VoV3D
VoV3D is an efficient and effective 3D backbone network for temporal modeling implemented on top of PySlowFast.
Diverse Temporal Aggregation and Depthwise Spatiotemporal Factorization for Efficient Video Classification
Youngwan Lee, Hyung-Il Kim, Kimin Yun, and Jinyoung Moon
Electronics and Telecommunications Research Institute (ETRI)
pre-print : https://arxiv.org/abs/2012.00317
Abstract
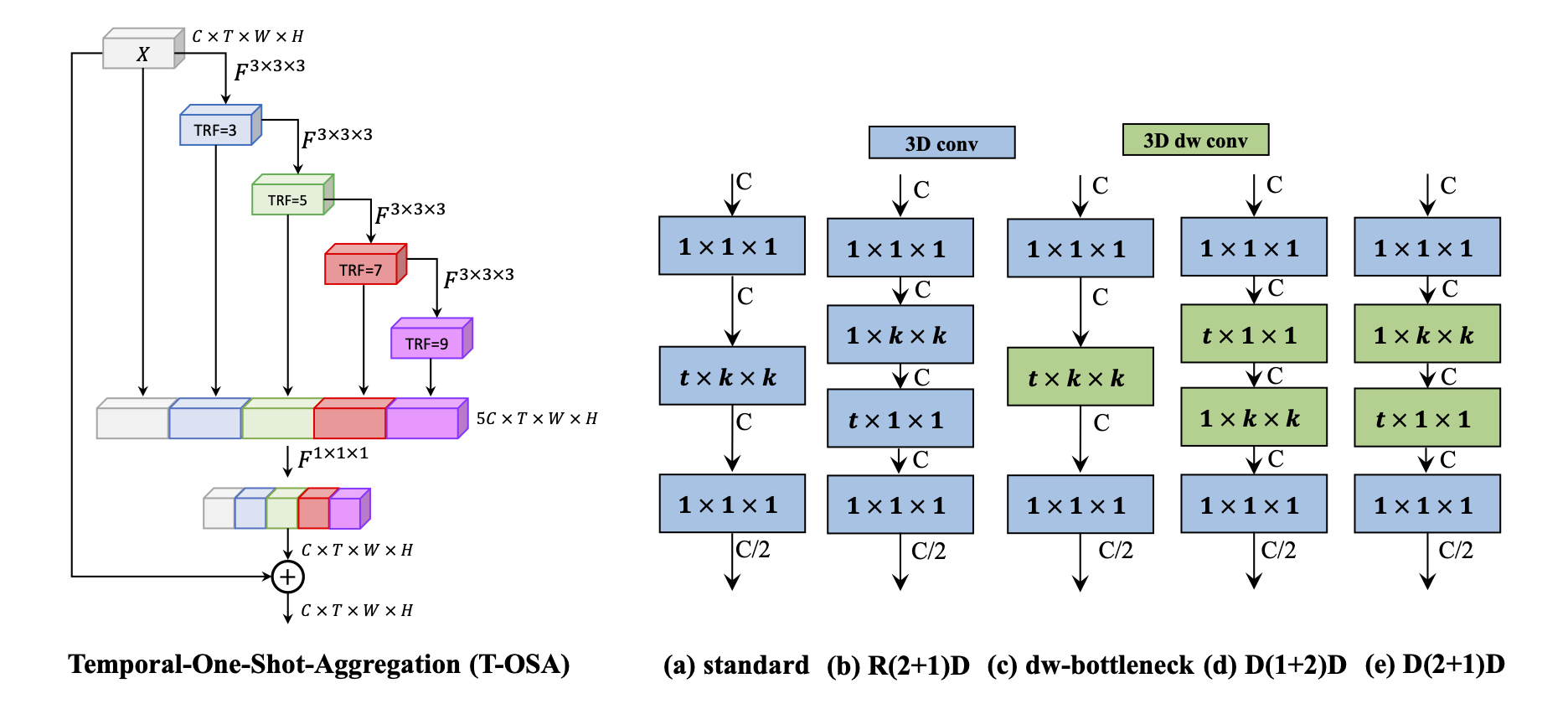
Video classification researches that have recently attracted attention are the fields of temporal modeling and 3D efficient architecture. However, the temporal modeling methods are not efficient or the 3D efficient architecture is less interested in temporal modeling. For bridging the gap between them, we propose an efficient temporal modeling 3D architecture, called VoV3D, that consists of a temporal one-shot aggregation (T-OSA) module and depthwise factorized component, D(2+1)D. The T-OSA is devised to build a feature hierarchy by aggregating temporal features with different temporal receptive fields. Stacking this T-OSA enables the network itself to model short-range as well as long-range temporal relationships across frames without any external modules. Inspired by kernel factorization and channel factorization, we also design a depthwise spatiotemporal factorization module, named, D(2+1)D that decomposes a 3D depthwise convolution into two spatial and temporal depthwise convolutions for making our network more lightweight and efficient. By using the proposed temporal modeling method (T-OSA), and the efficient factorized component (D(2+1)D), we construct two types of VoV3D networks, VoV3D-M and VoV3D-L. Thanks to its efficiency and effectiveness of temporal modeling, VoV3D-L has 6x fewer model parameters and 16x less computation, surpassing a state-of-the-art temporal modeling method on both Something-Something and Kinetics-400. Furthermore, VoV3D shows better temporal modeling ability than a state-of-the-art efficient 3D architecture, X3D having comparable model capacity. We hope that VoV3D can serve as a baseline for efficient video classification.
Main Result
Our results (X3D & VoV3D) are trained in the same environment.
- V100 8 GPU machine
- same training protocols (BASE_LR, LR_POLICY, batch size, etc)
- pytorch 1.6
- CUDA 10.1
*Please refer to our paper or configs files for the details.
*When you want to reproduce the same results, you just train the model with configs on the 8 GPU machine. If you change NUM_GPUS or TRAIN.BATCH_SIZE values, you have to adjust BASE_LR.
*IM and K-400 denote ImageNet and Kinetics-400, respectively.
Something-Something-V1
| Model | Backbone | Pretrain | #Frame | Param. | GFLOPs | Top-1 | Top-5 | weight |
|---|---|---|---|---|---|---|---|---|
| TSM | R-50 | K-400 | 16 | 24.3M | 33x6 | 48.3 | 78.1 | link |
| TSM+TPN | R-50 | IM | 8 | N/A | N/A | 50.7 | - | link |
| TEA | R-50 | IM | 16 | 24.4M | 70x30 | 52.3 | 81.9 | - |
| ip-CSN-152 | - | - | 32 | 29.7M | 74.0x10 | 49.3 | - | - |
| X3D | M | - | 16 | 3.3M | 6.1x6 | 46.4 | 75.3 | link |
| VoV3D | M | - | 16 | 3.3M | 5.7x6 | 48.1 | 76.9 | link |
| VoV3D | M | - | 32 | 3.3M | 11.5x6 | 49.8 | 78.0 | link |
| VoV3D | M | K-400 | 32 | 3.3M | 11.5x6 | 52.6 | 80.4 | link |
| X3D | L | - | 16 | 5.6M | 9.1x6 | 47.0 | 76.4 | link |
| VoV3D | L | - | 16 | 5.8M | 9.3x6 | 49.5 | 78.0 | link |
| VoV3D | L | - | 32 | 5.8M | 20.9x6 | 50.6 | 78.7 | link |
| VoV3D | L | K-400 | 32 | 5.8M | 20.9x6 | 54.9 | 82.3 | link |
Something-Something-V2
| Model | Backbone | Pretrain | #Frame | Param. | GFLOPs | Top-1 | Top-5 | weight |
|---|---|---|---|---|---|---|---|---|
| TSM | R-50 | K-400 | 16 | 24.3M | 33x6 | 63.0 | 88.1 | link |
| TSM+TPN | R-50 | IM | 8 | N/A | N/A | 64.7 | - | link |
| TEA | R-50 | IM | 16 | 24.4M | 70x30 | 65.1 | 89.9 | - |
| SlowFast 16x8 | R-50 | K-400 | 64 | 34.0M | 131.4x6 | 63.9 | 88.2 | link |
| X3D | M | - | 16 | 3.3M | 6.1x6 | 63.0 | 87.9 | link |
| VoV3D | M | - | 16 | 3.3M | 5.7x6 | 63.2 | 88.2 | link |
| VoV3D | M | - | 32 | 3.3M | 11.5x6 | 64.2 | 88.8 | link |
| VoV3D | M | K-400 | 32 | 3.3M | 11.5x6 | 65.2 | 89.4 | link |
| X3D | L | - | 16 | 5.6M | 9.1x6 | 62.7 | 87.7 | link |
| VoV3D | L | - | 16 | 5.8M | 9.3x6 | 64.1 | 88.6 | link |
| VoV3D | L | - | 32 | 5.8M | 20.9x6 | 65.8 | 89.5 | link |
| VoV3D | L | K-400 | 32 | 5.8M | 20.9x6 | 67.3 | 90.5 | link |
Kinetics-400
| Model | Backbone | Pretrain | #Frame | Param. | GFLOPs | Top-1 | Top-5 | weight |
|---|---|---|---|---|---|---|---|---|
| X3D (PySlowFast, 300e) | M | - | 16 | 3.8M | 6.2x30 | 76.0 | 92.3 | link |
| X3D (our, 256e) | M | - | 16 | 3.8M | 6.2x30 | 75.0 | 92.1 | link |
| VoV3D | M | - | 16 | 3.8M | 4.4x30 | 73.9 | 91.6 | link |
| X3D (PySlowfast) | L | - | 16 | 6.1M | 24.8x30 | 77.5 | 92.9 | link |
| VoV3D | L | - | 16 | 6.2M | 9.3x30 | 76.3 | 92.9 | link |
*We note that since X3D-M (PySlowFast) was trained for 300 epochs, we re-train the X3D-M (our, 256e) with the same 256 epochs with VoV3D-M.
Installation & Data Preparation
Please refer to INSTALL.md for installation and DATA.md for data preparation.
Important : We used depthwise 3D Conv pytorch patch for accelearating GPU runtime.
Training & Evaluation
We provide brief examples for getting started. If you want to know more details, please refer to instruction of PySlowFast.
Training
from scratch
- VoV3D-L on Kinetics-400
python tools/run_net.py \
--cfg configs/Kinetics/vov3d/vov3d_L.yaml \
DATA.PATH_TO_DATA_DIR path/to/your/kinetics \
NUM_GPUS 8 \
TRAIN.BATCH_SIZE 64
You can also designate each argument in the config file. If you want to train with our default setting (e.g., 8GPUs, 64 batch size, etc), you just use this command. (Set DATA.PATH_TO_DATA_DIR with your real data path)
python tools/run_net.py --cfg configs/Kinetics/vov3d/vov3d_L.yaml
- VoV3D-L on Something-Something-V1
python tools/run_net.py \
--cfg configs/SSv1/vov3d/vov3d_L_F16.yaml \
DATA.PATH_TO_DATA_DIR path/to/your/ssv1 \
DATA.PATH_PREFIX path/to/your/ssv1
Finetuning by using Kinetics-400 pretrained weight.
First, you have to download the weights pretrained on Kinetics-400.
One thing you should keep in mind is that TRAIN.CHECKPOINT_FILE_PATH is the downloaded weight.
For Something-Something-V2,
cd VoV3D
mkdir -p output/pretrained
wget https://dl.dropbox.com/s/lzmq8d4dqyj8fj6/vov3d_L_k400.pth
python tools/run_net.py \
--cfg configs/SSv2/vov3d/finetune/vov3d_L_F16.yaml \
TRAIN.CHECKPOINT_FILE_PATH path/to/the/pretrained/vov3d_L_k400.pth \
DATA.PATH_TO_DATA_DIR path/to/your/ssv2 \
DATA.PATH_PREFIX path/to/your/ssv2
Testing
When testing, you have to set TRAIN.ENABLE to False and TEST.CHECKPOINT_FILE_PATH to path/to/your/checkpoint.
python tools/run_net.py \
--cfg configs/Kinetics/vov3d/vov3d_L.yaml \
TRAIN.ENABLE False \
TEST.CHECKPOINT_FILE_PATH path_to_your_checkpoint
If you want to test with single clip and single-crop, set TEST.NUM_ENSEMBLE_VIEWS and TEST.NUM_SPATIAL_CROPS to 1, respectively.
python tools/run_net.py \
--cfg configs/Kinetics/vov3d/vov3d_L.yaml \
TRAIN.ENABLE False \
TEST.CHECKPOINT_FILE_PATH path_to_your_checkpoint \
TEST.NUM_ENSEMBLE_VIEWS 1 \
TEST.NUM_SPATIAL_CROPS 1
For Kinetics-400, 30-views : TEST.NUM_ENSEMBLE_VIEWS 10 & TEST.NUM_SPATIAL_CROPS 3
For Something-Something, 6-views : TEST.NUM_ENSEMBLE_VIEWS 2 & TEST.NUM_SPATIAL_CROPS 3
License
The code and the models in this repo are released under the CC-BY-NC4.0 LICENSE. See the LICENSE file.
Citing VoV3D
@article{lee2020vov3d,
title={Diverse Temporal Aggregation and Depthwise Spatiotemporal Factorization for Efficient Video Classification},
author={Lee, Youngwan and Kim, Hyung-Il and Yun, Kimin and Moon, Jinyoung},
journal={arXiv preprint arXiv:2012.00317},
year={2020}
}
@inproceedings{lee2019energy,
title = {An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection},
author = {Lee, Youngwan and Hwang, Joong-won and Lee, Sangrok and Bae, Yuseok and Park, Jongyoul},
booktitle = {CVPR Workshop},
year = {2019}
}
@inproceedings{lee2020centermask,
title={CenterMask: Real-Time Anchor-Free Instance Segmentation},
author={Lee, Youngwan and Park, Jongyoul},
booktitle={CVPR},
year={2020}
}
Acknowledgement
We appreciate developers of PySlowFast for such wonderful framework.
This work was supported by Institute of Information & Communications Technology Planning & Evaluation (IITP) grant funded by the Korea government (MSIT) (No. B0101-15-0266, Development of High Performance Visual BigData Discovery Platform for Large-Scale Realtime Data Analysis and No. 2020-0-00004, Development of Previsional Intelligence based on Long-term Visual Memory Network).

 49 Jan 03, 2023
49 Jan 03, 2023
 583 Jan 03, 2023
583 Jan 03, 2023
 583 Dec 30, 2022
583 Dec 30, 2022
 92 Jan 03, 2023
92 Jan 03, 2023
 79 Nov 04, 2022
79 Nov 04, 2022
 25 Dec 17, 2022
25 Dec 17, 2022
 0 Nov 17, 2022
0 Nov 17, 2022
 1 Dec 26, 2021
1 Dec 26, 2021
 88 Dec 27, 2022
88 Dec 27, 2022
 3.6k Jan 05, 2023
3.6k Jan 05, 2023
 708 Jan 01, 2023
708 Jan 01, 2023
 361 Dec 12, 2022
361 Dec 12, 2022
 7 Dec 30, 2022
7 Dec 30, 2022
 3.8k Dec 30, 2022
3.8k Dec 30, 2022
 569 Dec 29, 2022
569 Dec 29, 2022
 3 Mar 01, 2022
3 Mar 01, 2022
 11 Sep 10, 2022
11 Sep 10, 2022
 16 Nov 22, 2022
16 Nov 22, 2022
 7.9k Jan 08, 2023
7.9k Jan 08, 2023
 13 Dec 13, 2022
13 Dec 13, 2022