在线Markdown简历模板
本项目的markdown简历模引用自:https://github.com/CyC2018/Markdown-Resume 如果你只是想在本地使用这个模板,我推荐你看:https://github.com/CyC2018/Markdown-Resume#readme
拥有一台服务器后,我竟然这么酷?
一、前情回顾
在上一篇,我非常详细的给大家介绍了云服务器基本配置以及如何使用,并介绍了部分常用Linux指令,最后带大家一起部署了一个项目到服务器上。
不过由于阿里云服务器赠送查询项目源码没法直接给大家,所以本文将带大家用Python快速搭建一个web项目:个人简历。
注: 本文不涉及云服务器介绍、Linux指令介绍、项目部署到服务器等相关内容,还不知道这些的请看我写的云服务器第一篇文章:先导篇*跟老表学云服务器-拥有一台服务器后,我竟然这么酷?。
二、基础准备
如果想将本项目部署到服务器,必须先看:先导篇*跟老表学云服务器-拥有一台服务器后,我竟然这么酷?。
项目部署须知服务器环境介绍:
- 基本环境:Python 3.6及以上都可以
- 第三方库:
pipenv:虚拟环境管理库
pywebio:web项目框架
三、开始动手动脑
3.0 项目展示
3.1 项目思路
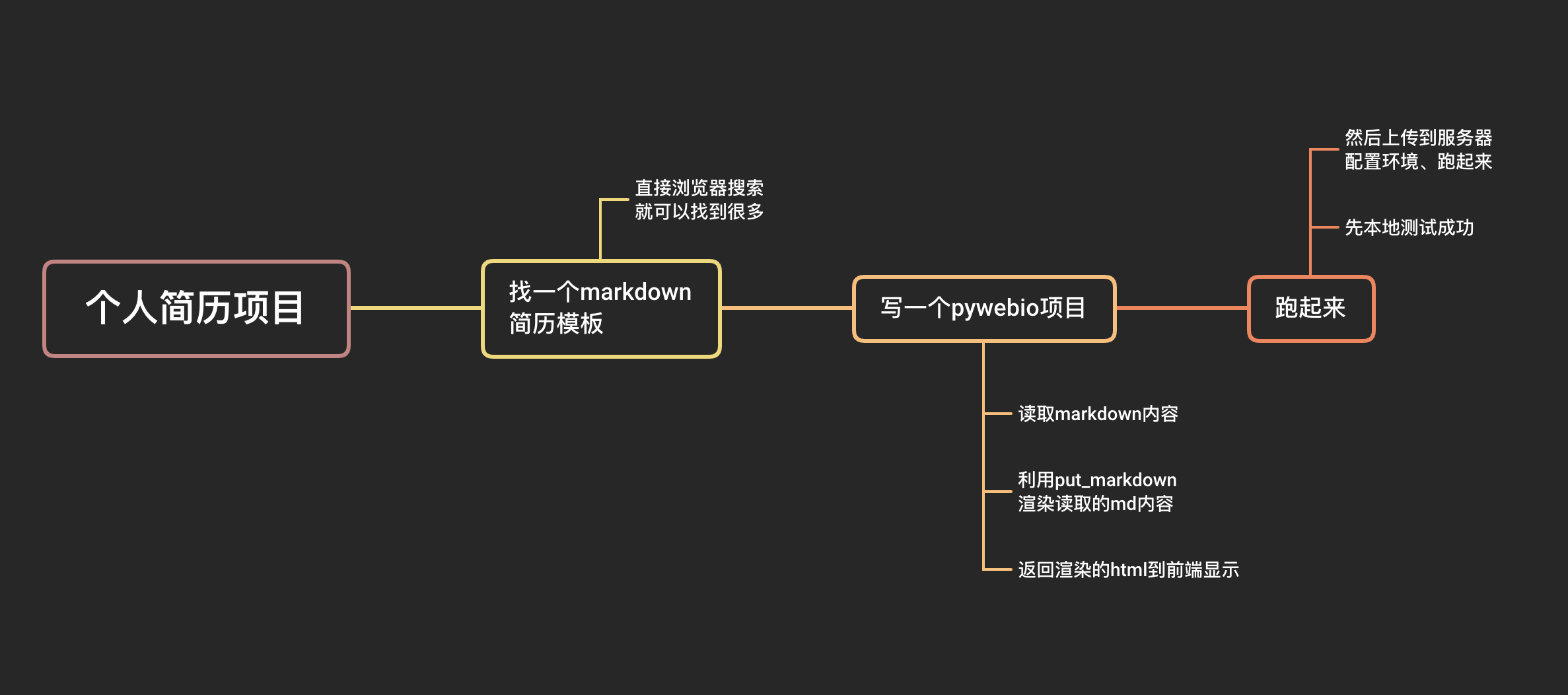
这次只有一个页面,就是:个人简历展示页面,本质上我们可以理解为一篇博客、静态文件等,和第一篇文章中一样,我们还是采用md来写,为什么我这么喜欢markdown:
- 更快的自定义内容格式
- 语法简单,写多了你会觉得他们就是一体的
- 移植性更强,只要在支持markdown的地方,你把你的内容复制过去,格式永远不会变(除非自己设置了css样式)

pywebio模块提供了渲染markdown语句的函数put_markdown,但是并没有提供直接渲染markdown文件的功能,一个个人简历md模板的内容就有72行了,要是直接作为参数传入函数,看代码的人得爆炸~(太乱了!)

所以我采用的方式是读取本地md文件成为字符串后传入put_markdown中进行渲染,这样代码看起来就会更可以维护、美观。
后端框架利用pywebio的好处,我们只用写好后端代码,该框架会帮我们渲染好前端显示页面,让编写者能快速搭建web项目,简直不要太nice~
3.2 找一个Markdown简历模板
这个其实很简单,直接浏览器搜索即可,你会发现第一个就是一个GitHub项目。
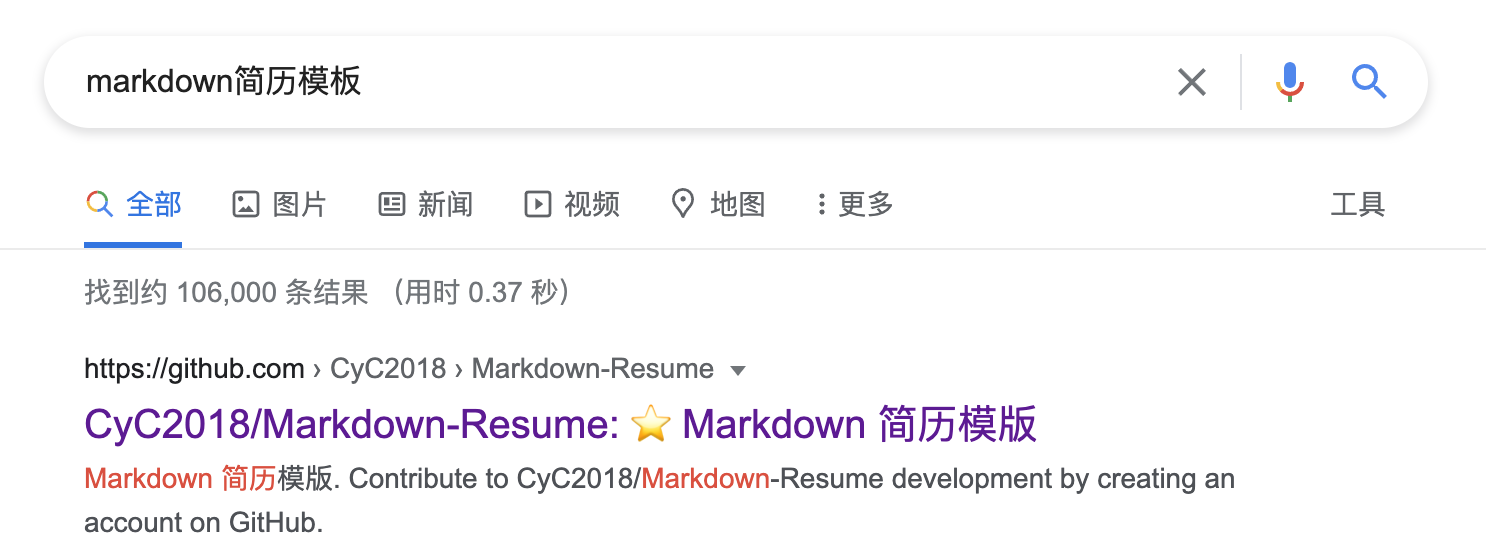
点开后,发现很符合我的期望,那么,我们就开始吧~
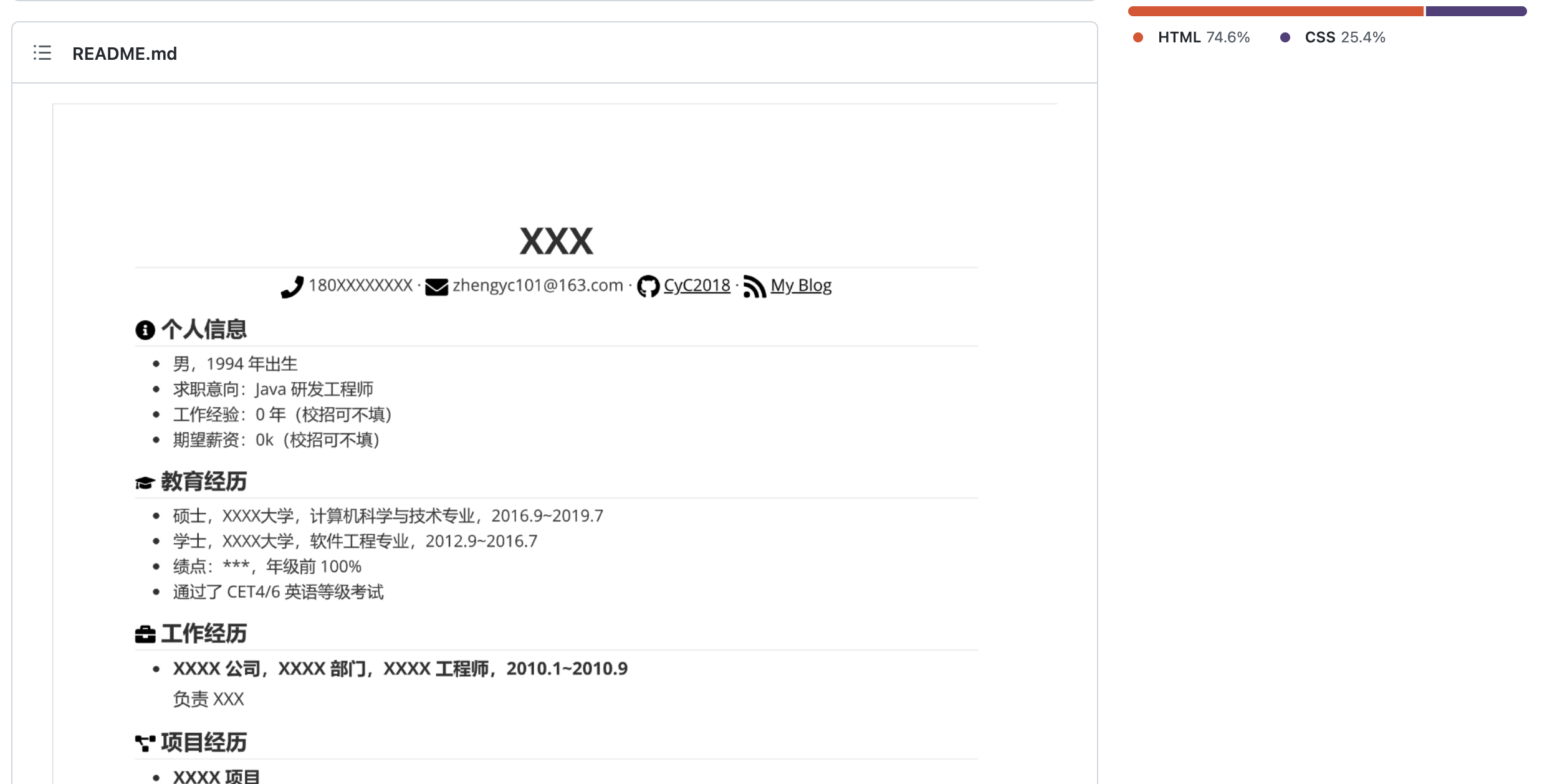
3.3 代码详解
整个项目只有10行,我们就能渲染出一个很不错的个人简历页面,太香了。
1)导入相关包
2行代码,其实只用到了pywebio这一个包,因为这个项目只涉及输出,所以只用导入pywebio.output中相关函数即可,另外导入了session(修改渲染相关设置)和start_server(启动服务)。
from pywebio import session, start_server
from pywebio.output import put_markdown
2)主页面函数
6行代码,定义了一个my_resume函数:
- 第1行代码:声明定义函数my_resume,pywebio中只用定义个函数就相当于创建了一个页面;
- 第2行代码:调用session.set_env自定义了页面title和取消输出过渡动画;
- 第3-4行代码:读取md内容,存储到md_txt变量内;
- 第5-6行代码:调用put_markdown渲染md内容。
def my_resume():
session.set_env(title='老表的简历', output_animation=False)
with open('resumeblog/Resume.md') as md:
md_txt = md.read()
put_markdown(md_txt)
put_markdown('
祝你求职成功,记得和老表一起学习云服务器!')
3)启动服务
2行代码,作为程序主入口,启动服务。
- 第1行代码:判断是否是主程序入口(从这个py文件开始执行的),如果是,就执行if内容,不是的话就不会执行。这样的好处是多个文件中相互调用测试时,不会重复执行代码;
- 第2行代码:调用start_server函数启动服务,传递了三个参数,第一个是页面函数名称;第二个是服务器启动在哪个端口;第三个是是否在程序运行后,自动打开浏览器访问页面。
if __name__ == '__main__':
start_server(my_resume, port=8081, auto_open_webbrowser=True)
四、下期预告
如果你还完全不了解服务器和Linux相关知识,推荐你看这篇文章
后面就正式开始系统的云服务器学习教程更新啦(应该也不系统,就是我想到哪里、觉得哪里有必要、可以讲讲,我就分享出来,等整个系列更新完成应该就可以很系统了)
这个过程也希望大家多多支持,多多反馈,互相鞭策~
我们下期见!
本项目源码地址:https://github.com/XksA-me/resumeblog
如何找到我:


 352 Dec 19, 2022
352 Dec 19, 2022
 117 Dec 29, 2022
117 Dec 29, 2022
 1.8k Jan 08, 2023
1.8k Jan 08, 2023
 1 Jan 17, 2022
1 Jan 17, 2022
 2 Dec 14, 2022
2 Dec 14, 2022
 5 Jul 26, 2022
5 Jul 26, 2022
 1 Oct 20, 2021
1 Oct 20, 2021
 9 Jan 07, 2023
9 Jan 07, 2023
 1 Nov 26, 2021
1 Nov 26, 2021
 8 May 07, 2022
8 May 07, 2022
 64 Dec 25, 2022
64 Dec 25, 2022
 19 Dec 26, 2022
19 Dec 26, 2022
 1.3k Jan 04, 2023
1.3k Jan 04, 2023
 252 Dec 31, 2022
252 Dec 31, 2022
 13 Nov 22, 2022
13 Nov 22, 2022
 1 Jan 02, 2022
1 Jan 02, 2022
 1 Jan 29, 2022
1 Jan 29, 2022
 5 Oct 28, 2022
5 Oct 28, 2022
 14 Oct 14, 2022
14 Oct 14, 2022
 3.1k Dec 29, 2022
3.1k Dec 29, 2022