ELSA: Enhanced Local Self-Attention for Vision Transformer
By Jingkai Zhou, Pichao Wang*, Fan Wang, Qiong Liu, Hao Li, Rong Jin
This repo is the official implementation of "ELSA: Enhanced Local Self-Attention for Vision Transformer".
Introduction
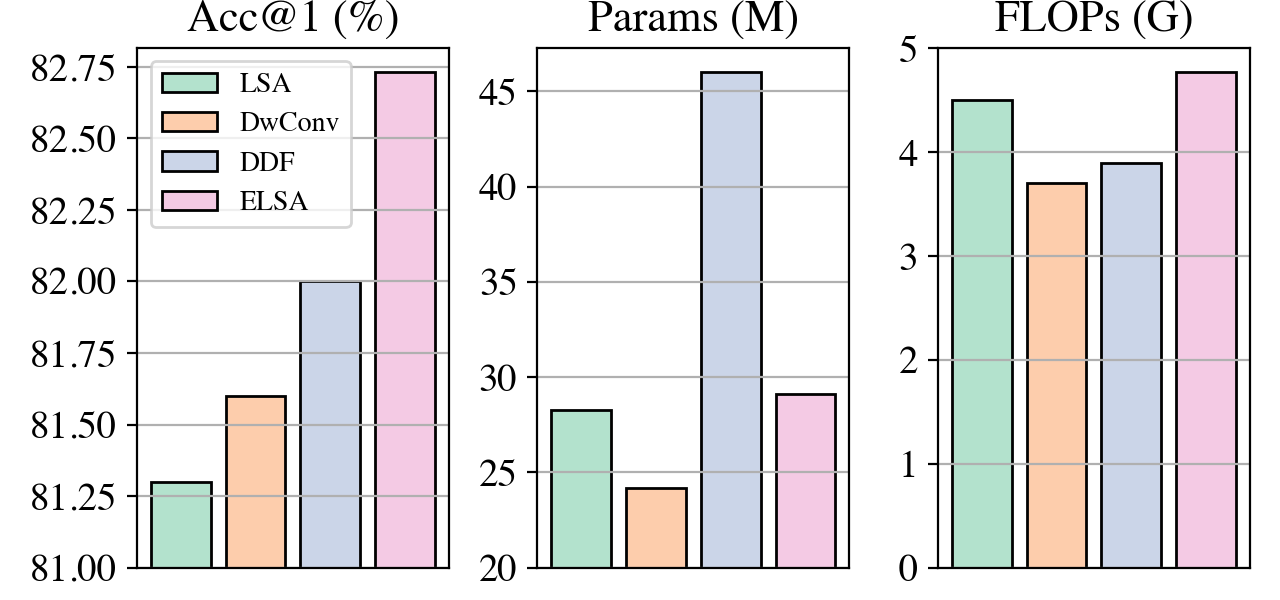
Self-attention is powerful in modeling long-range dependencies, but it is weak in local finer-level feature learning. As shown in Figure 1, the performance of local self-attention (LSA) is just on par with convolution and inferior to dynamic filters, which puzzles researchers on whether to use LSA or its counterparts, which one is better, and what makes LSA mediocre. In this work, we comprehensively investigate LSA and its counterparts. We find that the devil lies in the generation and application of spatial attention.
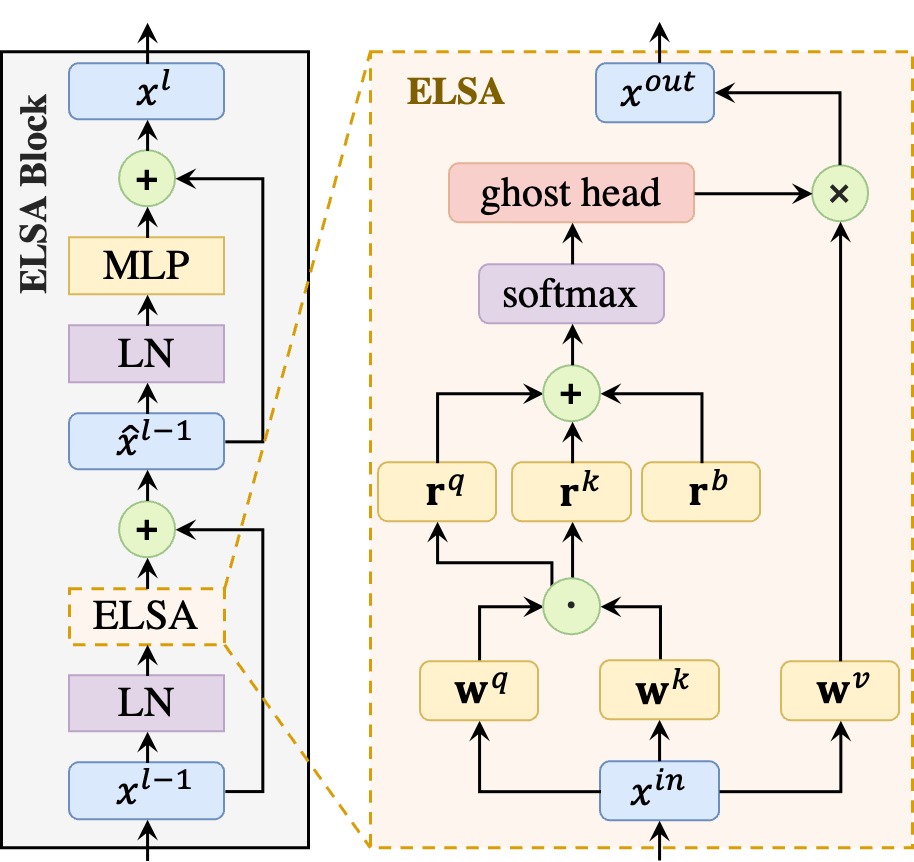
Based on these findings, we propose the enhanced local self-attention (ELSA) with Hadamard attention and the ghost head, as illustrated in Figure 2. Experiments demonstrate the effectiveness of ELSA. Without architecture / hyperparameter modification, The use of ELSA in drop-in replacement boosts baseline methods consistently in both upstream and downstream tasks.
Please refer to our paper for more details.
Model zoo
ImageNet Classification
| Model | #Params | Pretrain | Resolution | Top1 Acc | Download |
|---|---|---|---|---|---|
| ELSA-Swin-T | 28M | ImageNet 1K | 224 | 82.7 | google / baidu |
| ELSA-Swin-S | 53M | ImageNet 1K | 224 | 83.5 | google / baidu |
| ELSA-Swin-B | 93M | ImageNet 1K | 224 | 84.0 | google / baidu |
COCO Object Detection
| Backbone | Method | Pretrain | Lr Schd | Box mAP | Mask mAP | #Params | Download |
|---|---|---|---|---|---|---|---|
| ELSA-Swin-T | Mask R-CNN | ImageNet-1K | 1x | 45.7 | 41.1 | 49M | google / baidu |
| ELSA-Swin-T | Mask R-CNN | ImageNet-1K | 3x | 47.5 | 42.7 | 49M | google / baidu |
| ELSA-Swin-S | Mask R-CNN | ImageNet-1K | 1x | 48.3 | 43.0 | 72M | google / baidu |
| ELSA-Swin-S | Mask R-CNN | ImageNet-1K | 3x | 49.2 | 43.6 | 72M | google / baidu |
| ELSA-Swin-T | Cascade Mask R-CNN | ImageNet-1K | 1x | 49.8 | 43.0 | 86M | google / baidu |
| ELSA-Swin-T | Cascade Mask R-CNN | ImageNet-1K | 3x | 51.0 | 44.2 | 86M | google / baidu |
| ELSA-Swin-S | Cascade Mask R-CNN | ImageNet-1K | 1x | 51.6 | 44.4 | 110M | google / baidu |
| ELSA-Swin-S | Cascade Mask R-CNN | ImageNet-1K | 3x | 52.3 | 45.2 | 110M | google / baidu |
ADE20K Semantic Segmentation
| Backbone | Method | Pretrain | Crop Size | Lr Schd | mIoU (ms+flip) | #Params | Download |
|---|---|---|---|---|---|---|---|
| ELSA-Swin-T | UPerNet | ImageNet-1K | 512x512 | 160K | 47.9 | 61M | google / baidu |
| ELSA-Swin-S | UperNet | ImageNet-1K | 512x512 | 160K | 50.4 | 85M | google / baidu |
Install
- Clone this repo:
git clone https://github.com/damo-cv/ELSA.git elsa
cd elsa
- Create a conda virtual environment and activate it:
conda create -n elsa python=3.7 -y
conda activate elsa
- Install
PyTorch==1.8.0andtorchvision==0.9.0withCUDA==10.1:
conda install pytorch==1.8.0 torchvision==0.9.0 cudatoolkit=10.1 -c pytorch
-
Install
CUDA==10.1withcudnn7following the official installation instructions -
Install
Apex:
git clone https://github.com/NVIDIA/apex
cd apex
pip install -v --disable-pip-version-check --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
cd ../
- Install
mmcv-full==1.3.0
pip install mmcv-full==1.3.0 -f https://download.openmmlab.com/mmcv/dist/cu101/torch1.8.0/index.html
- Install other requirements:
pip install -r requirements.txt
- Install mmdet and mmseg:
cd ./det
pip install -v -e .
cd ../seg
pip install -v -e .
cd ../
- Build the elsa operation:
cd ./cls/models/elsa
python setup.py install
mv build/lib*/* .
cp *.so ../../../det/mmdet/models/backbones/elsa/
cp *.so ../../../seg/mmseg/models/backbones/elsa/
cd ../../../
Data preparation
We use standard ImageNet dataset, you can download it from http://image-net.org/. Please prepare it under the following file structure:
$ tree data
imagenet
├── train
│ ├── class1
│ │ ├── img1.jpeg
│ │ ├── img2.jpeg
│ │ └── ...
│ ├── class2
│ │ ├── img3.jpeg
│ │ └── ...
│ └── ...
└── val
├── class1
│ ├── img4.jpeg
│ ├── img5.jpeg
│ └── ...
├── class2
│ ├── img6.jpeg
│ └── ...
└── ...
Also, please prepare the COCO and ADE20K datasets following their links. Then, please link them to det/data and seg/data.
Evaluation
ImageNet Classification
Run following scripts to evaluate pre-trained models on the ImageNet-1K:
cd cls
python validate.py <PATH_TO_IMAGENET> --model elsa_swin_tiny --checkpoint <CHECKPOINT_FILE> \
--no-test-pool --apex-amp --img-size 224 -b 128
python validate.py <PATH_TO_IMAGENET> --model elsa_swin_small --checkpoint <CHECKPOINT_FILE> \
--no-test-pool --apex-amp --img-size 224 -b 128
python validate.py <PATH_TO_IMAGENET> --model elsa_swin_base --checkpoint <CHECKPOINT_FILE> \
--no-test-pool --apex-amp --img-size 224 -b 128 --use-ema
COCO Detection
Run following scripts to evaluate a detector on the COCO:
cd det
# single-gpu testing
python tools/test.py <CONFIG_FILE> <DET_CHECKPOINT_FILE> --eval bbox segm
# multi-gpu testing
tools/dist_test.sh <CONFIG_FILE> <DET_CHECKPOINT_FILE> <GPU_NUM> --eval bbox segm
ADE20K Semantic Segmentation
Run following scripts to evaluate a model on the ADE20K:
cd seg
# single-gpu testing
python tools/test.py <CONFIG_FILE> <SEG_CHECKPOINT_FILE> --aug-test --eval mIoU
# multi-gpu testing
tools/dist_test.sh <CONFIG_FILE> <SEG_CHECKPOINT_FILE> <GPU_NUM> --aug-test --eval mIoU
Training from scratch
Due to randomness, the re-training results may have a gap of about 0.1~0.2% with the numbers in the paper.
ImageNet Classification
Run following scripts to train classifiers on the ImageNet-1K:
cd cls
bash ./distributed_train.sh 8 <PATH_TO_IMAGENET> --model elsa_swin_tiny \
--epochs 300 -b 128 -j 8 --opt adamw --lr 1e-3 --sched cosine --weight-decay 5e-2 \
--warmup-epochs 20 --warmup-lr 1e-6 --min-lr 1e-5 --drop-path 0.1 --aa rand-m9-mstd0.5-inc1 \
--mixup 0.8 --cutmix 1. --remode pixel --reprob 0.25 --clip-grad 5. --amp
bash ./distributed_train.sh 8 <PATH_TO_IMAGENET> --model elsa_swin_small \
--epochs 300 -b 128 -j 8 --opt adamw --lr 1e-3 --sched cosine --weight-decay 5e-2 \
--warmup-epochs 20 --warmup-lr 1e-6 --min-lr 1e-5 --drop-path 0.3 --aa rand-m9-mstd0.5-inc1 \
--mixup 0.8 --cutmix 1. --remode pixel --reprob 0.25 --clip-grad 5. --amp
bash ./distributed_train.sh 8 <PATH_TO_IMAGENET> --model elsa_swin_base \
--epochs 300 -b 128 -j 8 --opt adamw --lr 1e-3 --sched cosine --weight-decay 5e-2 \
--warmup-epochs 20 --warmup-lr 1e-6 --min-lr 1e-5 --drop-path 0.5 --aa rand-m9-mstd0.5-inc1 \
--mixup 0.8 --cutmix 1. --remode pixel --reprob 0.25 --clip-grad 5. --amp --model-ema
If GPU memory is not enough when training elsa_swin_base, you can use two nodes (2 * 8 GPUs), each with a batch size of 64 images/GPU.
COCO Detection / ADE20K Semantic Segmentation
Run following scripts to train models on the COCO / ADE20K:
cd det
# (or cd seg)
# multi-gpu training
tools/dist_train.sh <CONFIG_FILE> <GPU_NUM> --cfg-options model.pretrained=<PRETRAIN_MODEL> [model.backbone.use_checkpoint=True] [other optional arguments]
Acknowledgement
This work was supported by Alibaba Group through Alibaba Research Intern Program and the National Natural Science Foundation of China (No.61976094).
Codebase from pytorch-image-models, ddfnet, VOLO, Swin-Transformer, Swin-Transformer-Detection, and Swin-Transformer-Semantic-Segmentation
Citing ELSA
@article{zhou2021ELSA,
title={ELSA: Enhanced Local Self-Attention for Vision Transformer},
author={Zhou, Jingkai and Wang, Pichao and Wang, Fan and Liu, Qiong and Li, Hao and Jin, Rong},
journal={arXiv preprint arXiv:2112.12786},
year={2021}
}

 3 Jun 09, 2022
3 Jun 09, 2022
 35 Nov 06, 2022
35 Nov 06, 2022
 4 May 30, 2022
4 May 30, 2022
 36 Oct 31, 2022
36 Oct 31, 2022
 36 Dec 02, 2022
36 Dec 02, 2022
 20 Nov 25, 2022
20 Nov 25, 2022
 13 Nov 23, 2022
13 Nov 23, 2022
 57 Dec 04, 2022
57 Dec 04, 2022
 1 Nov 24, 2021
1 Nov 24, 2021
 2k Jan 08, 2023
2k Jan 08, 2023
 769 Dec 25, 2022
769 Dec 25, 2022
 101 Dec 27, 2022
101 Dec 27, 2022
 1.4k Dec 28, 2022
1.4k Dec 28, 2022
 8.4k Dec 28, 2022
8.4k Dec 28, 2022
 2 Jul 06, 2022
2 Jul 06, 2022
 803 Jan 06, 2023
803 Jan 06, 2023
 65 Dec 22, 2022
65 Dec 22, 2022
 46 Dec 12, 2022
46 Dec 12, 2022
 2 Dec 12, 2022
2 Dec 12, 2022
 21 Dec 14, 2022
21 Dec 14, 2022