Focal Frequency Loss - Official PyTorch Implementation
This repository provides the official PyTorch implementation for the following paper:
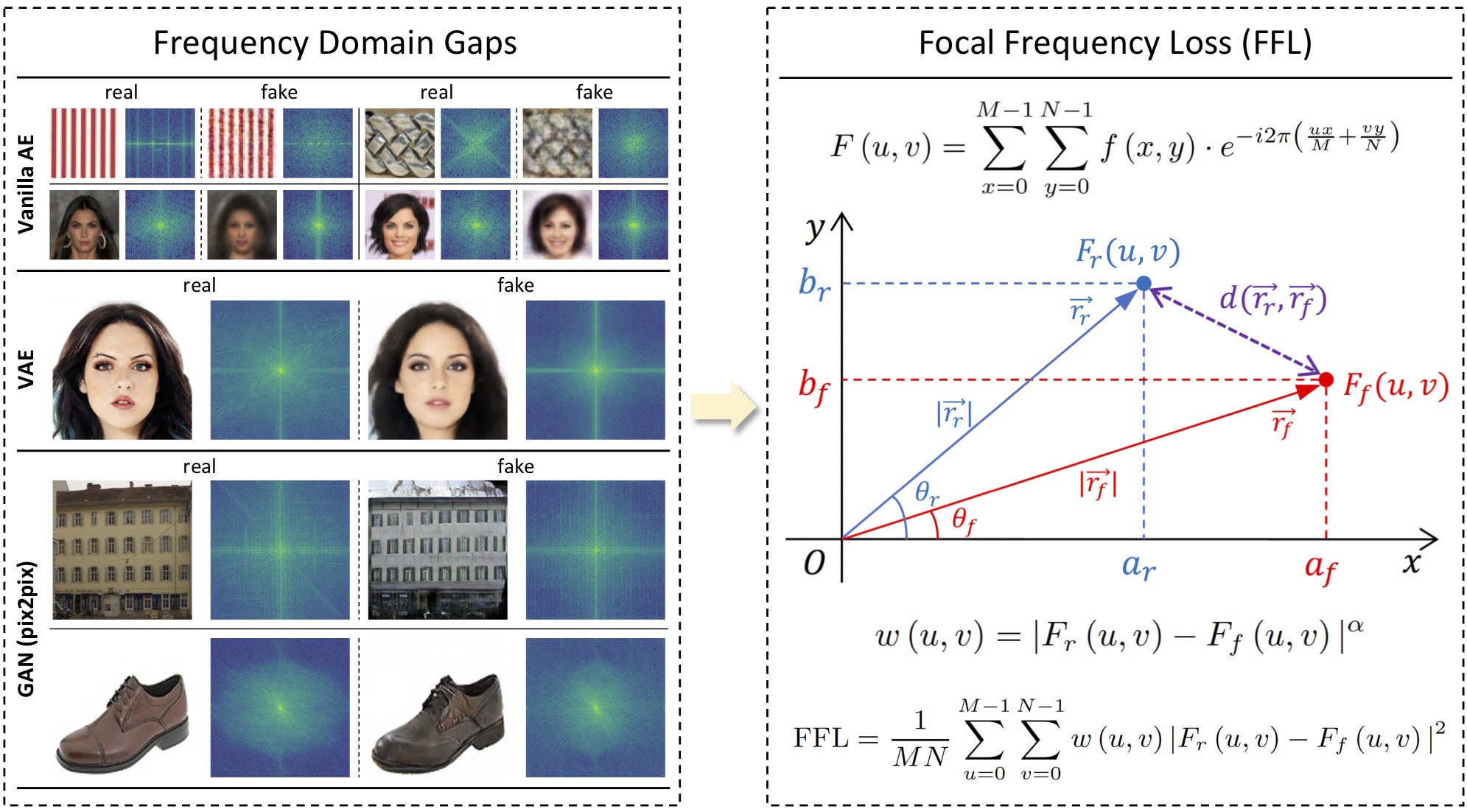
Focal Frequency Loss for Image Reconstruction and Synthesis
Liming Jiang, Bo Dai, Wayne Wu and Chen Change Loy
In ICCV 2021.
Project Page | Paper | Poster | Slides | YouTube Demo
Abstract: Image reconstruction and synthesis have witnessed remarkable progress thanks to the development of generative models. Nonetheless, gaps could still exist between the real and generated images, especially in the frequency domain. In this study, we show that narrowing gaps in the frequency domain can ameliorate image reconstruction and synthesis quality further. We propose a novel focal frequency loss, which allows a model to adaptively focus on frequency components that are hard to synthesize by down-weighting the easy ones. This objective function is complementary to existing spatial losses, offering great impedance against the loss of important frequency information due to the inherent bias of neural networks. We demonstrate the versatility and effectiveness of focal frequency loss to improve popular models, such as VAE, pix2pix, and SPADE, in both perceptual quality and quantitative performance. We further show its potential on StyleGAN2.
Updates
-
[09/2021] The code of Focal Frequency Loss is released.
-
[07/2021] The paper of Focal Frequency Loss is accepted by ICCV 2021.
Quick Start
Run pip install focal-frequency-loss for installation. Then, the following code is all you need.
from focal_frequency_loss import FocalFrequencyLoss as FFL
ffl = FFL(loss_weight=1.0, alpha=1.0) # initialize nn.Module class
import torch
fake = torch.randn(4, 3, 64, 64) # replace it with the predicted tensor of shape (N, C, H, W)
real = torch.randn(4, 3, 64, 64) # replace it with the target tensor of shape (N, C, H, W)
loss = ffl(fake, real) # calculate focal frequency loss
Tips:
- Current supported PyTorch version:
torch>=1.1.0. Warnings can be ignored. Please note that experiments in the paper were conducted withtorch<=1.7.1,>=1.1.0. - Arguments to initialize the
FocalFrequencyLossclass:loss_weight (float): weight for focal frequency loss. Default: 1.0alpha (float): the scaling factor alpha of the spectrum weight matrix for flexibility. Default: 1.0patch_factor (int): the factor to crop image patches for patch-based focal frequency loss. Default: 1ave_spectrum (bool): whether to use minibatch average spectrum. Default: Falselog_matrix (bool): whether to adjust the spectrum weight matrix by logarithm. Default: Falsebatch_matrix (bool): whether to calculate the spectrum weight matrix using batch-based statistics. Default: False
- Experience shows that the main hyperparameters you need to adjust are
loss_weightandalpha. The loss weight may always need to be adjusted first. Then, a larger alpha indicates that the model is more focused. We usealpha=1.0as default.
Exmaple: Image Reconstruction (Vanilla AE)
As a guide, we provide an example of applying the proposed focal frequency loss (FFL) for Vanilla AE image reconstruction on CelebA. Applying FFL is pretty easy. The core details can be found here.
Installation
After installing Anaconda, we recommend you to create a new conda environment with python 3.8.3:
conda create -n ffl python=3.8.3 -y
conda activate ffl
Clone this repo, install PyTorch 1.4.0 (torch>=1.1.0 may also work) and other dependencies:
git clone https://github.com/EndlessSora/focal-frequency-loss.git
cd focal-frequency-loss
pip install -r VanillaAE/requirements.txt
Dataset Preparation
In this example, please download img_align_celeba.zip of the CelebA dataset from its official website. Then, we highly recommend you to unzip this file and symlink the img_align_celeba folder to ./datasets/celeba by:
bash scripts/datasets/prepare_celeba.sh [PATH_TO_IMG_ALIGN_CELEBA]
Or you can simply move the img_align_celeba folder to ./datasets/celeba. The resulting directory structure should be:
├── datasets
│ ├── celeba
│ │ ├── img_align_celeba
│ │ │ ├── 000001.jpg
│ │ │ ├── 000002.jpg
│ │ │ ├── 000003.jpg
│ │ │ ├── ...
Test and Evaluation Metrics
Download the pretrained models and unzip them to ./VanillaAE/experiments.
We have provided the example test scripts. If you only have a CPU environment, please specify --no_cuda in the script. Run:
bash scripts/VanillaAE/test/celeba_recon_wo_ffl.sh
bash scripts/VanillaAE/test/celeba_recon_w_ffl.sh
The Vanilla AE image reconstruction results will be saved at ./VanillaAE/results by default.
After testing, you can further calculate the evaluation metrics for this example. We have implemented a series of evaluation metrics we used and provided the metric scripts. Run:
bash scripts/VanillaAE/metrics/celeba_recon_wo_ffl.sh
bash scripts/VanillaAE/metrics/celeba_recon_w_ffl.sh
You will see the scores of different metrics. The metric logs will be saved in the respective experiment folders at ./VanillaAE/results.
Training
We have provided the example training scripts. If you only have a CPU environment, please specify --no_cuda in the script. Run:
bash scripts/VanillaAE/train/celeba_recon_wo_ffl.sh
bash scripts/VanillaAE/train/celeba_recon_w_ffl.sh
After training, inference on the newly trained models is similar to Test and Evaluation Metrics. The results could be better reproduced on NVIDIA Tesla V100 GPUs with torch<=1.7.1,>=1.1.0.
More Results
Here, we show other examples of applying the proposed focal frequency loss (FFL) under diverse settings.
Image Reconstruction (VAE)

Image-to-Image Translation (pix2pix | SPADE)

Unconditional Image Synthesis (StyleGAN2)
256x256 results (without truncation) and the mini-batch average spectra (adjusted to better contrast):

1024x1024 results (without truncation) synthesized by StyleGAN2 with FFL:

Citation
If you find this work useful for your research, please cite our paper:
@inproceedings{jiang2021focal,
title={Focal Frequency Loss for Image Reconstruction and Synthesis},
author={Jiang, Liming and Dai, Bo and Wu, Wayne and Loy, Chen Change},
booktitle={ICCV},
year={2021}
}
Acknowledgments
The code of Vanilla AE is inspired by PyTorch DCGAN and MUNIT. Part of the evaluation metric code is borrowed from MMEditing. We also apply LPIPS and pytorch-fid as evaluation metrics.
License
All rights reserved. The code is released under the MIT License.
Copyright (c) 2021

 68 Oct 18, 2022
68 Oct 18, 2022
 11 Nov 27, 2022
11 Nov 27, 2022
 2 Sep 13, 2022
2 Sep 13, 2022
 12 Nov 25, 2022
12 Nov 25, 2022
 38 Dec 07, 2022
38 Dec 07, 2022
 17 Oct 27, 2022
17 Oct 27, 2022
 5 Dec 31, 2022
5 Dec 31, 2022
 41 Dec 23, 2022
41 Dec 23, 2022
 0 Jun 08, 2022
0 Jun 08, 2022
 115 Jan 02, 2023
115 Jan 02, 2023
 10 Oct 11, 2022
10 Oct 11, 2022
 251 Jan 03, 2023
251 Jan 03, 2023
 70 Jan 01, 2023
70 Jan 01, 2023
 4 Dec 12, 2022
4 Dec 12, 2022
 37 Dec 18, 2022
37 Dec 18, 2022
 1 Jan 03, 2022
1 Jan 03, 2022
 266 Nov 24, 2022
266 Nov 24, 2022
 9 Feb 15, 2022
9 Feb 15, 2022
 3 Jun 27, 2022
3 Jun 27, 2022
 57 Dec 04, 2022
57 Dec 04, 2022