First of all currently it is not possible to use straight sphinx-build command to build documentation out of source tree
+ /usr/bin/sphinx-build -j48 -n -T -b man docs build/sphinx/man
Running Sphinx v5.2.2
/usr/lib/python3.8/site-packages/pkg_resources/__init__.py:123: PkgResourcesDeprecationWarning: 1.17.1-unknown is an invalid version and will not be supported in a future release
warnings.warn(
making output directory... done
myst v0.18.0: MdParserConfig(commonmark_only=False, gfm_only=False, enable_extensions=['dollarmath', 'colon_fence'], disable_syntax=[], all_links_external=False, url_schemes=('http', 'https', 'mailto', 'ftp'), ref_domains=None, highlight_code_blocks=True, number_code_blocks=[], title_to_header=False, heading_anchors=None, heading_slug_func=None, footnote_transition=True, words_per_minute=200, sub_delimiters=('{', '}'), linkify_fuzzy_links=True, dmath_allow_labels=True, dmath_allow_space=True, dmath_allow_digits=True, dmath_double_inline=False, update_mathjax=True, mathjax_classes='tex2jax_process|mathjax_process|math|output_area')
myst-nb v0.16.0: NbParserConfig(custom_formats={}, metadata_key='mystnb', cell_metadata_key='mystnb', kernel_rgx_aliases={}, execution_mode='off', execution_cache_path='', execution_excludepatterns=(), execution_timeout=-1, execution_in_temp=False, execution_allow_errors=False, execution_raise_on_error=False, execution_show_tb=False, merge_streams=False, render_plugin='default', remove_code_source=False, remove_code_outputs=False, number_source_lines=False, output_stderr='show', render_text_lexer='myst-ansi', render_error_lexer='ipythontb', render_image_options={}, render_figure_options={}, render_markdown_format='commonmark', output_folder='build', append_css=True, metadata_to_fm=False)
Using jupyter-cache at: /home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/build/sphinx/.jupyter_cache
building [mo]: targets for 0 po files that are out of date
building [man]: all manpages
updating environment: [new config] 15 added, 0 changed, 0 removed
reading sources... [100%] user/upgrade
WARNING: autodoc: failed to import function 'autocorr.integrated_time' from module 'emcee'; the following exception was raised:
No module named 'emcee'
WARNING: autodoc: failed to import function 'autocorr.function_1d' from module 'emcee'; the following exception was raised:
No module named 'emcee'
WARNING: autodoc: failed to import class 'backends.Backend' from module 'emcee'; the following exception was raised:
No module named 'emcee'
WARNING: autodoc: failed to import class 'backends.HDFBackend' from module 'emcee'; the following exception was raised:
No module named 'emcee'
WARNING: autodoc: failed to import class 'moves.RedBlueMove' from module 'emcee'; the following exception was raised:
No module named 'emcee'
WARNING: autodoc: failed to import class 'moves.StretchMove' from module 'emcee'; the following exception was raised:
No module named 'emcee'
WARNING: autodoc: failed to import class 'moves.WalkMove' from module 'emcee'; the following exception was raised:
No module named 'emcee'
WARNING: autodoc: failed to import class 'moves.KDEMove' from module 'emcee'; the following exception was raised:
No module named 'emcee'
WARNING: autodoc: failed to import class 'moves.DEMove' from module 'emcee'; the following exception was raised:
No module named 'emcee'
WARNING: autodoc: failed to import class 'moves.DESnookerMove' from module 'emcee'; the following exception was raised:
No module named 'emcee'
WARNING: autodoc: failed to import class 'moves.MHMove' from module 'emcee'; the following exception was raised:
No module named 'emcee'
WARNING: autodoc: failed to import class 'moves.GaussianMove' from module 'emcee'; the following exception was raised:
No module named 'emcee'
WARNING: autodoc: failed to import class 'EnsembleSampler' from module 'emcee'; the following exception was raised:
No module named 'emcee'
WARNING: autodoc: failed to import class 'State' from module 'emcee'; the following exception was raised:
No module named 'emcee'
looking for now-outdated files... none found
pickling environment... done
checking consistency... done
writing... python-emcee.3 { user/install user/sampler user/moves user/blobs user/backends user/autocorr user/upgrade user/faq tutorials/quickstart tutorials/line tutorials/parallel tutorials/autocorr tutorials/monitor tutorials/moves } /home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/user/sampler.rst:6: WARNING: py:class reference target not found: EnsembleSampler
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/user/sampler.rst:12: WARNING: py:class reference target not found: EnsembleSampler
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/user/sampler.rst:12: WARNING: py:class reference target not found: State
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/user/moves.rst:27: WARNING: py:class reference target not found: EnsembleSampler
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/user/moves.rst:33: WARNING: py:class reference target not found: moves.StretchMove
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/user/moves.rst:33: WARNING: py:class reference target not found: moves.RedBlueMove
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/user/moves.rst:33: WARNING: py:class reference target not found: moves.MHMove
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/user/moves.rst:33: WARNING: py:class reference target not found: moves.GaussianMove
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/user/blobs.rst:59: WARNING: py:class reference target not found: EnsembleSampler
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/user/backends.rst:12: WARNING: py:class reference target not found: emcee.backends.HDFBackend
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/user/backends.rst:12: WARNING: py:class reference target not found: backends.HDFBackend
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/user/upgrade.rst:19: WARNING: py:class reference target not found: EnsembleSampler
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/tutorials/quickstart.ipynb:70002: WARNING: py:class reference target not found: EnsembleSampler
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/tutorials/quickstart.ipynb:120002: WARNING: py:class reference target not found: EnsembleSampler
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/tutorials/quickstart.ipynb:180002: WARNING: py:func reference target not found: EnsembleSampler.run_mcmc
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/tutorials/quickstart.ipynb:180002: WARNING: py:func reference target not found: EnsembleSampler.reset
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/tutorials/quickstart.ipynb:200002: WARNING: py:func reference target not found: EnsembleSampler.get_chain
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/tutorials/quickstart.ipynb:220002: WARNING: py:func reference target not found: EnsembleSampler.acceptance_fraction
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/tutorials/line.ipynb:190002: WARNING: py:func reference target not found: EnsembleSampler.get_chain
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/tutorials/monitor.ipynb:10009: WARNING: py:class reference target not found: backends.HDFBackend
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/tutorials/monitor.ipynb:110002: WARNING: py:class reference target not found: backends.HDFBackend
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/tutorials/monitor.ipynb:130004: WARNING: py:func reference target not found: backends.HDFBackend.reset
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/tutorials/moves.ipynb:40002: WARNING: py:class reference target not found: moves.StretchMove
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/tutorials/moves.ipynb:80002: WARNING: py:class reference target not found: moves.DEMove
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/tutorials/moves.ipynb:80002: WARNING: py:class reference target not found: moves.DESnookerMove
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/tutorials/moves.ipynb:80002: WARNING: py:class reference target not found: moves.DESnookerMove
done
build succeeded, 40 warnings.
This can be fixed by patch like below:
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -1,5 +1,9 @@
# -*- coding: utf-8 -*-
+import sys
+import os
+sys.path.insert(0, os.path.abspath("../src"))
+
from pkg_resources import DistributionNotFound, get_distribution
try:
This patch fixes what is in the comment and that can of fix is suggested in sphinx example copy.py https://www.sphinx-doc.org/en/master/usage/configuration.html#example-of-configuration-file
Than .. on building my packages I'm using sphinx-build command with -n switch which shows warmings about missing references. These are not critical issues.
+ /usr/bin/sphinx-build -j48 -n -T -b man docs build/sphinx/man
Running Sphinx v5.2.2
making output directory... done
myst v0.18.0: MdParserConfig(commonmark_only=False, gfm_only=False, enable_extensions=['dollarmath', 'colon_fence'], disable_syntax=[], all_links_external=False, url_schemes=('http', 'https', 'mailto', 'ftp'), ref_domains=None, highlight_code_blocks=True, number_code_blocks=[], title_to_header=False, heading_anchors=None, heading_slug_func=None, footnote_transition=True, words_per_minute=200, sub_delimiters=('{', '}'), linkify_fuzzy_links=True, dmath_allow_labels=True, dmath_allow_space=True, dmath_allow_digits=True, dmath_double_inline=False, update_mathjax=True, mathjax_classes='tex2jax_process|mathjax_process|math|output_area')
myst-nb v0.16.0: NbParserConfig(custom_formats={}, metadata_key='mystnb', cell_metadata_key='mystnb', kernel_rgx_aliases={}, execution_mode='off', execution_cache_path='', execution_excludepatterns=(), execution_timeout=-1, execution_in_temp=False, execution_allow_errors=False, execution_raise_on_error=False, execution_show_tb=False, merge_streams=False, render_plugin='default', remove_code_source=False, remove_code_outputs=False, number_source_lines=False, output_stderr='show', render_text_lexer='myst-ansi', render_error_lexer='ipythontb', render_image_options={}, render_figure_options={}, render_markdown_format='commonmark', output_folder='build', append_css=True, metadata_to_fm=False)
Using jupyter-cache at: /home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/build/sphinx/.jupyter_cache
building [mo]: targets for 0 po files that are out of date
building [man]: all manpages
updating environment: [new config] 15 added, 0 changed, 0 removed
reading sources... [100%] user/upgrade
looking for now-outdated files... none found
pickling environment... done
checking consistency... done
writing... python-emcee.3 { user/install user/sampler user/moves user/blobs user/backends user/autocorr user/upgrade user/faq tutorials/quickstart tutorials/line tutorials/parallel tutorials/autocorr tutorials/monitor tutorials/moves } /home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/user/sampler.rst:6: WARNING: py:class reference target not found: EnsembleSampler
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/ensemble.py:docstring of emcee.ensemble.EnsembleSampler:1: WARNING: py:class reference target not found: callable
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/ensemble.py:docstring of emcee.ensemble.EnsembleSampler:18: WARNING: py:class reference target not found: StretchMove
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/ensemble.py:docstring of emcee.ensemble.EnsembleSampler.get_autocorr_time:1: WARNING: py:class reference target not found: array
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/ensemble.py:docstring of emcee.ensemble.EnsembleSampler.get_autocorr_time:1: WARNING: py:class reference target not found: ndim
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/ensemble.py:docstring of emcee.ensemble.EnsembleSampler.get_blobs:1: WARNING: py:class reference target not found: array
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/ensemble.py:docstring of emcee.ensemble.EnsembleSampler.get_blobs:1: WARNING: py:class reference target not found: nwalkers
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/ensemble.py:docstring of emcee.ensemble.EnsembleSampler.get_chain:1: WARNING: py:class reference target not found: array
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/ensemble.py:docstring of emcee.ensemble.EnsembleSampler.get_chain:1: WARNING: py:class reference target not found: nwalkers
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/ensemble.py:docstring of emcee.ensemble.EnsembleSampler.get_chain:1: WARNING: py:class reference target not found: ndim
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/ensemble.py:docstring of emcee.ensemble.EnsembleSampler.get_log_prob:1: WARNING: py:class reference target not found: array
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/ensemble.py:docstring of emcee.ensemble.EnsembleSampler.get_log_prob:1: WARNING: py:class reference target not found: nwalkers
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/ensemble.py:docstring of emcee.ensemble.EnsembleSampler.sample:: WARNING: py:class reference target not found: ndarray
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/ensemble.py:docstring of emcee.ensemble.EnsembleSampler.sample:: WARNING: py:class reference target not found: nwalkers
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/ensemble.py:docstring of emcee.ensemble.EnsembleSampler.sample:: WARNING: py:class reference target not found: ndim
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/ensemble.py:docstring of emcee.ensemble.EnsembleSampler.sample:: WARNING: py:class reference target not found: NoneType
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/user/sampler.rst:12: WARNING: py:class reference target not found: EnsembleSampler
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/user/sampler.rst:12: WARNING: py:class reference target not found: State
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/state.py:docstring of emcee.state.State:1: WARNING: py:class reference target not found: ndarray
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/state.py:docstring of emcee.state.State:1: WARNING: py:class reference target not found: nwalkers
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/state.py:docstring of emcee.state.State:1: WARNING: py:class reference target not found: ndim
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/state.py:docstring of emcee.state.State:1: WARNING: py:class reference target not found: ndarray
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/state.py:docstring of emcee.state.State:1: WARNING: py:class reference target not found: nwalkers
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/state.py:docstring of emcee.state.State:1: WARNING: py:class reference target not found: ndim
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/user/moves.rst:27: WARNING: py:class reference target not found: EnsembleSampler
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/user/moves.rst:33: WARNING: py:class reference target not found: moves.StretchMove
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/user/moves.rst:33: WARNING: py:class reference target not found: moves.RedBlueMove
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/user/moves.rst:33: WARNING: py:class reference target not found: moves.MHMove
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/user/moves.rst:33: WARNING: py:class reference target not found: moves.GaussianMove
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/moves/mh.py:docstring of emcee.moves.mh.MHMove:3: WARNING: py:class reference target not found: moves.GaussianMove
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/user/blobs.rst:59: WARNING: py:class reference target not found: EnsembleSampler
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/user/backends.rst:12: WARNING: py:class reference target not found: backends.HDFBackend
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/backends/backend.py:docstring of emcee.backends.backend.Backend.get_autocorr_time:1: WARNING: py:class reference target not found: array
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/backends/backend.py:docstring of emcee.backends.backend.Backend.get_autocorr_time:1: WARNING: py:class reference target not found: ndim
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/backends/backend.py:docstring of emcee.backends.backend.Backend.get_blobs:1: WARNING: py:class reference target not found: array
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/backends/backend.py:docstring of emcee.backends.backend.Backend.get_blobs:1: WARNING: py:class reference target not found: nwalkers
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/backends/backend.py:docstring of emcee.backends.backend.Backend.get_chain:1: WARNING: py:class reference target not found: array
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/backends/backend.py:docstring of emcee.backends.backend.Backend.get_chain:1: WARNING: py:class reference target not found: nwalkers
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/backends/backend.py:docstring of emcee.backends.backend.Backend.get_chain:1: WARNING: py:class reference target not found: ndim
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/backends/backend.py:docstring of emcee.backends.backend.Backend.get_log_prob:1: WARNING: py:class reference target not found: array
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/backends/backend.py:docstring of emcee.backends.backend.Backend.get_log_prob:1: WARNING: py:class reference target not found: nwalkers
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/backends/backend.py:docstring of emcee.backends.backend.Backend.save_step:3: WARNING: py:class reference target not found: State
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/backends/backend.py:docstring of emcee.backends.backend.Backend.save_step:1: WARNING: py:class reference target not found: ndarray
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/backends/hdf.py:docstring of emcee.backends.hdf.HDFBackend:1: WARNING: py:class reference target not found: str; optional
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/backends/hdf.py:docstring of emcee.backends.hdf.HDFBackend:1: WARNING: py:class reference target not found: bool; optional
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/backends/hdf.py:docstring of emcee.backends.backend.Backend.get_autocorr_time:1: WARNING: py:class reference target not found: array
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/backends/hdf.py:docstring of emcee.backends.backend.Backend.get_autocorr_time:1: WARNING: py:class reference target not found: ndim
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/backends/hdf.py:docstring of emcee.backends.backend.Backend.get_blobs:1: WARNING: py:class reference target not found: array
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/backends/hdf.py:docstring of emcee.backends.backend.Backend.get_blobs:1: WARNING: py:class reference target not found: nwalkers
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/backends/hdf.py:docstring of emcee.backends.backend.Backend.get_chain:1: WARNING: py:class reference target not found: array
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/backends/hdf.py:docstring of emcee.backends.backend.Backend.get_chain:1: WARNING: py:class reference target not found: nwalkers
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/backends/hdf.py:docstring of emcee.backends.backend.Backend.get_chain:1: WARNING: py:class reference target not found: ndim
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/backends/hdf.py:docstring of emcee.backends.backend.Backend.get_log_prob:1: WARNING: py:class reference target not found: array
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/backends/hdf.py:docstring of emcee.backends.backend.Backend.get_log_prob:1: WARNING: py:class reference target not found: nwalkers
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/backends/hdf.py:docstring of emcee.backends.hdf.HDFBackend.save_step:3: WARNING: py:class reference target not found: State
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/backends/hdf.py:docstring of emcee.backends.hdf.HDFBackend.save_step:1: WARNING: py:class reference target not found: ndarray
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/autocorr.py:docstring of emcee.autocorr.integrated_time:16: WARNING: py:class reference target not found: AutocorrError
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/autocorr.py:docstring of emcee.autocorr.integrated_time:1: WARNING: py:class reference target not found: array
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/src/emcee/autocorr.py:docstring of emcee.autocorr.function_1d:1: WARNING: py:class reference target not found: array
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/user/upgrade.rst:19: WARNING: py:class reference target not found: EnsembleSampler
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/tutorials/quickstart.ipynb:70002: WARNING: py:class reference target not found: EnsembleSampler
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/tutorials/quickstart.ipynb:120002: WARNING: py:class reference target not found: EnsembleSampler
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/tutorials/quickstart.ipynb:180002: WARNING: py:func reference target not found: EnsembleSampler.run_mcmc
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/tutorials/quickstart.ipynb:180002: WARNING: py:func reference target not found: EnsembleSampler.reset
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/tutorials/quickstart.ipynb:200002: WARNING: py:func reference target not found: EnsembleSampler.get_chain
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/tutorials/quickstart.ipynb:220002: WARNING: py:func reference target not found: EnsembleSampler.acceptance_fraction
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/tutorials/line.ipynb:190002: WARNING: py:func reference target not found: EnsembleSampler.get_chain
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/tutorials/monitor.ipynb:10009: WARNING: py:class reference target not found: backends.HDFBackend
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/tutorials/monitor.ipynb:110002: WARNING: py:class reference target not found: backends.HDFBackend
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/tutorials/monitor.ipynb:130004: WARNING: py:func reference target not found: backends.HDFBackend.reset
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/tutorials/moves.ipynb:40002: WARNING: py:class reference target not found: moves.StretchMove
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/tutorials/moves.ipynb:80002: WARNING: py:class reference target not found: moves.DEMove
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/tutorials/moves.ipynb:80002: WARNING: py:class reference target not found: moves.DESnookerMove
/home/tkloczko/rpmbuild/BUILD/emcee-3.1.3/docs/tutorials/moves.ipynb:80002: WARNING: py:class reference target not found: moves.DESnookerMove
done
build succeeded, 74 warnings.
You can peak on fixes that kind of issues in other projects
https://github.com/latchset/jwcrypto/pull/289
https://github.com/click-contrib/sphinx-click/commit/abc31069
https://github.com/latchset/jwcrypto/pull/289
https://github.com/RDFLib/rdflib-sqlalchemy/issues/95
https://github.com/sissaschool/elementpath/commit/bf869d9e
https://github.com/jaraco/cssutils/issues/21
https://github.com/pywbem/pywbem/pull/2895
https://github.com/sissaschool/xmlschema/commit/42ea98f2
https://github.com/RDFLib/rdflib/pull/2036
https://github.com/frostming/unearth/issues/14
https://github.com/pypa/distlib/commit/98b9b89f














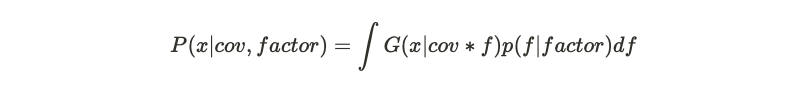 Here, x is the proposal sample, G represent Gaussian distribution,
Here, x is the proposal sample, G represent Gaussian distribution, 


 4 Aug 11, 2022
4 Aug 11, 2022
 7 Dec 28, 2022
7 Dec 28, 2022
 1.3k Jan 02, 2023
1.3k Jan 02, 2023
 1k Dec 09, 2022
1k Dec 09, 2022
 2 Nov 21, 2021
2 Nov 21, 2021
 27 Dec 30, 2022
27 Dec 30, 2022
 35 Dec 29, 2022
35 Dec 29, 2022
 16 Dec 17, 2022
16 Dec 17, 2022
 15 Oct 12, 2022
15 Oct 12, 2022
 16 Sep 15, 2022
16 Sep 15, 2022
 2.6k Dec 28, 2022
2.6k Dec 28, 2022
 4 May 18, 2022
4 May 18, 2022
 46 Sep 18, 2022
46 Sep 18, 2022
 12 Oct 11, 2022
12 Oct 11, 2022
 6 Feb 07, 2022
6 Feb 07, 2022
 5 Dec 14, 2021
5 Dec 14, 2021
 1 Jan 31, 2022
1 Jan 31, 2022
 2 Jul 30, 2022
2 Jul 30, 2022
 1 Jul 12, 2022
1 Jul 12, 2022
 10 Jul 19, 2022
10 Jul 19, 2022