Trapper (Transformers wRAPPER)



![]()


Trapper is an NLP library that aims to make it easier to train transformer based models on downstream tasks. It wraps huggingface/transformers to provide the transformer model implementations and training mechanisms. It defines abstractions with base classes for common tasks encountered while using transformer models. Additionally, it provides a dependency-injection mechanism and allows defining training and/or evaluation experiments via configuration files. By this way, you can replicate your experiment with different models, optimizers etc by only changing their values inside the configuration file without writing any new code or changing the existing code. These features foster code reuse, less boiler-plate code, as well as repeatable and better documented training experiments which is crucial in machine learning.
Why You Should Use Trapper
-
You have been a
Transformersuser for quite some time now. However, you started to feel that some computation steps could be standardized through new abstractions. You wish to reuse the scripts you write for data processing, post-processing etc with different models/tokenizers easily. You would like to separate the code from the experiment details, mix and match components through configuration files while keeping your codebase clean and free of duplication. -
You are an
AllenNLPuser who is really happy with the dependency-injection system, well-defined abstractions and smooth workflow. However, you would like to use the latest transformer models without having to wait for the core developers to integrate them. Moreover, theTransformerscommunity is scaling up rapidly, and you would like to join the party while still enjoying anAllenNLPtouch. -
You are an NLP researcher / practitioner, and you would like to give a shot to a library aiming to support state-of-the-art models along with datasets, metrics and more in unified APIs.
To see more, check the official Trapper blog post.
Key Features
Compatibility with HuggingFace Transformers
Trapper extends Transformers!
While implementing the components of trapper, we try to reuse the classes from the Transformers library as much as we can. For example, trapper uses the models, and the trainer as they are in Transformers. This makes it easy to use the models trained with trapper on other projects or libraries that depend on Transformers (or pytorch in general).
We strive to keep trapper fully compatible with Transformers, so you can always use some of our components to write a script for your own needs while not using the full pipeline (e.g. for training).
Dependency Injection and Training Based on Configuration Files
We use the registry mechanism of AllenNLP to provide dependency injection and enable reading the experiment details from the configuration files in json or jsonnet format. You can look at the AllenNLP guide on dependency injection to learn more about how the registry system and dependency injection works as well as how to write configuration files. In addition, we strongly recommend reading the remaining parts of the AllenNLP guide to learn more about its design philosophy, the importance of abstractions etc. (especially Part2: Abstraction, Design and Testing). As a warning, please note that we do not use AllenNLP's abstractions and base classes in general, which means you can not mix and match the trapper's and AllenNLP's components. Instead, we just use the class registry and dependency injection mechanisms and only adapt its very limited set of components, first by wrapping and registering them as trapper components. For example, we use the optimizers from AllenNLP since we can conveniently do so without hindering our full compatibility with Transformers.
Full Integration with HuggingFace Datasets
In trapper, we officially use the format of the datasets from datasets and provide full integration with it. You can directly use all datasets published in datasets hub without doing any extra work. You can write the dataset name and extra loading arguments (if there are any) in your training config file, and trapper will automatically download the dataset and pass it to the trainer. If you have a local or private dataset, you can still use it after converting it to the HuggingFace datasets format by writing a dataset loading script as explained here.
Support for Metrics through Jury
Trapper supports the common NLP metrics through jury. Jury is an NLP library dedicated to provide metric implementations by adopting and extending the datasets library. For metric computation during training you can use jury style metric instantiation/configuration to set up on your trapper configuration file to compute metrics on the fly on eval dataset with a specified eval_steps value. If your desired metric is not yet available on jury or datasets, you can still create your own by extending trapper.Metric and utilizing either jury.Metric or datasets.Metric for handling larger set of cases on predictions.
Abstractions and Base Classes
Following AllenNLP, we implement our own registrable base classes to abstract away the common operations for data processing and model training.
-
Data reading and preprocessing base classes including
-
The classes to be used directly:
DatasetReader,DatasetLoaderandDataCollator. -
The classes that you may need to extend:
LabelMapper,DataProcessor,DataAdapterandTokenizerWrapper. -
TokenizerWrapperclasses utilizingAutoTokenizerfrom Transformers are used as factories to instantiate wrapped tokenizers into which task-specific special tokens are registered automatically.
-
-
ModelWrapperclasses utilizing theAutoModelFor...classes from Transformers are used as factories to instantiate the actual task-specific models from the configuration files dynamically. -
Optimizers from AllenNLP: Implemented as children of the base
Optimizerclass. -
Metric computation is supported through
jury. In order to make the metrics flexible enough to work with the trainer in a common interface, we introduced metric handlers. You may need to extend these classes accordingly- For conversion of predictions and references to a suitable form for a particular metric or metric set:
MetricInputHandler. - For manipulating resulting score object containing the metric results:
MetricOutputHandler.
- For conversion of predictions and references to a suitable form for a particular metric or metric set:
Usage
To use trapper, you need to select the common NLP formulation of the problem you are tackling as well as decide on its input representation, including the special tokens.
Modeling the Problem
The first step in using trapper is to decide on how to model the problem. First, you need to model your problem as one of the common modeling tasks in NLP such as seq-to-seq, sequence classification etc. We stick with the Transformers' way of dividing the tasks into common categories as it does in its AutoModelFor... classes. To be compatible with Transformers and reuse its model factories, trapper formalizes the tasks by wrapping the AutoModelFor... classes and matching them to a name that represents a common task in NLP. For example, the natural choice for POS tagging is to model it as a token classification (i.e. sequence labeling) task. On the other hand, for question answering task, you can directly use the question answering formulation since Transformers already has a support for that task.
Modeling the Input
You need to decide on how to represent the input including the common special tokens such as BOS, EOS. This formulation is directly used while creating the input_ids value of the input instances. As a concrete example, you can represent a sequence classification input with BOS ... actual_input_tokens ... EOS format. Moreover, some tasks require extra task-specific special tokens as well. For example, in conditional text generation, you may need to prompt the generation with a special signaling token. In tasks that utilizes multiple sequences, you may need to use segment embeddings (via token_type_ids) to label the tokens according to their sequence.
Class Reference
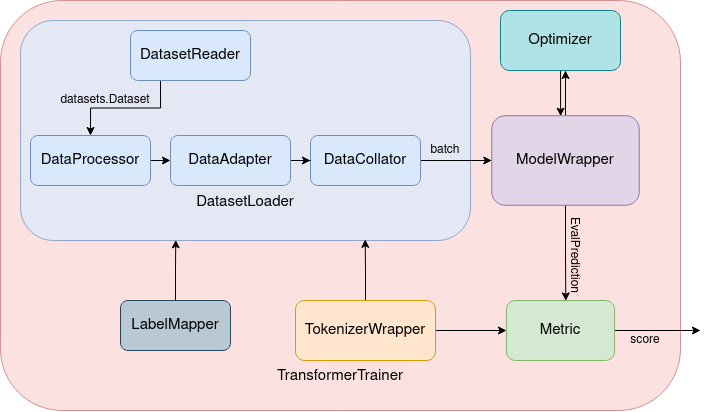
The above diagram shows the basic components in Trapper. To use trapper on training, evaluation on a task that is not readily supported in Transformers, you need to extend the provided base classes according to your own needs. These are as follows:
For Training & Evaluation: LabelMapper, DataProcessor, DataAdapter, TokenizerWrapper, MetricInputHandler, MetricOutputHandler.
For Inference: In addition to the ones listed above, you may need to implement a transformers.Pipeline or directly use one from Transformers if they already implemented one that matches your need.
Typically Extended Classes
-
LabelMapper: Used in tasks that require mapping between categorical labels and integer ids such as token classification.
-
DataProcessor: This class is responsible for taking a single instance in dict format, typically coming from a
datasets.Dataset, extracting the information fields suitable for the task and hand, and converting their values to integers or collections of integers. This includes, tokenizing the string fields, and getting the token ids, converting the categoric labels to integer ids and so on. -
DataAdapter: This is responsible for converting the information fields inside an instance dict that was previously processed by a
DataProcessorto a format suitable for feeding into a transformer model. This also includes handling the special tokens signaling the start or end of a sequence, the separation of tho sequence for a sequence-pair task as well as chopping excess tokens etc. -
TokenizerWrapper: This class wraps a pretrained tokenizer from the Transformers while also recording the special tokens needed for the task to the wrapped tokenizer. It also stores the missing values from BOS - CLS, EOS - SEP token pairs for the tokenizers that only support one of them. This means you can model your input sequence by using the bos_token for start and eos_token for end without thinking which model you are working with. If your task and input modeling needs extra special tokens e.g. the
<CONTEXT>for a context dependent task, you can store these tokens by setting the_TASK_SPECIFIC_SPECIAL_TOKENSclass variable in your TokenizerWrapper subclass. Otherwise, you can directly use TokenizerWrapper. -
MetricInputHandler: This class is mainly responsible for preprocessing applied to predictions and labels (references). This is performed for transforming the predictions and labels to a suitable format to be fed in metrics for computation. For example, while using BLEU in a language generation task, the predictions and labels need to be converted to a string or list of strings. However, for extractive question answering task in which the predictions are returned as start and end indices pointing the answer within the context, additional information (e.g context in such case) may be needed, so directly returning the start and end indices in this case does not help, and additional operation is needed to be done by converting predictions to actual answers extracted from the context. You are able to do this kind of operations through
MetricInputHandler, storing additional information, converting predictions and labels to a suitable format, manipulating resulting score. Furthermore, in child classes helper classes can also be implemented (e.gTokenizerWrapper,LabelMapper) for required tasks. In this class, we provide three main functionality:_extract_metadata(): This method allows user to extract metadata from dataset instances to be later used for preprocessing predictions and labels inpreprocess()method.__call__(): This method allows converting predictions and labels into a suitable form for metric computation. The default behavior is defined as directly returning predictions and labels without manipulation, but only applyingargmax()to predictions to convert the model predictions to predictions input for metrics.
-
MetricOutputHandler: The intention of this class is to support for manipulating the score object returned by the metric computation phase. Jury returns a well-constructed dictionary output for all metrics; however, to shorten dictionary items, manipulate the information within the output or to add additional information to score dictionary, this class can be extended as desired.
-
transformers.Pipeline: The pipeline mechanism from Transformers have not been fully integrated yet. For now, you should check Transformers to find a pipeline that is suitable for your needs and does the same pre-processing. If you could not find one, you may need to write your own
Pipelineby extendingtransformers.Pipelineor one of its subclasses and add it totransformers.pipelines.SUPPORTED_TASKSmap. To enable instantiation of the pipelines from the checkpoint folders, we provide a factory,create_pipeline_from_checkpointfunction. It accepts a checkpoint directory of a completed experiment, the path to the config file (already saved in that directory), as well as the task name that you used while adding the pipeline toSUPPORTED_TASKS. It re-creates the objects you used while training such asmodel wrapper,label mapperetc and provides them as keyword arguments to constructor of the pipeline you implemented.
Registering classes from custom modules to the library
We support both file based and command line argument based approaches to register the external modules written by the users.
Option 1 - File based
You should list the packages or modules (for stand-alone modules not residing inside any package) containing the classes to be registered as plugins to a local file named .trapper_plugins. This file must reside in the same directory where you run the trapper run command. Moreover, it is recommended to put the plugins file where the modules to be registered resides (e.g. the project root) for convenience since that directory will be added to the PYTHONPATH. Otherwise, you need to add the plugin module/packages to the PYTHONPATH manually. Another reminder is that each listed package must have an __init__.py file that imports the modules containing the custom classes to be registered.
E.g., let's say our project's root directory is project_root and the experiment config file is inside the root with a name test_experiment.jsonnet. To run the experiment, you should run the following commands:
cd project_root
trapper run test_experiment.jsonnet
Below output shows the content of the project_root directory.
ls project_root
ner
tests
datasets
.trapper_plugins
test_experiment.jsonnet
Additionally, here is the content of the project_root/.trapper_plugins.
cat project_root/.trapper_plugins
ner.core.models
ner.data.dataset_readers
Option 2 - Using the command line argument
You can specify the packages and/or modules you want to be registered using the --include-package argument. However, note that you need to repeat the argument for each package/module to be registered.
E.g. the running the following commands is an alternative to Option-1 to start the experiment specified in the test_experiment.jsonnet.
trapper run test_experiment.jsonnet \
--include-package ner.core.models \
--include-package ner.data.dataset_readers
Running a training and/or evaluation experiment
Config File Based Training Using the CLI
Go to your project root and execute the trapper run command with a config file specifying the details of the training experiment. E.g.
trapper run SOME_DIRECTORY/experiment.jsonnet
Don't forget to provide the args["output_dir"] and args["result_dir"] values in your experiment file. Please look at the examples/pos_tagging/README.md for a detailed example.
Script Based Training
Go to your project root and execute the trapper run command with a config file specifying the details of the training experiment. E.g.
trapper run SOME_DIRECTORY/experiment.jsonnet
Don't forget to provide the args["output_dir"] and args["result_dir"] values in your experiment file. Please look at the examples/pos_tagging/README.md for a detailed example.
Examples for Using Trapper as a Library
We created an examples folder that includes example projects to help you get started using trapper. Currently, it includes a POS tagging project using the CONLL2003 dataset, and a question answering project using the SQuAD dataset. The POS tagging example shows how to use trapper on a task that does not have a direct support from Transformers. It implements all custom components and provides a complete project structure including the tests. On the other hand, the question answering example shows using trapper on a task that Transformers already supported. We implemented it to demonstrate how trapper may still be helpful thanks to configuration file based experiments.
Training a POS Tagging Model on CONLL2003
Since transformers lacks a direct support for POS tagging, we added an example project that trains a transformer model on CONLL2003 POS tagging dataset and perform inference using it. It is a self-contained project including its own requirements file, therefore you can copy the folder into another directory to use as a template for your own project. Please follow its README.md to get started.
Training a Question Answering Model on SQuAD Dataset
You can use the notebook in the Example QA Project examples/question_answering/question_answering.ipynb to follow the steps while training a transformer model on SQuAD v1.
Currently Supported Tasks and Models From Transformers
Hypothetically, nearly all models should work on any task if it has an entry in the table of AutoModelFor... factories for that task. However, since some models require more (or less) parameters compared to most of the models in the library, you might get errors while using such models. We try to cover these edge cases them by adding the extra parameters they require. Feel free to open an issue/PR if you encounter/solve such issues in a model-task combination. We have used trapper on a limited set of model-task combinations so far. We list these combinations below to indicate that they have been tested and validated to work without problems.
Table of Model-task Combinations Tested so far
| model | question_answering | token_classification |
|---|---|---|
| BERT | |
|
| ALBERT | |
|
| DistillBERT | |
|
| ELECTRA | |
|
| RoBERTa | |
|
Installation
Environment Creation
It is strongly recommended creating a virtual environment using conda or virtualenv etc. before installing this package and its dependencies. For example, the following code creates a conda environment with name trapper and python version 3.7.10, and activates it.
conda create --name trapper python=3.7.10
conda activate trapper
Regular Installation
You can install trapper and its dependencies by pip as follows.
pip install trapper
Contributing
If you would like to open a PR, please create a fresh environment as described before, clone the repo locally and install trapper in editable mode as follows.
git clone https://github.com/obss/trapper.git
cd trapper
pip install -e .[dev]
After your changes, please ensure that the tests are still passing, and do not forget to apply code style formatting.
Testing trapper
Caching the test fixtures from the HuggingFace datasets library
To speed up the data-related tests, we cache the test dataset fixtures from HuggingFace's datasets library using the following command.
python -m scripts.cache_hf_datasets_fixtures
Then, you can simply run the tests with the following command:
python -m scripts.run_tests
NOTE: To significantly speed up the tests depending on HuggingFace's Transformers and datasets libraries, you can set the following environment variables to make them work in offline mode. However, beware that you may need to run the tests once first without setting these environment variables so that the pretrained models, tokenizers etc. are downloaded and cached.
export TRANSFORMERS_OFFLINE=1 HF_DATASETS_OFFLINE=1
Code Style
To check code style,
python -m scripts.run_code_style check
To format codebase,
python -m scripts.run_code_style format




 18 Dec 20, 2022
18 Dec 20, 2022
 13 Sep 08, 2022
13 Sep 08, 2022
 52 Jan 05, 2023
52 Jan 05, 2023
 1.6k Jan 05, 2023
1.6k Jan 05, 2023
 736 Jan 03, 2023
736 Jan 03, 2023
 40 Dec 20, 2022
40 Dec 20, 2022
 877 Jan 05, 2023
877 Jan 05, 2023
 72 Dec 07, 2022
72 Dec 07, 2022
 1k Dec 26, 2022
1k Dec 26, 2022
 2 Feb 22, 2022
2 Feb 22, 2022
 743 Jan 08, 2023
743 Jan 08, 2023
 7 Aug 25, 2022
7 Aug 25, 2022
 79 Dec 27, 2022
79 Dec 27, 2022
 189 Nov 29, 2022
189 Nov 29, 2022
 98 Nov 24, 2022
98 Nov 24, 2022
 20 Jul 14, 2022
20 Jul 14, 2022
 50 Dec 21, 2022
50 Dec 21, 2022
 55 Nov 22, 2022
55 Nov 22, 2022
 1 Jan 18, 2022
1 Jan 18, 2022
 2.1k Jan 07, 2023
2.1k Jan 07, 2023