多标签文本分类任务
近年来随着深度学习的发展,模型参数的数量飞速增长。为了训练这些参数,需要更大的数据集来避免过拟合。然而,对于大部分NLP任务来说,构建大规模的标注数据集非常困难(成本过高),特别是对于句法和语义相关的任务。相比之下,大规模的未标注语料库的构建则相对容易。为了利用这些数据,我们可以先从其中学习到一个好的表示,再将这些表示应用到其他任务中。最近的研究表明,基于大规模未标注语料库的预训练模型(Pretrained Models, PTM) 在NLP任务上取得了很好的表现。
大量的研究表明基于大型语料库的预训练模型(Pretrained Models, PTM)可以学习通用的语言表示,有利于下游NLP任务,同时能够避免从零开始训练模型。随着计算能力的发展,深度模型的出现(即 Transformer)和训练技巧的增强使得 PTM 不断发展,由浅变深。
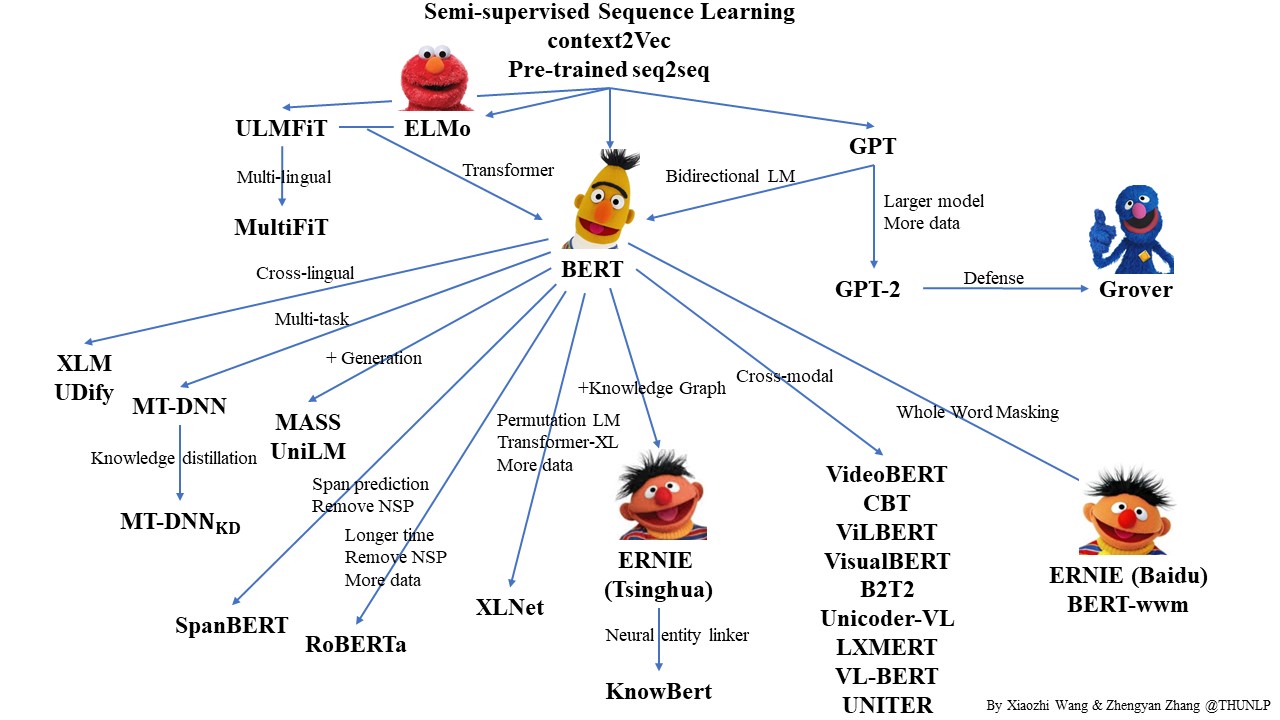
本图片来自于:https://github.com/thunlp/PLMpapers
本示例展示了如何以BERT(Bidirectional Encoder Representations from Transformers)预训练模型Finetune完成多标签文本分类任务。
快速开始
代码结构说明
以下是本项目主要代码结构及说明:
pretrained_models/
├── deploy # 部署
│ └── python
│ └── predict.py # python预测部署示例
├── export_model.py # 动态图参数导出静态图参数脚本
├── predict.py # 预测脚本
├── README.md # 使用说明
├── data.py # 数据处理
├── metric.py # 指标计算
├── model.py # 模型网络
└── train.py # 训练评估脚本
数据准备
从Kaggle下载Toxic Comment Classification Challenge数据集并将数据集文件放在./data路径下。 以下是./data路径的文件组成:
data/
├── sample_submission.csv # 预测结果提交样例
├── train.csv # 训练集
├── test.csv # 测试集
└── test_labels.csv # 测试数据标签,数值-1代表该条数据不参与打分
模型训练
我们以Kaggle Toxic Comment Classification Challenge为示例数据集,可以运行下面的命令,在训练集(train.tsv)上进行模型训练
unset CUDA_VISIBLE_DEVICES
python -m paddle.distributed.launch --gpus "0" train.py --device gpu --save_dir ./checkpoints
可支持配置的参数:
save_dir:可选,保存训练模型的目录;默认保存在当前目录checkpoints文件夹下。max_seq_length:可选,BERT模型使用的最大序列长度,最大不能超过512, 若出现显存不足,请适当调低这一参数;默认为128。batch_size:可选,批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为32。learning_rate:可选,Fine-tune的最大学习率;默认为5e-5。weight_decay:可选,控制正则项力度的参数,用于防止过拟合,默认为0.0。epochs: 训练轮次,默认为3。warmup_proption:可选,学习率warmup策略的比例,如果0.1,则学习率会在前10%训练step的过程中从0慢慢增长到learning_rate, 而后再缓慢衰减,默认为0.0。init_from_ckpt:可选,模型参数路径,热启动模型训练;默认为None。seed:可选,随机种子,默认为1000。device: 选用什么设备进行训练,可选cpu或gpu。如使用gpu训练则参数gpus指定GPU卡号。data_path: 可选,数据集文件路径,默认数据集存放在当前目录data文件夹下。
代码示例中使用的预训练模型是BERT,如果想要使用其他预训练模型如ERNIE等,只需要更换model和tokenizer即可。
程序运行时将会自动进行训练,评估。同时训练过程中会自动保存模型在指定的save_dir中。 如:
checkpoints/
├── model_100
│ ├── model_state.pdparams
│ ├── tokenizer_config.json
│ └── vocab.txt
└── ...
NOTE:
- 如需恢复模型训练,则可以设置
init_from_ckpt,如init_from_ckpt=checkpoints/model_100/model_state.pdparams。 - 使用动态图训练结束之后,还可以将动态图参数导出成静态图参数,具体代码见export_model.py。静态图参数保存在
output_path指定路径中。 运行方式:
python export_model.py --params_path=./checkpoints/model_1000/model_state.pdparams --output_path=./static_graph_params
其中params_path是指动态图训练保存的参数路径,output_path是指静态图参数导出路径。
导出模型之后,可以用于部署,deploy/python/predict.py文件提供了python部署预测示例。
NOTE:
- 可通过
threshold参数调整最终预测结果,当预测概率值大于threshold时预测结果为1,否则为0;默认为0.5。 运行方式:
python deploy/python/predict.py --model_file=static_graph_params.pdmodel --params_file=static_graph_params.pdiparams
待预测数据如以下示例:
Your bullshit is not welcome here.
Thank you for understanding. I think very highly of you and would not revert without discussion.
预测结果示例:
Data: Your bullshit is not welcome here.
toxic: 1
severe_toxic: 0
obscene: 0
threat: 0
insult: 0
identity_hate: 0
Data: Thank you for understanding. I think very highly of you and would not revert without discussion.
toxic: 0
severe_toxic: 0
obscene: 0
threat: 0
insult: 0
identity_hate: 0
模型预测
启动预测:
export CUDA_VISIBLE_DEVICES=0
python predict.py --device 'gpu' --params_path checkpoints/model_1000/model_state.pdparams
预测结果会以csv文件sample_test.csv保存在当前目录下。

 40 Nov 30, 2022
40 Nov 30, 2022
 19 Oct 28, 2022
19 Oct 28, 2022
 1 Nov 18, 2021
1 Nov 18, 2021
 14 Nov 24, 2022
14 Nov 24, 2022
 9 Dec 28, 2022
9 Dec 28, 2022
 27 Nov 20, 2022
27 Nov 20, 2022
 1.2k Dec 17, 2022
1.2k Dec 17, 2022
 94 Dec 26, 2022
94 Dec 26, 2022
 2 Jan 18, 2022
2 Jan 18, 2022
 1 Dec 17, 2021
1 Dec 17, 2021
 216 Dec 22, 2022
216 Dec 22, 2022
 1.2k Dec 26, 2022
1.2k Dec 26, 2022
 8 Dec 22, 2022
8 Dec 22, 2022
 41 Dec 27, 2022
41 Dec 27, 2022
 9.7k Jan 09, 2023
9.7k Jan 09, 2023
 1 Mar 11, 2022
1 Mar 11, 2022
 1 Jan 31, 2022
1 Jan 31, 2022
 375 Dec 28, 2022
375 Dec 28, 2022
 1 Dec 30, 2021
1 Dec 30, 2021
 2 Feb 02, 2022
2 Feb 02, 2022