Hi, I am using BERT for multi label classification.
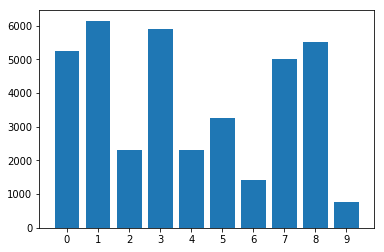
The dataset is imbalance and I use ImbalancedDatasetSampler as the sampler.
(tensor([ 101, 112, 872, 4761, 6887, 1914, 840, 1914, 7353, 6818, 3300, 784,
720, 1408, 136, 1506, 1506, 3300, 4788, 2357, 5456, 119, 119, 119,
4696, 4638, 741, 677, 1091, 4638, 872, 1420, 1521, 119, 119, 119,
872, 2157, 6929, 1779, 4788, 2357, 3221, 686, 4518, 677, 3297, 1920,
4638, 4788, 2357, 117, 1506, 1506, 117, 7745, 872, 4638, 1568, 2124,
3221, 6432, 2225, 1217, 2861, 4478, 4105, 2357, 3221, 686, 4518, 677,
3297, 1920, 4638, 4105, 2357, 1568, 119, 119, 119, 1506, 1506, 1506,
112, 112, 4268, 4268, 117, 1961, 4638, 1928, 1355, 5456, 106, 2769,
812, 1920, 2812, 7370, 3488, 2094, 6963, 6206, 5436, 677, 3341, 2769,
4692, 1168, 3312, 1928, 5361, 7027, 3300, 1928, 1355, 119, 119, 119,
671, 2137, 3221, 8584, 809, 1184, 1931, 1168, 4638, 117, 872, 6432,
3221, 679, 3221, 136, 138, 4495, 4567, 140, 102, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0]),
tensor([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]),
tensor(0))
ValueError Traceback (most recent call last)
File D:\ProgramData\Anaconda3\envs\pytorch\lib\site-packages\pandas\core\frame.py:3892, in DataFrame._ensure_valid_index(self, value)
3891 try:
-> 3892 value = Series(value)
3893 except (ValueError, NotImplementedError, TypeError) as err:
File D:\ProgramData\Anaconda3\envs\pytorch\lib\site-packages\pandas\core\series.py:451, in Series.init(self, data, index, dtype, name, copy, fastpath)
450 else:
--> 451 data = sanitize_array(data, index, dtype, copy)
453 manager = get_option("mode.data_manager")
File D:\ProgramData\Anaconda3\envs\pytorch\lib\site-packages\pandas\core\construction.py:601, in sanitize_array(data, index, dtype, copy, raise_cast_failure, allow_2d)
599 subarr = maybe_infer_to_datetimelike(subarr)
--> 601 subarr = _sanitize_ndim(subarr, data, dtype, index, allow_2d=allow_2d)
603 if isinstance(subarr, np.ndarray):
604 # at this point we should have dtype be None or subarr.dtype == dtype
File D:\ProgramData\Anaconda3\envs\pytorch\lib\site-packages\pandas\core\construction.py:652, in _sanitize_ndim(result, data, dtype, index, allow_2d)
651 return result
--> 652 raise ValueError("Data must be 1-dimensional")
653 if is_object_dtype(dtype) and isinstance(dtype, ExtensionDtype):
654 # i.e. PandasDtype("O")
ValueError Traceback (most recent call last)
Input In [49], in <cell line: 5>()
2 from torchsampler import ImbalancedDatasetSampler
4 batch_size=3
5 dataloader_train_o = DataLoader(
6 dataset_train,
----> 7 sampler=ImbalancedDatasetSampler(dataset_train),
8 batch_size=batch_size,
9 # **kwargs
10 )
12 dataloader_validation_o = DataLoader(
13 dataset_val,
14 sampler=SequentialSampler(dataset_val),
15 batch_size=batch_size,
16 # **kwargs
17 )
File D:\ProgramData\Anaconda3\envs\pytorch\lib\site-packages\torchsampler\imbalanced.py:37, in ImbalancedDatasetSampler.init(self, dataset, labels, indices, num_samples, callback_get_label)
35 # distribution of classes in the dataset
36 df = pd.DataFrame()
---> 37 df["label"] = self._get_labels(dataset) if labels is None else labels
38 df.index = self.indices
39 df = df.sort_index()
File D:\ProgramData\Anaconda3\envs\pytorch\lib\site-packages\pandas\core\frame.py:3655, in DataFrame.setitem(self, key, value)
3652 self._setitem_array([key], value)
3653 else:
3654 # set column
-> 3655 self._set_item(key, value)
File D:\ProgramData\Anaconda3\envs\pytorch\lib\site-packages\pandas\core\frame.py:3832, in DataFrame._set_item(self, key, value)
3822 def _set_item(self, key, value) -> None:
3823 """
3824 Add series to DataFrame in specified column.
3825
(...)
3830 ensure homogeneity.
3831 """
-> 3832 value = self._sanitize_column(value)
3834 if (
3835 key in self.columns
3836 and value.ndim == 1
3837 and not is_extension_array_dtype(value)
3838 ):
3839 # broadcast across multiple columns if necessary
3840 if not self.columns.is_unique or isinstance(self.columns, MultiIndex):
File D:\ProgramData\Anaconda3\envs\pytorch\lib\site-packages\pandas\core\frame.py:4528, in DataFrame._sanitize_column(self, value)
4515 def _sanitize_column(self, value) -> ArrayLike:
4516 """
4517 Ensures new columns (which go into the BlockManager as new blocks) are
4518 always copied and converted into an array.
(...)
4526 numpy.ndarray or ExtensionArray
4527 """
-> 4528 self._ensure_valid_index(value)
4530 # We should never get here with DataFrame value
4531 if isinstance(value, Series):
File D:\ProgramData\Anaconda3\envs\pytorch\lib\site-packages\pandas\core\frame.py:3894, in DataFrame._ensure_valid_index(self, value)
3892 value = Series(value)
3893 except (ValueError, NotImplementedError, TypeError) as err:
-> 3894 raise ValueError(
3895 "Cannot set a frame with no defined index "
3896 "and a value that cannot be converted to a Series"
3897 ) from err
3899 # GH31368 preserve name of index
3900 index_copy = value.index.copy()
ValueError: Cannot set a frame with no defined index and a value that cannot be converted to a Series


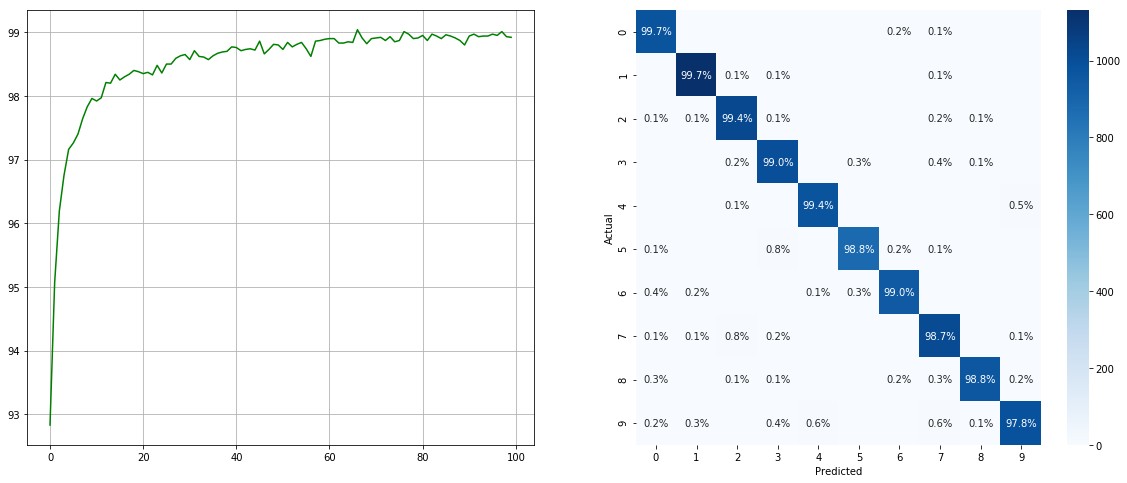 (left: test acc in each epoch; right: confusion matrix)
(left: test acc in each epoch; right: confusion matrix) 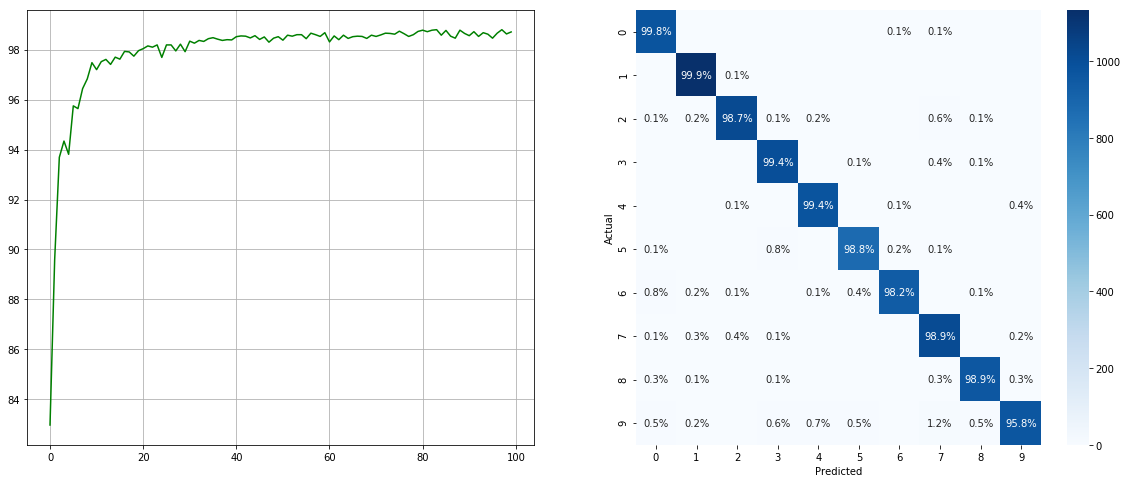 (left: test acc in each epoch; right: confusion matrix)
(left: test acc in each epoch; right: confusion matrix) 













 16 Nov 14, 2022
16 Nov 14, 2022
 0 Jan 10, 2022
0 Jan 10, 2022
 2.1k Jan 03, 2023
2.1k Jan 03, 2023
 6 Jul 18, 2022
6 Jul 18, 2022
 2 Feb 09, 2022
2 Feb 09, 2022
 235 Dec 24, 2022
235 Dec 24, 2022
 38 Dec 15, 2022
38 Dec 15, 2022
 272 Dec 29, 2022
272 Dec 29, 2022
 0 Nov 30, 2021
0 Nov 30, 2021
 534 Dec 17, 2022
534 Dec 17, 2022
 12 Sep 28, 2022
12 Sep 28, 2022
 5 May 15, 2022
5 May 15, 2022
 3 Oct 17, 2022
3 Oct 17, 2022
 6k Jan 06, 2023
6k Jan 06, 2023
 62 Dec 03, 2022
62 Dec 03, 2022
 105 Dec 30, 2022
105 Dec 30, 2022
 408 Jan 01, 2023
408 Jan 01, 2023
 0 Jan 02, 2022
0 Jan 02, 2022
 11 Dec 22, 2022
11 Dec 22, 2022
 49 Jan 07, 2023
49 Jan 07, 2023