





QuantStats: Portfolio analytics for quants
QuantStats Python library that performs portfolio profiling, allowing quants and portfolio managers to understand their performance better by providing them with in-depth analytics and risk metrics.
QuantStats is comprised of 3 main modules:
quantstats.stats- for calculating various performance metrics, like Sharpe ratio, Win rate, Volatility, etc.quantstats.plots- for visualizing performance, drawdowns, rolling statistics, monthly returns, etc.quantstats.reports- for generating metrics reports, batch plotting, and creating tear sheets that can be saved as an HTML file.
Here's an example of a simple tear sheet analyzing a strategy:
Quick Start
%matplotlib inline
import quantstats as qs
# extend pandas functionality with metrics, etc.
qs.extend_pandas()
# fetch the daily returns for a stock
stock = qs.utils.download_returns('FB')
# show sharpe ratio
qs.stats.sharpe(stock)
# or using extend_pandas() :)
stock.sharpe()
Output:
0.8135304438803402
Visualize stock performance
qs.plots.snapshot(stock, title='Facebook Performance')
# can also be called via:
# stock.plot_snapshot(title='Facebook Performance')
Output:

Creating a report
You can create 7 different report tearsheets:
qs.reports.metrics(mode='basic|full", ...)- shows basic/full metricsqs.reports.plots(mode='basic|full", ...)- shows basic/full plotsqs.reports.basic(...)- shows basic metrics and plotsqs.reports.full(...)- shows full metrics and plotsqs.reports.html(...)- generates a complete report as html
Let' create an html tearsheet
(benchmark can be a pandas Series or ticker)
qs.reports.html(stock, "SPY")
Output will generate something like this:
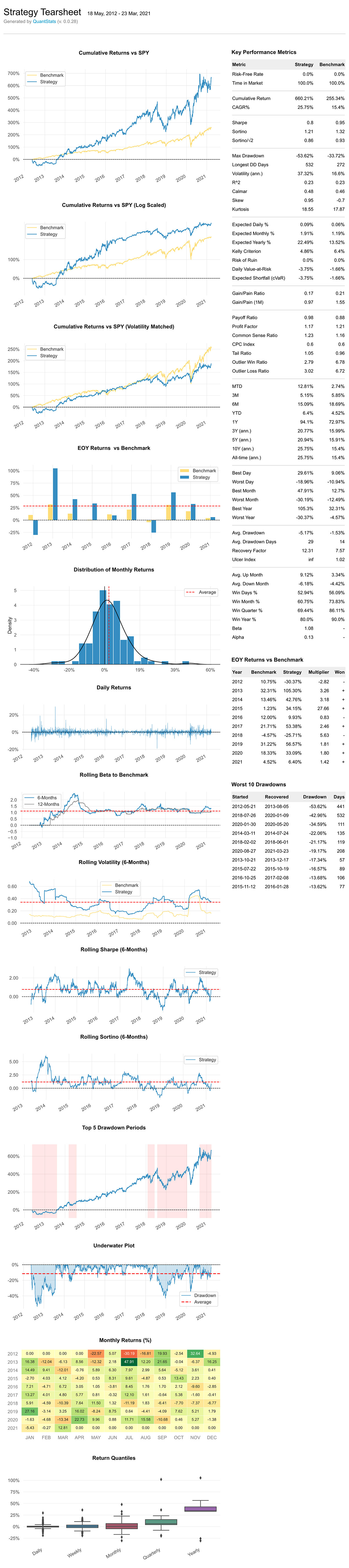
To view a complete list of available methods, run
[f for f in dir(qs.stats) if f[0] != '_']
['avg_loss',
'avg_return',
'avg_win',
'best',
'cagr',
'calmar',
'common_sense_ratio',
'comp',
'compare',
'compsum',
'conditional_value_at_risk',
'consecutive_losses',
'consecutive_wins',
'cpc_index',
'cvar',
'drawdown_details',
'expected_return',
'expected_shortfall',
'exposure',
'gain_to_pain_ratio',
'geometric_mean',
'ghpr',
'greeks',
'implied_volatility',
'information_ratio',
'kelly_criterion',
'kurtosis',
'max_drawdown',
'monthly_returns',
'outlier_loss_ratio',
'outlier_win_ratio',
'outliers',
'payoff_ratio',
'profit_factor',
'profit_ratio',
'r2',
'r_squared',
'rar',
'recovery_factor',
'remove_outliers',
'risk_of_ruin',
'risk_return_ratio',
'rolling_greeks',
'ror',
'sharpe',
'skew',
'sortino',
'adjusted_sortino',
'tail_ratio',
'to_drawdown_series',
'ulcer_index',
'ulcer_performance_index',
'upi',
'utils',
'value_at_risk',
'var',
'volatility',
'win_loss_ratio',
'win_rate',
'worst']
[f for f in dir(qs.plots) if f[0] != '_']
['daily_returns',
'distribution',
'drawdown',
'drawdowns_periods',
'earnings',
'histogram',
'log_returns',
'monthly_heatmap',
'returns',
'rolling_beta',
'rolling_sharpe',
'rolling_sortino',
'rolling_volatility',
'snapshot',
'yearly_returns']
*** Full documenttion coming soon ***
In the meantime, you can get insights as to optional parameters for each method, by using Python's help method:
help(qs.stats.conditional_value_at_risk)
Help on function conditional_value_at_risk in module quantstats.stats:
conditional_value_at_risk(returns, sigma=1, confidence=0.99)
calculats the conditional daily value-at-risk (aka expected shortfall)
quantifies the amount of tail risk an investment
Installation
Install using pip:
$ pip install quantstats --upgrade --no-cache-dir
Install using conda:
$ conda install -c ranaroussi quantstats
Requirements
- Python >= 3.5+
- pandas (tested to work with >=0.24.0)
- numpy >= 1.15.0
- scipy >= 1.2.0
- matplotlib >= 3.0.0
- seaborn >= 0.9.0
- tabulate >= 0.8.0
- yfinance >= 0.1.38
- plotly >= 3.4.1 (optional, for using
plots.to_plotly())
Questions?
This is a new library... If you find a bug, please open an issue in this repository.
If you'd like to contribute, a great place to look is the issues marked with help-wanted.
Known Issues
For some reason, I couldn't find a way to tell seaborn not to return the monthly returns heatmap when instructed to save - so even if you save the plot (by passing savefig={...}) it will still show the plot.
Legal Stuff
QuantStats is distributed under the Apache Software License. See the LICENSE.txt file in the release for details.
P.S.
Please drop me a note with any feedback you have.
Ran Aroussi

















 2 Mar 04, 2022
2 Mar 04, 2022
 3 Sep 09, 2022
3 Sep 09, 2022
 31 Dec 22, 2022
31 Dec 22, 2022
 1 Mar 01, 2022
1 Mar 01, 2022
 53 Nov 15, 2022
53 Nov 15, 2022
 95 Dec 04, 2022
95 Dec 04, 2022
 0 Feb 10, 2022
0 Feb 10, 2022
 1 Aug 04, 2022
1 Aug 04, 2022
 36 Dec 31, 2022
36 Dec 31, 2022
 99 Dec 19, 2022
99 Dec 19, 2022
 11 Dec 20, 2022
11 Dec 20, 2022
 1 Jan 22, 2022
1 Jan 22, 2022
 1 Sep 15, 2022
1 Sep 15, 2022
 5 Jun 17, 2022
5 Jun 17, 2022
 5.9k Dec 31, 2022
5.9k Dec 31, 2022
 0 Feb 04, 2022
0 Feb 04, 2022
 6 Sep 12, 2022
6 Sep 12, 2022
 61 Nov 27, 2022
61 Nov 27, 2022
 33 Dec 30, 2022
33 Dec 30, 2022
 47 Dec 12, 2022
47 Dec 12, 2022