Shad
 2 Jan 17, 2022
2 Jan 17, 2022
Augmenty is an augmentation library based on spaCy for augmenting texts.
Augmenty: The cherry on top of your NLP pipeline Augmenty is an augmentation library based on spaCy for augmenting texts. Besides a wide array of high
 124 Dec 29, 2022
124 Dec 29, 2022
spaCy-wrap: For Wrapping fine-tuned transformers in spaCy pipelines
spaCy-wrap: For Wrapping fine-tuned transformers in spaCy pipelines spaCy-wrap is minimal library intended for wrapping fine-tuned transformers from t
32 Dec 29, 2022
In this Notebook I've build some machine-learning and deep-learning to classify corona virus tweets, in both multi class classification and binary classification.
Hello, This Notebook Contains Example of Corona Virus Tweets Multi Class Classification. - Classes is: Extremely Positive, Positive, Extremely Negativ
 3 Dec 06, 2022
3 Dec 06, 2022

⚡ boost inference speed of T5 models by 5x & reduce the model size by 3x using fastT5.
Reduce T5 model size by 3X and increase the inference speed up to 5X. Install Usage Details Functionalities Benchmarks Onnx model Quantized onnx model
 399 Jan 05, 2023
399 Jan 05, 2023

MILES is a multilingual text simplifier inspired by LSBert - A BERT-based lexical simplification approach proposed in 2018. Unlike LSBert, MILES uses the bert-base-multilingual-uncased model, as well as simple language-agnostic approaches to complex word identification (CWI) and candidate ranking.
MILES Multilingual Lexical Simplifier Explore the docs » Read LSBert Paper · Report Bug · Request Feature About The Project MILES is a multilingual te
 45 Oct 19, 2022
45 Oct 19, 2022
中文无监督SimCSE Pytorch实现
A PyTorch implementation of unsupervised SimCSE SimCSE: Simple Contrastive Learning of Sentence Embeddings 1. 用法 无监督训练 python train_unsup.py ./data/ne
 99 Dec 23, 2022
99 Dec 23, 2022
A PyTorch implementation of unsupervised SimCSE
A PyTorch implementation of unsupervised SimCSE
99 Dec 23, 2022
A fast and easy implementation of Transformer with PyTorch.
FasySeq FasySeq is a shorthand as a Fast and easy sequential modeling toolkit. It aims to provide a seq2seq model to researchers and developers, which
 7 Jul 18, 2022
7 Jul 18, 2022
Code for our ACL 2021 (Findings) Paper - Fingerprinting Fine-tuned Language Models in the wild .
🌳 Fingerprinting Fine-tuned Language Models in the wild This is the code and dataset for our ACL 2021 (Findings) Paper - Fingerprinting Fine-tuned La
 5 Sep 13, 2022
5 Sep 13, 2022
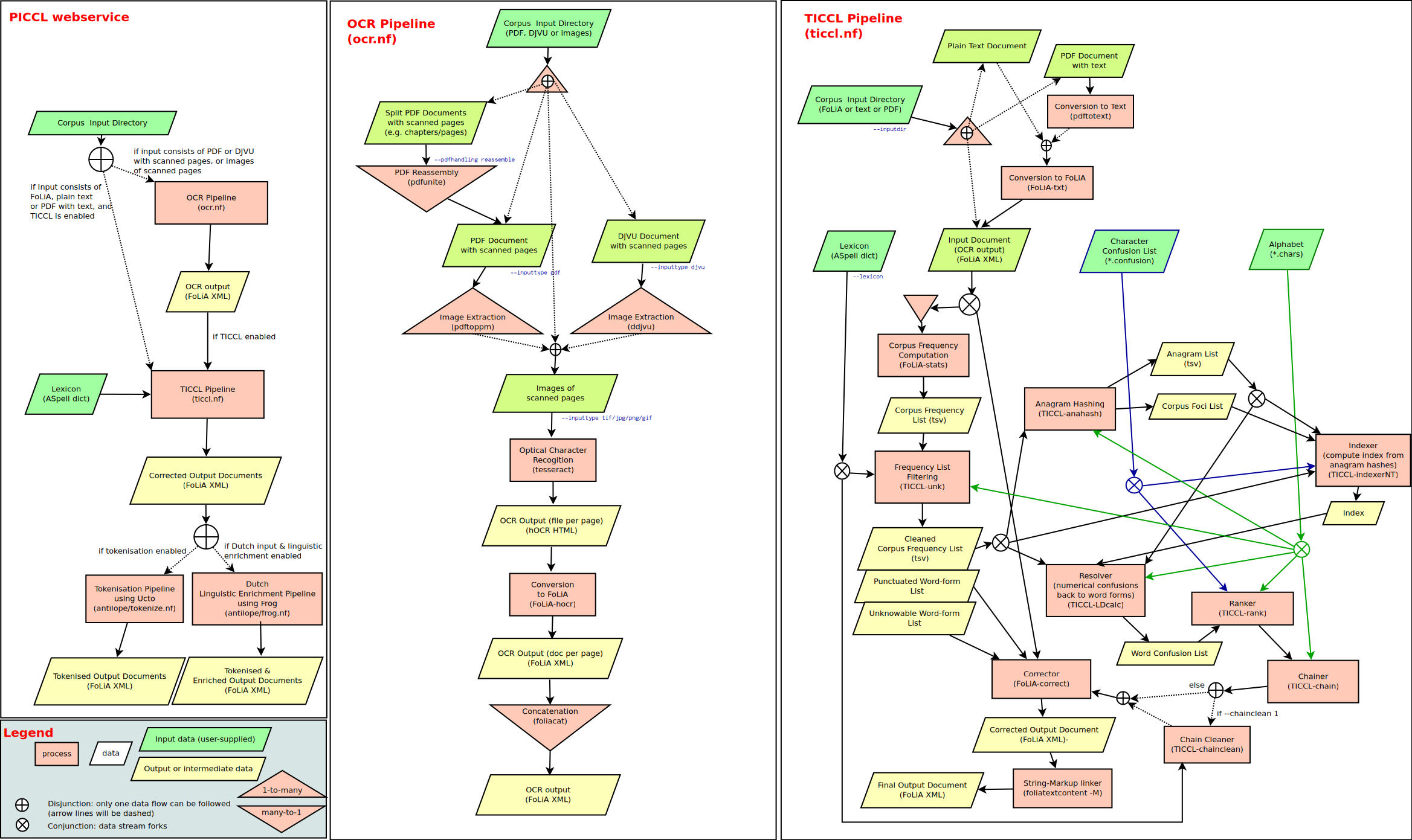
A set of workflows for corpus building through OCR, post-correction and normalisation
PICCL: Philosophical Integrator of Computational and Corpus Libraries PICCL offers a workflow for corpus building and builds on a variety of tools. Th
 41 Dec 27, 2022
41 Dec 27, 2022
Train 🤗-transformers model with Poutyne.
poutyne-transformers Train 🤗 -transformers models with Poutyne. Installation pip install poutyne-transformers Example import torch from transformers
 2 Dec 18, 2022
2 Dec 18, 2022

Search-Engine - 📖 AI based search engine
Search Engine AI based search engine that was trained on 25000 samples, feel free to train on up to 1.2M sample from kaggle dataset, link below StackS
 2 Nov 29, 2022
2 Nov 29, 2022

Release of SPLASH: Dataset for semantic parse correction with natural language feedback in the context of text-to-SQL parsing
SPLASH: Semantic Parsing with Language Assistance from Humans SPLASH is dataset for the task of semantic parse correction with natural language feedba
 35 Oct 31, 2022
35 Oct 31, 2022
BERTopic is a topic modeling technique that leverages 🤗 transformers and c-TF-IDF to create dense clusters allowing for easily interpretable topics whilst keeping important words in the topic descriptions
BERTopic BERTopic is a topic modeling technique that leverages 🤗 transformers and c-TF-IDF to create dense clusters allowing for easily interpretable
 3.6k Jan 07, 2023
3.6k Jan 07, 2023
Concept Modeling: Topic Modeling on Images and Text
Concept is a technique that leverages CLIP and BERTopic-based techniques to perform Concept Modeling on images.
120 Dec 27, 2022