72 Repositories
Latest Python Libraries
Arabic speech recognition, classification and text-to-speech.
klaam Arabic speech recognition, classification and text-to-speech using many advanced models like wave2vec and fastspeech2. This repository allows tr
 177 Dec 27, 2022
177 Dec 27, 2022

A python gui program to generate reddit text to speech videos from the id of any post.
Reddit text to speech generator A python gui program to generate reddit text to speech videos from the id of any post. Current functionality Generate
 17 Dec 19, 2022
17 Dec 19, 2022
Refactored version of FastSpeech2
Refactored version of FastSpeech2. An implementation of Microsoft's "FastSpeech 2: Fast and High-Quality End-to-End Text to Speech"
 10 May 26, 2022
10 May 26, 2022

A Python/Pytorch app for easily synthesising human voices
Voice Cloning App A Python/Pytorch app for easily synthesising human voices Documentation Discord Server Video guide Voice Sharing Hub FAQ's System Re
 840 Jan 04, 2023
840 Jan 04, 2023

Unet-TTS: Improving Unseen Speaker and Style Transfer in One-shot Voice Cloning
Unet-TTS: Improving Unseen Speaker and Style Transfer in One-shot Voice Cloning English | 中文 ❗ Now we provide inferencing code and pre-training models
 164 Jan 02, 2023
164 Jan 02, 2023
Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis (SV2TTS)
This repository is an implementation of Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis (SV2TTS) with a vocoder that works in real-time. Feel free to check my the
 38.5k Jan 03, 2023
38.5k Jan 03, 2023
YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for everyone
YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for everyone In our recent paper we propose the YourTTS model. YourTTS bri
 390 Dec 29, 2022
390 Dec 29, 2022
Official implementation of Meta-StyleSpeech and StyleSpeech
Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation Dongchan Min, Dong Bok Lee, Eunho Yang, and Sung Ju Hwang This is an official code
 169 Jan 05, 2023
169 Jan 05, 2023
Official implementation of Meta-StyleSpeech and StyleSpeech
Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation Dongchan Min, Dong Bok Lee, Eunho Yang, and Sung Ju Hwang This is an official code
168 Dec 28, 2022

Chinese real time voice cloning (VC) and Chinese text to speech (TTS).
Chinese real time voice cloning (VC) and Chinese text to speech (TTS). 好用的中文语音克隆兼中文语音合成系统,包含语音编码器、语音合成器、声码器和可视化模块。
 6 Nov 08, 2022
6 Nov 08, 2022

DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism (SVS & TTS); AAAI 2022
DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism This repository is the official PyTorch implementation of our AAAI-2022 paper, in
 829 Jan 07, 2023
829 Jan 07, 2023
DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism (SVS & TTS); AAAI 2022; Official code
DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism This repository is the official PyTorch implementation of our AAAI-2022 paper, in
803 Dec 28, 2022
Azure Neural Speech Service TTS
Written in Python using the Azure Speech SDK. App.py provides an easy way to create an Text-To-Speech request to Azure Speech and download the wav file.
 1 Oct 11, 2021
1 Oct 11, 2021
A Python module made to simplify the usage of Text To Speech and Speech Recognition.
Nav Module The solution for voice related stuff in Python Nav is a Python module which simplifies voice related stuff in Python. Just import the Modul
 1 Dec 20, 2021
1 Dec 20, 2021
TensorFlowTTS: Real-Time State-of-the-art Speech Synthesis for Tensorflow 2 (supported including English, Korean, Chinese, German and Easy to adapt for other languages)
🤪 TensorFlowTTS provides real-time state-of-the-art speech synthesis architectures such as Tacotron-2, Melgan, Multiband-Melgan, FastSpeech, FastSpeech2 based-on TensorFlow 2. With Tensorflow 2, we c
 3k Jan 04, 2023
3k Jan 04, 2023

Official implementation of FCL-taco2: Fast, Controllable and Lightweight version of Tacotron2 @ ICASSP 2021
FCL-Taco2: Towards Fast, Controllable and Lightweight Text-to-Speech synthesis (ICASSP 2021) Paper | Demo Block diagram of FCL-taco2, where the decode
 39 Sep 28, 2022
39 Sep 28, 2022
Parallel TTS web demo based on Flask + Vue (Vuetify).
Parallel TTS web demo based on Flask + Vue (Vuetify).
 34 Dec 16, 2022
34 Dec 16, 2022
A fast Text-to-Speech (TTS) model. Work well for English, Mandarin/Chinese, Japanese, Korean, Russian and Tibetan (so far). 快速语音合成模型,适用于英语、普通话/中文、日语、韩语、俄语和藏语(当前已测试)。
简体中文 | English 并行语音合成 [TOC] 新进展 2021/04/20 合并 wavegan 分支到 main 主分支,删除 wavegan 分支! 2021/04/13 创建 encoder 分支用于开发语音风格迁移模块! 2021/04/13 softdtw 分支 支持使用 Sof
161 Dec 19, 2022
vits chinese, tts chinese, tts mandarin
vits chinese, tts chinese, tts mandarin 史上训练最简单,音质最好的语音合成系统
 12 Dec 14, 2022
12 Dec 14, 2022
Finally, some decent sample sentences
tts-dataset-prompts This repository aims to be a decent set of sentences for people looking to clone their own voices (e.g. using Tacotron 2). Each se
 19 Dec 13, 2022
19 Dec 13, 2022
🗣️ Microsoft Edge TTS for Home Assistant, no need for app_key
Microsoft Edge TTS for Home Assistant This component is based on the TTS service of Microsoft Edge browser, no need to apply for app_key. Install Down
 152 Dec 31, 2022
152 Dec 31, 2022

Multispeaker & Emotional TTS based on Tacotron 2 and Waveglow
This Repository contains a sample code for Tacotron 2, WaveGlow with multi-speaker, emotion embeddings together with a script for data preprocessing.
 106 Jan 01, 2023
106 Jan 01, 2023

iSTFTNet : Fast and Lightweight Mel-spectrogram Vocoder Incorporating Inverse Short-time Fourier Transform
iSTFTNet : Fast and Lightweight Mel-spectrogram Vocoder Incorporating Inverse Short-time Fourier Transform This repo try to implement iSTFTNet : Fast
 126 Jan 02, 2023
126 Jan 02, 2023

Implementation of Google Brain's WaveGrad high-fidelity vocoder
WaveGrad Implementation (PyTorch) of Google Brain's high-fidelity WaveGrad vocoder (paper). First implementation on GitHub with high-quality generatio
 363 Dec 27, 2022
363 Dec 27, 2022

HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis Jungil Kong, Jaehyeon Kim, Jaekyoung Bae In our paper, we p
 1.1k Jan 02, 2023
1.1k Jan 02, 2023
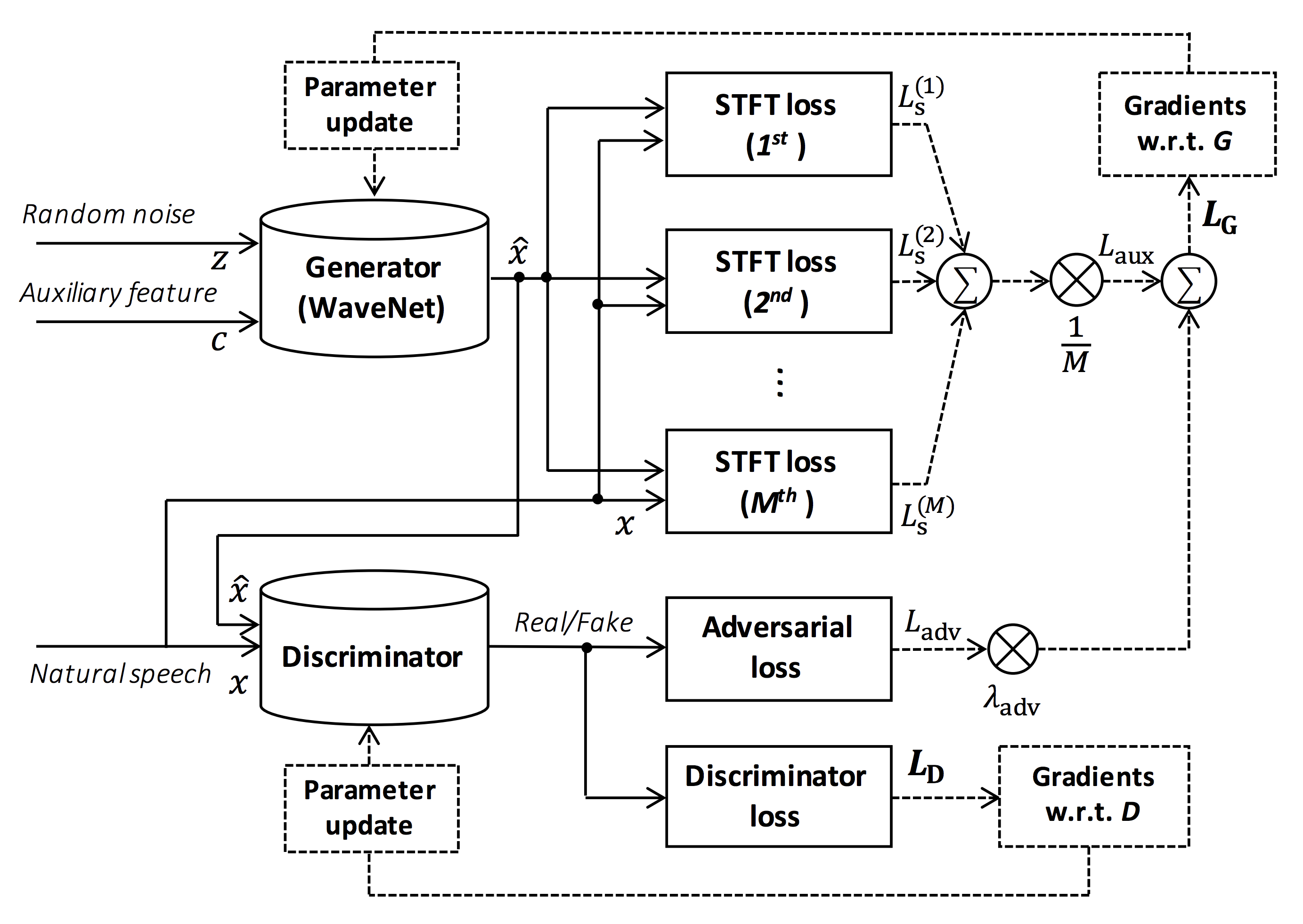
Unofficial Parallel WaveGAN (+ MelGAN & Multi-band MelGAN & HiFi-GAN & StyleMelGAN) with Pytorch
Parallel WaveGAN implementation with Pytorch This repository provides UNOFFICIAL pytorch implementations of the following models: Parallel WaveGAN Mel
 1.2k Dec 23, 2022
1.2k Dec 23, 2022

Comprehensive-E2E-TTS - PyTorch Implementation
A Non-Autoregressive End-to-End Text-to-Speech (text-to-wav), supporting a family of SOTA unsupervised duration modelings. This project grows with the research community, aiming to achieve the ultima
 114 Nov 13, 2022
114 Nov 13, 2022

A Non-Autoregressive Transformer based TTS, supporting a family of SOTA transformers with supervised and unsupervised duration modelings. This project grows with the research community, aiming to achieve the ultimate TTS.
A Non-Autoregressive Transformer based TTS, supporting a family of SOTA transformers with supervised and unsupervised duration modelings. This project grows with the research community, aiming to ach
237 Jan 02, 2023

PyTorch Implementation of ByteDance's Cross-speaker Emotion Transfer Based on Speaker Condition Layer Normalization and Semi-Supervised Training in Text-To-Speech
Cross-Speaker-Emotion-Transfer - PyTorch Implementation PyTorch Implementation of ByteDance's Cross-speaker Emotion Transfer Based on Speaker Conditio
114 Jan 08, 2023

PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis
Daft-Exprt - PyTorch Implementation PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis The
47 Dec 18, 2022
This is a template for the Non-autoregressive Deep Learning-Based TTS model (in PyTorch).
Non-autoregressive Deep Learning-Based TTS Template This is a template for the Non-autoregressive TTS model. It contains Data Preprocessing Pipeline D
13 Dec 05, 2022

PyTorch Implementation of DiffGAN-TTS: High-Fidelity and Efficient Text-to-Speech with Denoising Diffusion GANs
DiffGAN-TTS - PyTorch Implementation PyTorch implementation of DiffGAN-TTS: High
157 Jan 01, 2023

Pytorch Implementation of DiffSinger: Diffusion Acoustic Model for Singing Voice Synthesis (TTS Extension)
DiffSinger - PyTorch Implementation PyTorch implementation of DiffSinger: Diffusion Acoustic Model for Singing Voice Synthesis (TTS Extension). Status
152 Jan 02, 2023

PyTorch Implementation of NCSOFT's FastPitchFormant: Source-filter based Decomposed Modeling for Speech Synthesis
FastPitchFormant - PyTorch Implementation PyTorch Implementation of FastPitchFormant: Source-filter based Decomposed Modeling for Speech Synthesis. Qu
63 Jan 02, 2023

Pytorch Implementation of Google's Parallel Tacotron 2: A Non-Autoregressive Neural TTS Model with Differentiable Duration Modeling
Parallel Tacotron2 Pytorch Implementation of Google's Parallel Tacotron 2: A Non-Autoregressive Neural TTS Model with Differentiable Duration Modeling
170 Dec 27, 2022

PyTorch Implementation of PortaSpeech: Portable and High-Quality Generative Text-to-Speech
PortaSpeech - PyTorch Implementation PyTorch Implementation of PortaSpeech: Portable and High-Quality Generative Text-to-Speech. Model Size Module Nor
279 Jan 04, 2023
PortaSpeech - PyTorch Implementation
PortaSpeech - PyTorch Implementation PyTorch Implementation of PortaSpeech: Portable and High-Quality Generative Text-to-Speech. Model Size Module Nor
276 Dec 26, 2022

STYLER: Style Factor Modeling with Rapidity and Robustness via Speech Decomposition for Expressive and Controllable Neural Text to Speech
STYLER: Style Factor Modeling with Rapidity and Robustness via Speech Decomposition for Expressive and Controllable Neural Text to Speech Keon Lee, Ky
114 Dec 12, 2022

PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation
StyleSpeech - PyTorch Implementation PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation. Status (2021.06.09
142 Jan 06, 2023
PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation
StyleSpeech - PyTorch Implementation PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation. Status (2021.06.13
140 Dec 21, 2022

PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
VAENAR-TTS - PyTorch Implementation PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
67 Nov 14, 2022
PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
VAENAR-TTS - PyTorch Implementation PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
67 Nov 14, 2022

PyTorch Implementation of Google Brain's WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis
WaveGrad2 - PyTorch Implementation PyTorch Implementation of Google Brain's WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis. Status (202
59 Dec 06, 2022

text to speech toolkit. 好用的中文语音合成工具箱,包含语音编码器、语音合成器、声码器和可视化模块。
ttskit Text To Speech Toolkit: 语音合成工具箱。 安装 pip install -U ttskit 注意 可能需另外安装的依赖包:torch,版本要求torch=1.6.0,=1.7.1,根据自己的实际环境安装合适cuda或cpu版本的torch。 ttskit的
 483 Jan 04, 2023
483 Jan 04, 2023

Unofficial PyTorch Implementation of UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
UnivNet UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation This is an unofficial PyTorch
 170 Jan 04, 2023
170 Jan 04, 2023

Unofficial Pytorch Implementation of WaveGrad2
WaveGrad 2 — Unofficial PyTorch Implementation WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis Unofficial PyTorch+Lightning Implementati
104 Nov 29, 2022

TTS is a library for advanced Text-to-Speech generation.
TTS is a library for advanced Text-to-Speech generation. It's built on the latest research, was designed to achieve the best trade-off among ease-of-training, speed and quality. TTS comes with pretra
 6.5k Jan 08, 2023
6.5k Jan 08, 2023
A retro text-to-speech bot for Discord
hawking A retro text-to-speech bot for Discord, designed to work with all of the stuff you might've seen in Moonbase Alpha, using the existing command
 23 Dec 25, 2022
23 Dec 25, 2022
EdiTTS: Score-based Editing for Controllable Text-to-Speech
Official implementation of EdiTTS: Score-based Editing for Controllable Text-to-Speech
 99 Jan 02, 2023
99 Jan 02, 2023
Official implementation of EdiTTS: Score-based Editing for Controllable Text-to-Speech
EdiTTS: Score-based Editing for Controllable Text-to-Speech Official implementation of EdiTTS: Score-based Editing for Controllable Text-to-Speech. Au
98 Dec 25, 2022
🐤 Nix-TTS: An Incredibly Lightweight End-to-End Text-to-Speech Model via Non End-to-End Distillation
🐤 Nix-TTS An Incredibly Lightweight End-to-End Text-to-Speech Model via Non End-to-End Distillation Rendi Chevi, Radityo Eko Prasojo, Alham Fikri Aji
 156 Jan 09, 2023
156 Jan 09, 2023
Utility for Google Text-To-Speech batch audio files generator. Ideal for prompt files creation with Google voices for application in offline IVRs
Google Text-To-Speech Batch Prompt File Maker Are you in the need of IVR prompts, but you have no voice actors? Let Google talk your prompts like a pr
 1 Aug 19, 2021
1 Aug 19, 2021

PyTorch implementation of convolutional neural networks-based text-to-speech synthesis models
Deepvoice3_pytorch PyTorch implementation of convolutional networks-based text-to-speech synthesis models: arXiv:1710.07654: Deep Voice 3: Scaling Tex
 1.8k Dec 30, 2022
1.8k Dec 30, 2022
PyTorch implementation of convolutional neural networks-based text-to-speech synthesis models
Deepvoice3_pytorch PyTorch implementation of convolutional networks-based text-to-speech synthesis models: arXiv:1710.07654: Deep Voice 3: Scaling Tex
1.8k Jan 08, 2023

ttslearn: Library for Pythonで学ぶ音声合成 (Text-to-speech with Python)
ttslearn: Library for Pythonで学ぶ音声合成 (Text-to-speech with Python) 日本語は以下に続きます (Japanese follows) English: This book is written in Japanese and primaril
189 Dec 29, 2022

Chinese Mandarin tts text-to-speech 中文 (普通话) 语音 合成 , by fastspeech 2 , implemented in pytorch, using waveglow as vocoder,
Chinese mandarin text to speech based on Fastspeech2 and Unet This is a modification and adpation of fastspeech2 to mandrin(普通话). Many modifications t
 291 Jan 02, 2023
291 Jan 02, 2023
Fre-GAN: Adversarial Frequency-consistent Audio Synthesis
Fre-GAN Vocoder Fre-GAN: Adversarial Frequency-consistent Audio Synthesis Training: python train.py --config config.json Citation: @misc{kim2021frega
93 Dec 17, 2022
LightSpeech: Lightweight and Fast Text to Speech with Neural Architecture Search
LightSpeech UnOfficial PyTorch implementation of LightSpeech: Lightweight and Fast Text to Speech with Neural Architecture Search.
54 Dec 03, 2022
TalkNet 2: Non-Autoregressive Depth-Wise Separable Convolutional Model for Speech Synthesis with Explicit Pitch and Duration Prediction.
TalkNet 2 [WIP] TalkNet 2: Non-Autoregressive Depth-Wise Separable Convolutional Model for Speech Synthesis with Explicit Pitch and Duration Predictio
69 Dec 17, 2022
UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
UnivNet UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation. Training python train.py --c
55 Dec 26, 2022