21 Repositories
Latest Python Libraries

Image Captioning using CNN and Transformers
Image-Captioning Keras/Tensorflow Image Captioning application using CNN and Transformer as encoder/decoder. In particulary, the architecture consists
 24 Dec 28, 2022
24 Dec 28, 2022
![Implementation of 'X-Linear Attention Networks for Image Captioning' [CVPR 2020]](https://github.com/JDAI-CV/image-captioning/raw/master/images/framework.jpg)
Implementation of 'X-Linear Attention Networks for Image Captioning' [CVPR 2020]
Introduction This repository is for X-Linear Attention Networks for Image Captioning (CVPR 2020). The original paper can be found here. Please cite wi
 240 Dec 17, 2022
240 Dec 17, 2022

X-modaler is a versatile and high-performance codebase for cross-modal analytics.
X-modaler X-modaler is a versatile and high-performance codebase for cross-modal analytics. This codebase unifies comprehensive high-quality modules i
 910 Dec 28, 2022
910 Dec 28, 2022
End-to-end image captioning with EfficientNet-b3 + LSTM with Attention
Image captioning End-to-end image captioning with EfficientNet-b3 + LSTM with Attention Model is seq2seq model. In the encoder pretrained EfficientNet
 2 Feb 10, 2022
2 Feb 10, 2022

A Persian Image Captioning model based on Vision Encoder Decoder Models of the transformers🤗.
Persian-Image-Captioning We fine-tuning the Vision Encoder Decoder Model for the task of image captioning on the coco-flickr-farsi dataset. The implem
 15 Aug 25, 2022
15 Aug 25, 2022

Meshed-Memory Transformer for Image Captioning. CVPR 2020
M²: Meshed-Memory Transformer This repository contains the reference code for the paper Meshed-Memory Transformer for Image Captioning (CVPR 2020). Pl
 422 Dec 28, 2022
422 Dec 28, 2022
![[CVPR 2020] Transform and Tell: Entity-Aware News Image Captioning](https://github.com/alasdairtran/transform-and-tell/raw/master/figures/teaser.png)
[CVPR 2020] Transform and Tell: Entity-Aware News Image Captioning
Transform and Tell: Entity-Aware News Image Captioning This repository contains the code to reproduce the results in our CVPR 2020 paper Transform and
 85 Dec 13, 2022
85 Dec 13, 2022
LaBERT - A length-controllable and non-autoregressive image captioning model.
Length-Controllable Image Captioning (ECCV2020) This repo provides the implemetation of the paper Length-Controllable Image Captioning. Install conda
 53 Nov 13, 2022
53 Nov 13, 2022
Code for paper Adaptively Aligned Image Captioning via Adaptive Attention Time
Adaptively Aligned Image Captioning via Adaptive Attention Time This repository includes the implementation for Adaptively Aligned Image Captioning vi
 45 Aug 27, 2022
45 Aug 27, 2022
![[CVPR 2021] VirTex: Learning Visual Representations from Textual Annotations](https://github.com/kdexd/virtex/raw/master/docs/_static/system_figure.jpg)
[CVPR 2021] VirTex: Learning Visual Representations from Textual Annotations
VirTex: Learning Visual Representations from Textual Annotations Karan Desai and Justin Johnson University of Michigan CVPR 2021 arxiv.org/abs/2006.06
 533 Dec 24, 2022
533 Dec 24, 2022

Language Models Can See: Plugging Visual Controls in Text Generation
Language Models Can See: Plugging Visual Controls in Text Generation Authors: Yixuan Su, Tian Lan, Yahui Liu, Fangyu Liu, Dani Yogatama, Yan Wang, Lin
 195 Dec 22, 2022
195 Dec 22, 2022
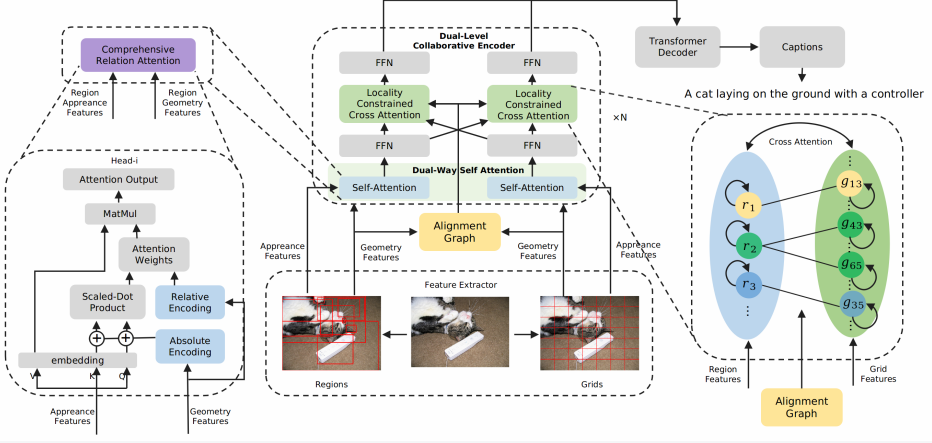
Official pytorch implementation of paper Dual-Level Collaborative Transformer for Image Captioning (AAAI 2021).
Dual-Level Collaborative Transformer for Image Captioning This repository contains the reference code for the paper Dual-Level Collaborative Transform
 160 Dec 11, 2022
160 Dec 11, 2022
Oscar and VinVL
Oscar: Object-Semantics Aligned Pre-training for Vision-and-Language Tasks VinVL: Revisiting Visual Representations in Vision-Language Models Updates
 938 Dec 26, 2022
938 Dec 26, 2022

Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
Official repository of OFA. Paper: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
 1.4k Jan 08, 2023
1.4k Jan 08, 2023

Official repository of OFA. Paper: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
Paper | Blog OFA is a unified multimodal pretrained model that unifies modalities (i.e., cross-modality, vision, language) and tasks (e.g., image gene
1.4k Jan 08, 2023

Bottom-up attention model for image captioning and VQA, based on Faster R-CNN and Visual Genome
bottom-up-attention This code implements a bottom-up attention model, based on multi-gpu training of Faster R-CNN with ResNet-101, using object and at
 1.3k Jan 09, 2023
1.3k Jan 09, 2023
Unofficial pytorch implementation for Self-critical Sequence Training for Image Captioning. and others.
An Image Captioning codebase This is a codebase for image captioning research. It supports: Self critical training from Self-critical Sequence Trainin
 906 Jan 03, 2023
906 Jan 03, 2023

PyTorch code for BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
 1.3k Dec 31, 2022
1.3k Dec 31, 2022

Diverse Image Captioning with Context-Object Split Latent Spaces (NeurIPS 2020)
Diverse Image Captioning with Context-Object Split Latent Spaces This repository is the PyTorch implementation of the paper: Diverse Image Captioning
 34 Nov 21, 2022
34 Nov 21, 2022

Show-attend-and-tell - TensorFlow Implementation of "Show, Attend and Tell"
Show, Attend and Tell Update (December 2, 2016) TensorFlow implementation of Show, Attend and Tell: Neural Image Caption Generation with Visual Attent
 902 Nov 29, 2022
902 Nov 29, 2022
TensorFlow Implementation of "Show, Attend and Tell"
Show, Attend and Tell Update (December 2, 2016) TensorFlow implementation of Show, Attend and Tell: Neural Image Caption Generation with Visual Attent
902 Nov 29, 2022