

Lbl2Vec
Lbl2Vec is an algorithm for unsupervised document classification and unsupervised document retrieval. It automatically generates jointly embedded label, document and word vectors and returns documents of topics modeled by manually predefined keywords. Once you train the Lbl2Vec model you can:
- Classify documents as related to one of the predefined topics.
- Get similarity scores for documents to each predefined topic.
- Get most similar predefined topic of documents.
See the paper for more details on how it works.
Corresponding Medium post describing the use of Lbl2Vec for unsupervised text classification can be found here.
Benefits
- No need to label the whole document dataset for classification.
- No stop word lists required.
- No need for stemming/lemmatization.
- Works on short text.
- Creates jointly embedded label, document, and word vectors.
How does it work?
The key idea of the algorithm is that many semantically similar keywords can represent a topic. In the first step, the algorithm creates a joint embedding of document and word vectors. Once documents and words are embedded in a vector space, the goal of the algorithm is to learn label vectors from previously manually defined keywords representing a topic. Finally, the algorithm can predict the affiliation of documents to topics from document vector <-> label vector similarities.
The Algorithm
0. Use the manually defined keywords for each topic of interest.
Domain knowledge is needed to define keywords that describe topics and are semantically similar to each other within the topics.
| Basketball | Soccer | Baseball |
|---|---|---|
| NBA | FIFA | MLB |
| Basketball | Soccer | Baseball |
| LeBron | Messi | Ruth |
| ... | ... | ... |
1. Create jointly embedded document and word vectors using Doc2Vec.
Documents will be placed close to other similar documents and close to the most distinguishing words.

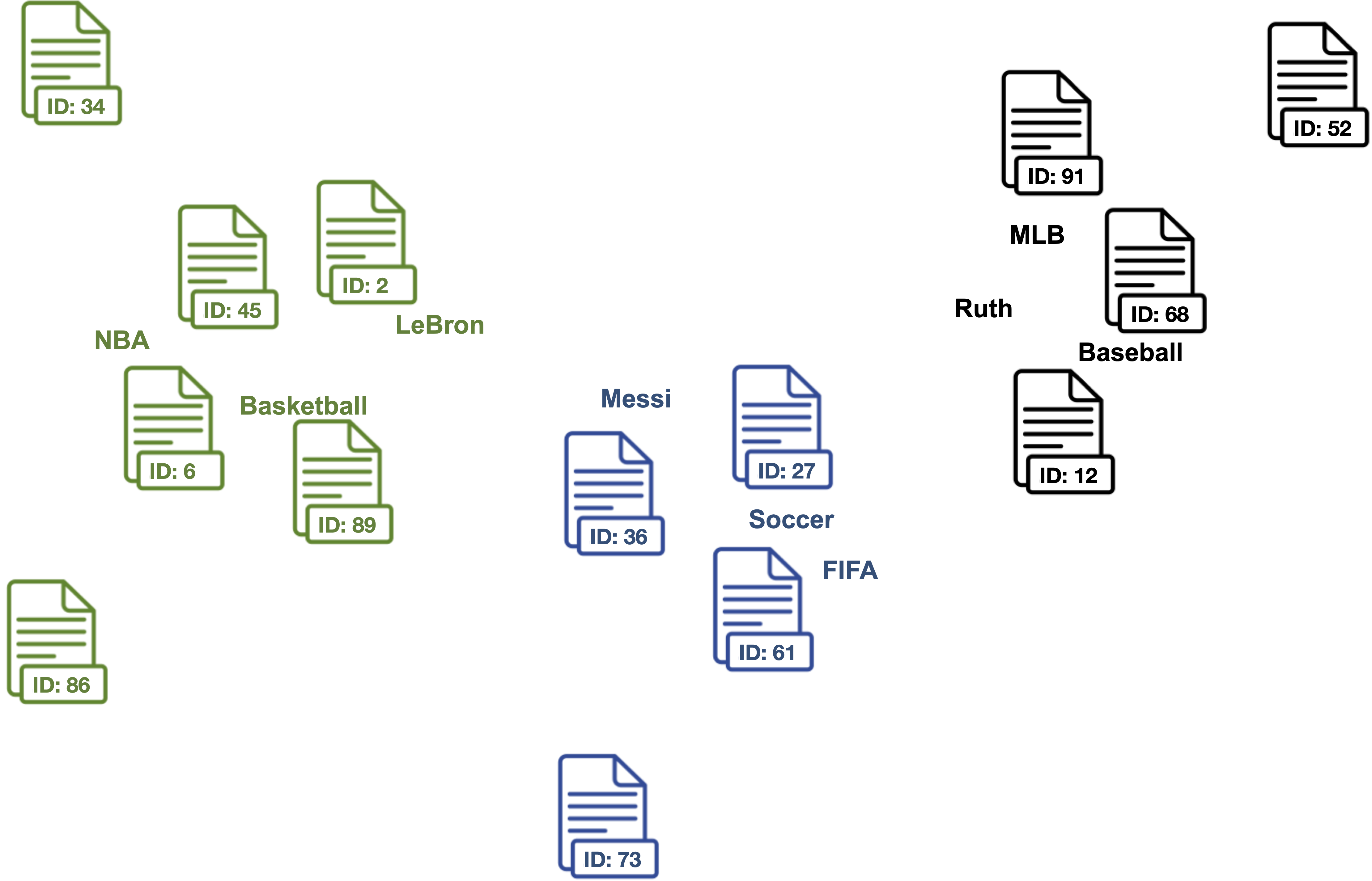
2. Find document vectors that are similar to the keyword vectors of each topic.
Each color represents a different topic described by the respective keywords.
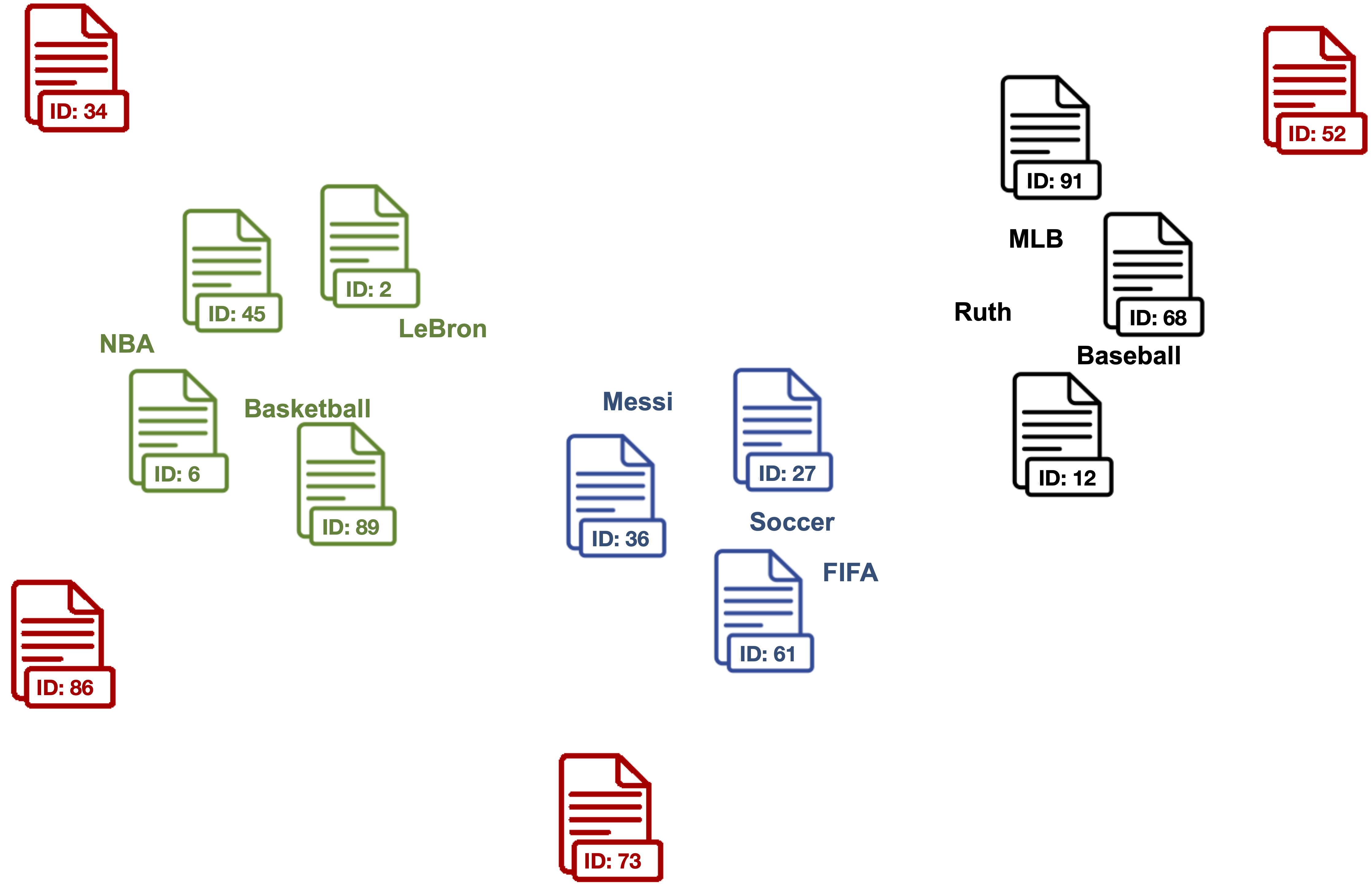
3. Clean outlier document vectors for each topic.
Red documents are outlier vectors that are removed and do not get used for calculating the label vector.
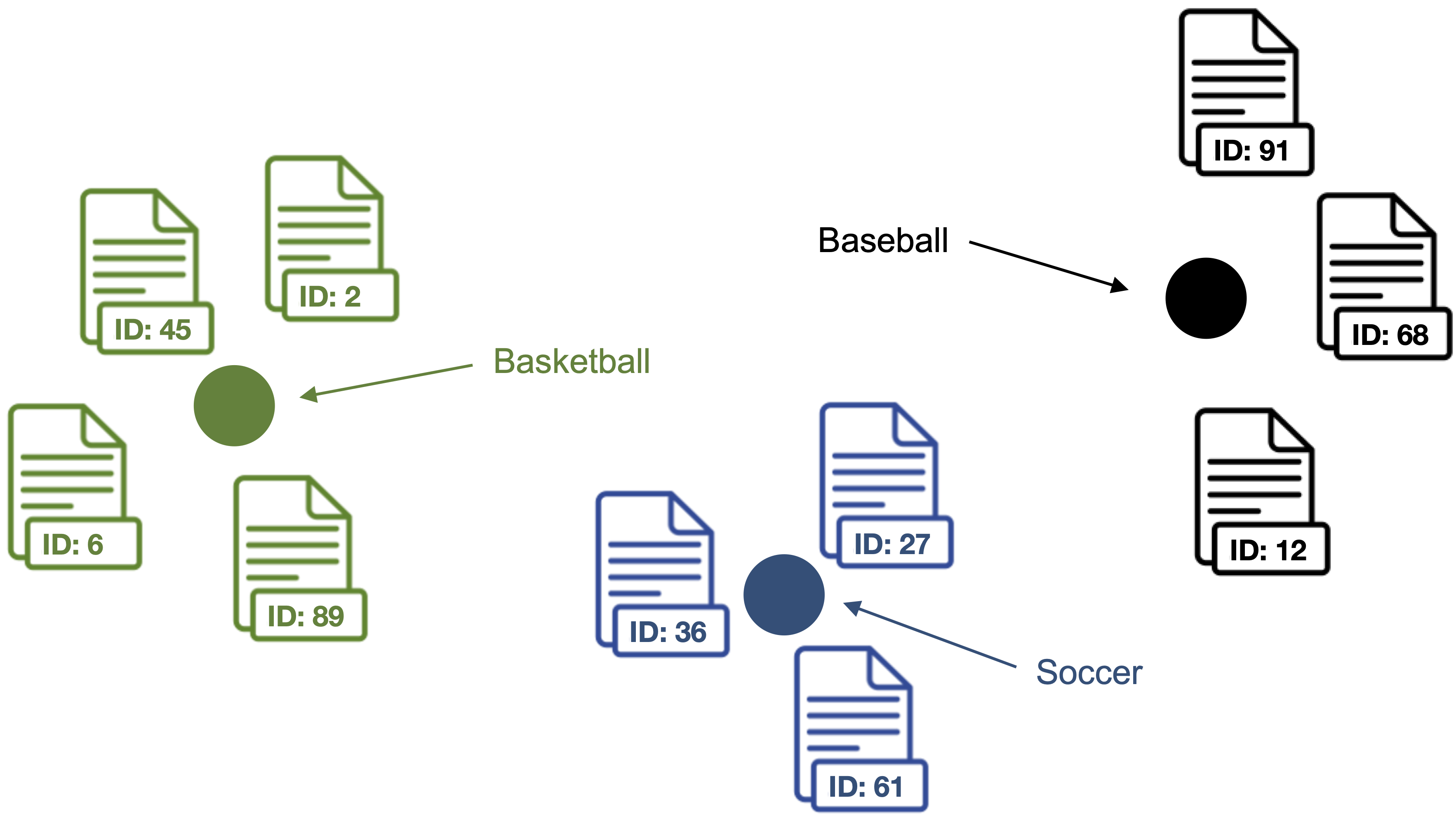
4. Compute the centroid of the outlier cleaned document vectors as label vector for each topic.
Points represent the label vectors of the respective topics.
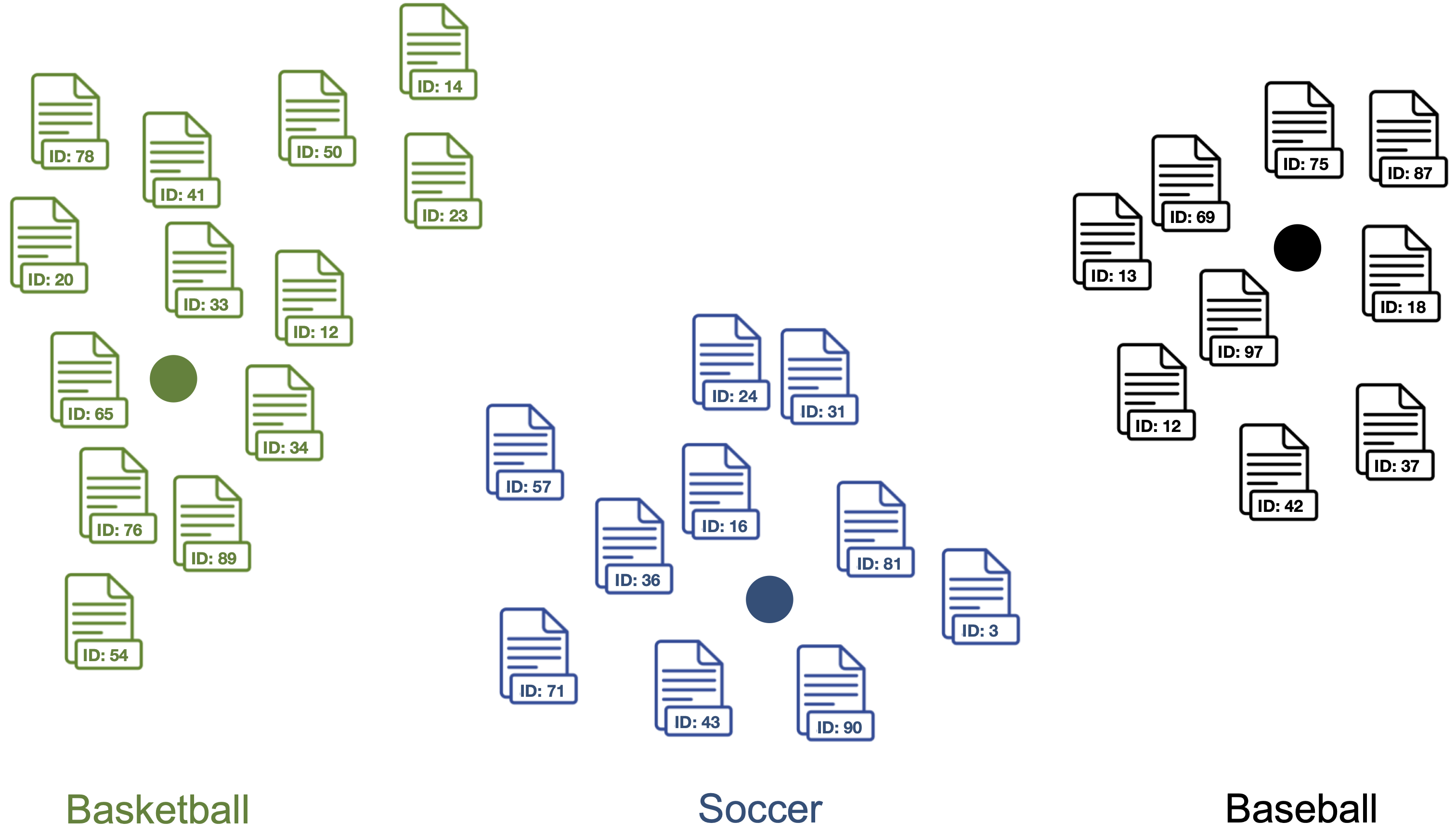
5. Compute label vector <-> document vector similarities for each label vector and document vector in the dataset.
Documents are classified as topic with the highest label vector <-> document vector similarity.
Installation
pip install lbl2vec
Usage
For detailed information visit the Lbl2Vec API Guide and the examples.
from lbl2vec import Lbl2Vec
Learn new model from scratch
Learns word vectors, document vectors and label vectors from scratch during Lbl2Vec model training.
# init model
model = Lbl2Vec(keywords_list=descriptive_keywords, tagged_documents=tagged_docs)
# train model
model.fit()
Important parameters:
keywords_list: iterable list of lists with descriptive keywords of type str. For each label at least one descriptive keyword has to be added as list of str.tagged_documents: iterable list of gensim.models.doc2vec.TaggedDocument elements. If you wish to train a new Doc2Vec model this parameter can not be None, whereas thedoc2vec_modelparameter must be None. If you use a pretrained Doc2Vec model this parameter has to be None. Input corpus, can be simply a list of elements, but for larger corpora, consider an iterable that streams the documents directly from disk/network.
Use word and document vectors from pretrained Doc2Vec model
Uses word vectors and document vectors from a pretrained Doc2Vec model to learn label vectors during Lbl2Vec model training.
# init model
model = Lbl2Vec(keywords_list=descriptive_keywords, doc2vec_model=pretrained_d2v_model)
# train model
model.fit()
Important parameters:
keywords_list: iterable list of lists with descriptive keywords of type str. For each label at least one descriptive keyword has to be added as list of str.doc2vec_model: pretrained gensim.models.doc2vec.Doc2Vec model. If given a pretrained Doc2Vec model, Lbl2Vec uses the pre-trained Doc2Vec model from this parameter. If this parameter is defined,tagged_documentsparameter has to be None. In order to get optimal Lbl2Vec results the given Doc2Vec model should be trained with the parameters "dbow_words=1" and "dm=0".
Predict label similarities for documents used for training
Computes the similarity scores for each document vector stored in the model to each of the label vectors.
# get similarity scores from trained model
model.predict_model_docs()
Important parameters:
doc_keys: list of document keys (optional). If None: return the similarity scores for all documents that are used to train the Lbl2Vec model. Else: only return the similarity scores of training documents with the given keys.
Predict label similarities for new documents that are not used for training
Computes the similarity scores for each given and previously unknown document vector to each of the label vectors from the model.
# get similarity scores for each new document from trained model
model.predict_new_docs(tagged_docs=tagged_docs)
Important parameters:
tagged_docs: iterable list of gensim.models.doc2vec.TaggedDocument elements
Save model to disk
model.save('model_name')
Load model from disk
model = Lbl2Vec.load('model_name')
Citing Lbl2Vec
When citing Lbl2Vec in academic papers and theses, please use this BibTeX entry:
@conference{webist21,
author={Tim Schopf. and Daniel Braun. and Florian Matthes.},
title={Lbl2Vec: An Embedding-based Approach for Unsupervised Document Retrieval on Predefined Topics},
booktitle={Proceedings of the 17th International Conference on Web Information Systems and Technologies - WEBIST,},
year={2021},
pages={124-132},
publisher={SciTePress},
organization={INSTICC},
doi={10.5220/0010710300003058},
isbn={978-989-758-536-4},
issn={2184-3252},
}
 41 Jan 7, 2023
41 Jan 7, 2023
 226 Dec 29, 2022
226 Dec 29, 2022
 62 Dec 12, 2022
62 Dec 12, 2022

 19 Dec 10, 2022
19 Dec 10, 2022

 43 Nov 27, 2022
43 Nov 27, 2022

 49 Oct 9, 2022
49 Oct 9, 2022
 26 Dec 3, 2022
26 Dec 3, 2022
![[2021 MultiMedia] CONQUER: Contextual Query-aware Ranking for Video Corpus Moment Retrieval](https://github.com/houzhijian/CONQUER/raw/master/figures/problem_definition.png)
 23 Dec 26, 2022
23 Dec 26, 2022
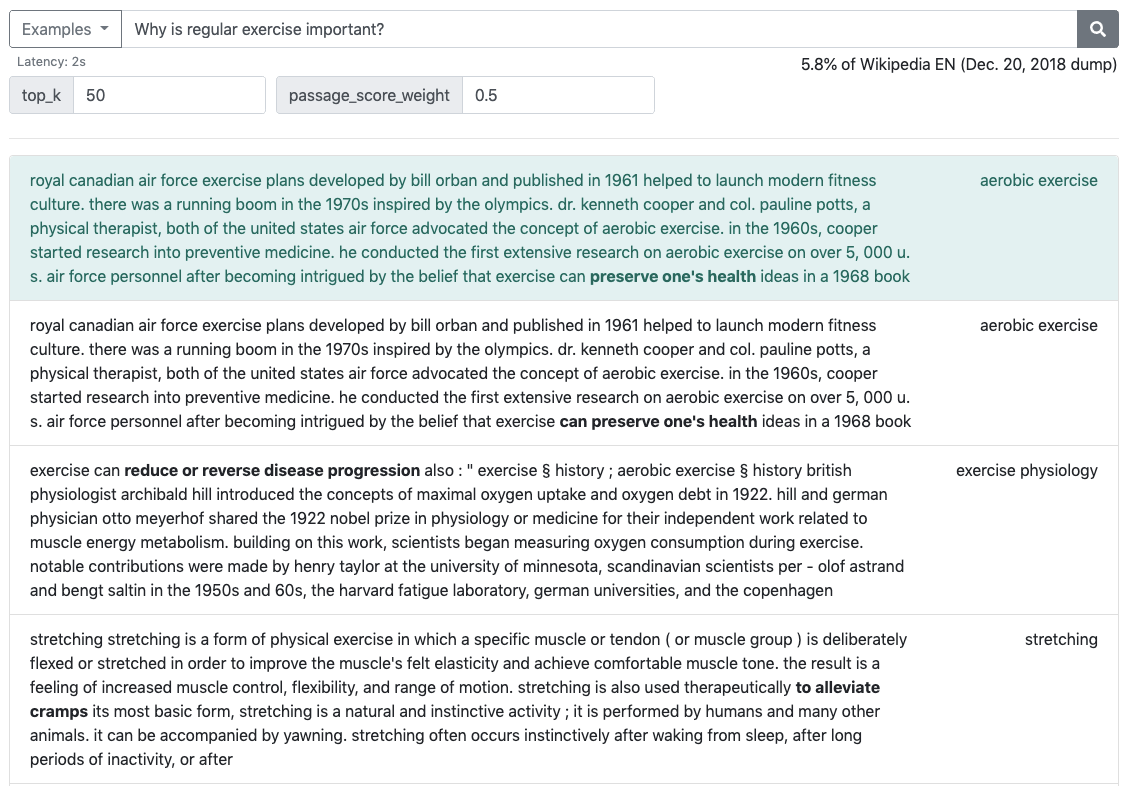
 34 Apr 13, 2022
34 Apr 13, 2022




 26 Aug 22, 2022
26 Aug 22, 2022
 35 Dec 24, 2022
35 Dec 24, 2022
 86 Dec 23, 2022
86 Dec 23, 2022
 52 Oct 13, 2022
52 Oct 13, 2022
 204 Dec 15, 2022
204 Dec 15, 2022
 764 Dec 26, 2022
764 Dec 26, 2022
 57 Nov 14, 2022
57 Nov 14, 2022
 1.3k Dec 27, 2022
1.3k Dec 27, 2022
 144 Dec 25, 2022
144 Dec 25, 2022
 0 Jun 22, 2022
0 Jun 22, 2022
 2.7k Jan 07, 2023
2.7k Jan 07, 2023
 72 Dec 17, 2022
72 Dec 17, 2022
 3 Nov 13, 2022
3 Nov 13, 2022
 3.5k Dec 30, 2022
3.5k Dec 30, 2022
 5 Jan 28, 2022
5 Jan 28, 2022
 18 Dec 10, 2022
18 Dec 10, 2022
 20 Dec 09, 2021
20 Dec 09, 2021
 19 Oct 21, 2022
19 Oct 21, 2022
 1.9k Jan 08, 2023
1.9k Jan 08, 2023