Rent Houses Germany - GCP Pipeline

Project:
- The goal of the project is to extract data about house rentals in Germany, store, process and analyze it using GCP tools. The focus here is to practice and get used to the GCP environment.
Main Tools:
Python |
Cloud Storage |
BigQuery |
Dataprep |
Data Studio |
Looker |
Crontab |
Bash |
Data Extraction and Storage:
Source: https://www.immonet.de/
-
The data extraction is done in 3 steps where first the quantity of offers for each city is collected, them the ID's for each offers and finaly the raw information about each rent offer is extracted.
-
The first script is responsible to scrape the number of offers in each city and save the information as a CSV file in Cloud Storage. The second script gets the previous CSV file from Cloud Storage and uses it to scrape all ID's from each offers in each city and load the information back to Cloud Storage as a new CSV file. The third script gets the rent offer's ID info from Cloud Storage and perform a web-scraper to collect all information for each ID and save it back to Cloud Storage, again as a CSV file containing all raw infos about the offers.
-
All the extractions steps are scheduled though a Crontab Job to run everyday at 0h.

Data Preprocessing.
- As the last CSV file contains all the RAW information about each offer grouped in only two columns, a preprocessing step is needed. The preprocessor script gets the CSV file with the raw information from Cloud Storage, separates the data into the appropriate columns already performing some cleaning like excluding not needed characters. Again, the preprocessed CSV file is stored in Cloud Storage.
all_offers_infos_raw.csv:

all_offers_infos_pp.csv:

Data Cleaning and Preparation.
- Here is used Cloud Dataprep to clean and prepare the data for further use. To transform the rent data into useble information first we need to clean and prepare it. Dataprep is a realy good tool where we can look inside the data and can perform all kind of filtering, removing and preparations. Dataprep gets the preprocessed csv file from Cloud Storage and runs a "recipe" tranforming the data to be analyzed. Dataprep saves the cleaned and final csv file both into Data Storage (a backup) and into a BigQuery warehouse.
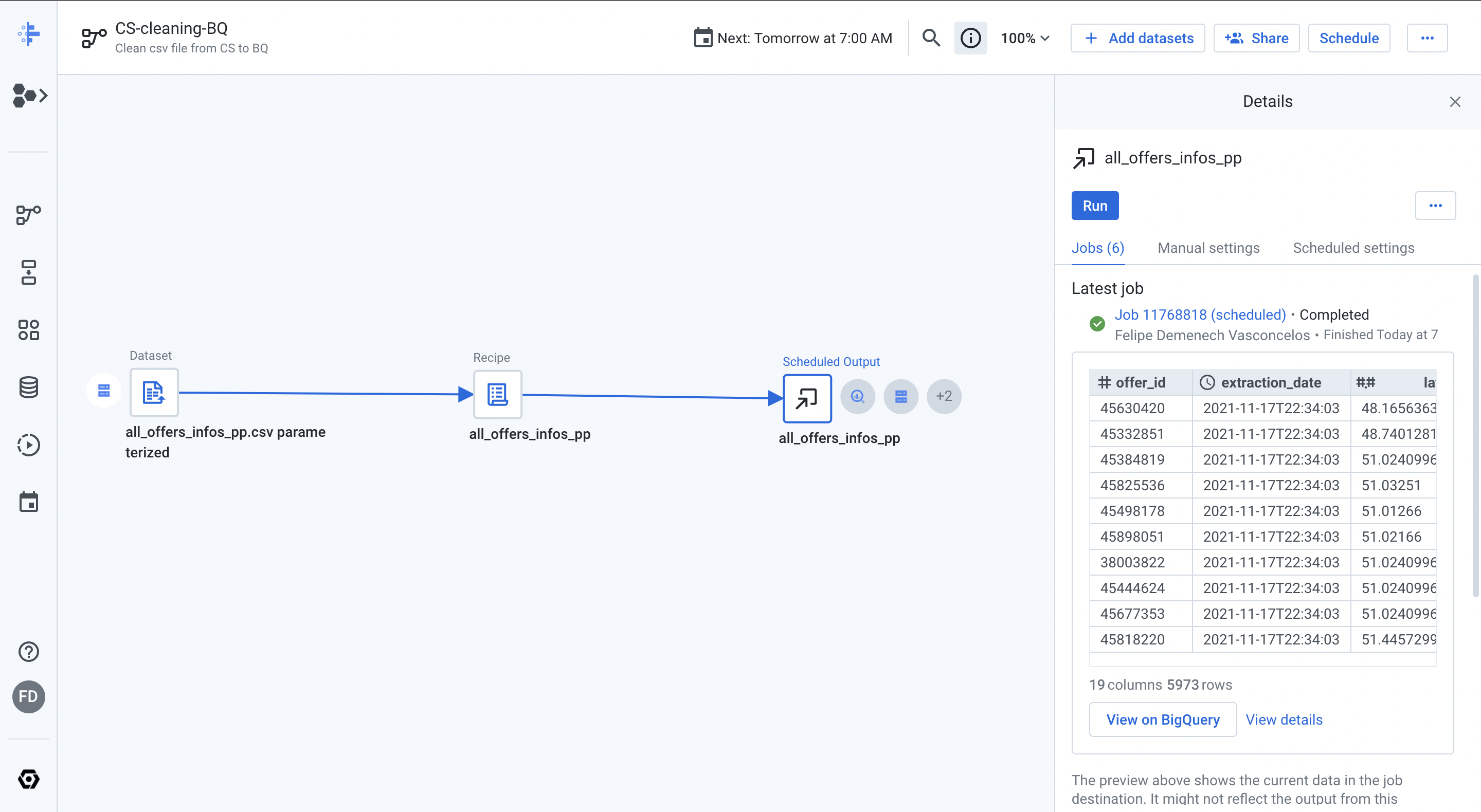
- The Dataproc job was scheduled to run everyday 7 A.M and update the data source for the reports.
Data Analysis - Data Studio Report.
-
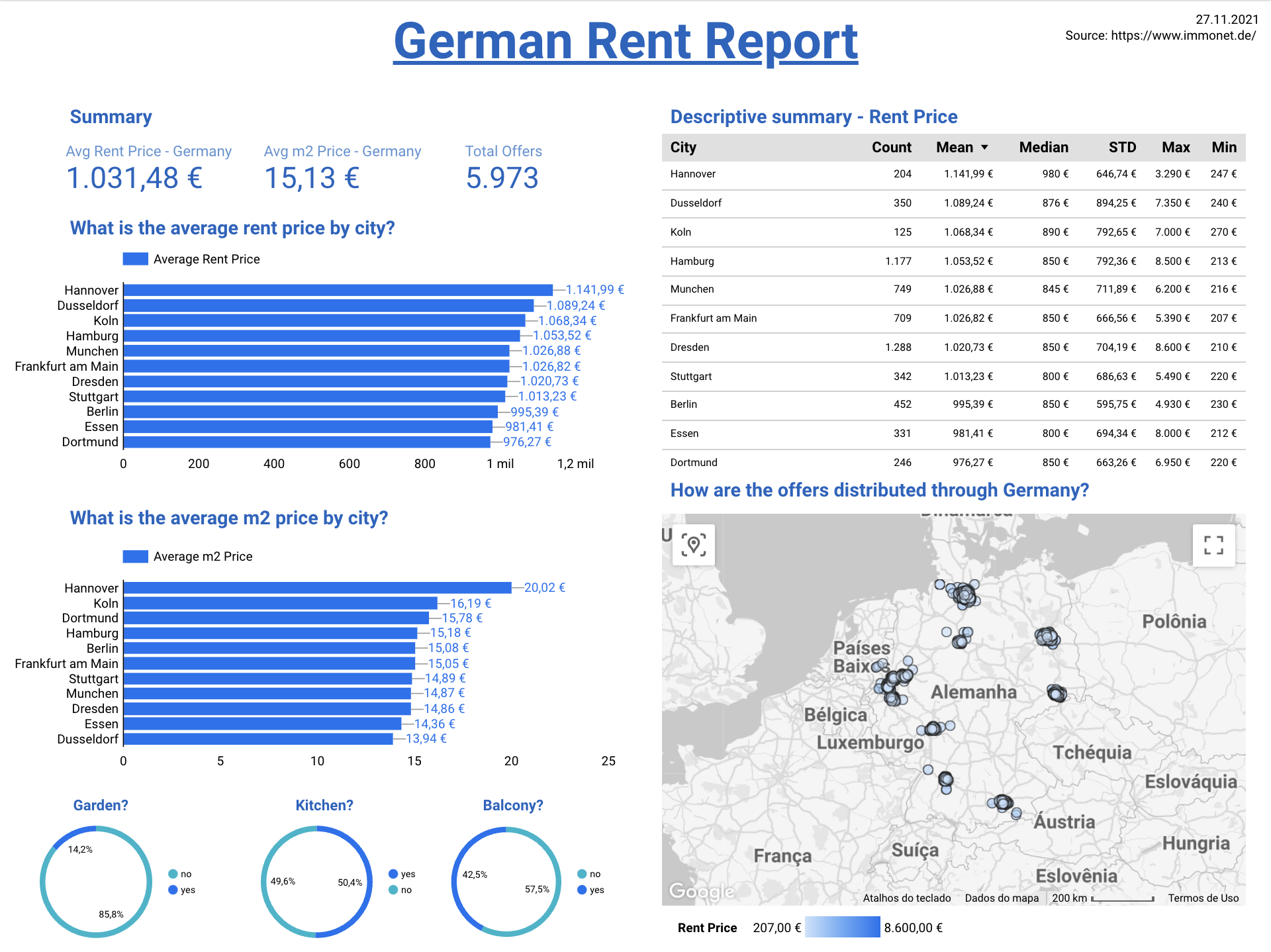
With the data cleaned and loaded into BigQuery it's time to display the information. The GCP tools used to display the data was Data Studio and Looker. First I used Data Studio to make a simple report summaring all the rent houses main informantion and schedule to send an e-mail with the updated report avery day at 8 A.M.

Data Analysis - Looker Dashboard.
- I'm still working on it.
Conclusion.
- The tools available on Google Cloud Platform are simply amazing. As in all Cloud platforms, the tools are available and are arranged in a way to make the user's life easier, it is really cool and very practical to build an entire ETL/ELT process using the available tools and it makes everything much easier and agile. The fact that you don't have to deal with hardware fiscally, the automated scalability, the advanced security controls, the availability of virtually all the necessary tools in one place, the integration between the tools, and all the other characteristics of cloud environments contribute greatly to the considerable increase in productivity, in environments like these we only need to focus on doing the main part of our job, on delivering the result, and that is amazing. For me it has been a very pleasant experience to work and experience these features, the next steps now are to continue learning and applying them and in the future to seek certifications.

 0 Jan 26, 2022
0 Jan 26, 2022
 229 Dec 29, 2022
229 Dec 29, 2022
 2 Jun 17, 2022
2 Jun 17, 2022
 5 Jan 03, 2023
5 Jan 03, 2023
 2 Feb 14, 2022
2 Feb 14, 2022
 3.3k Jan 04, 2023
3.3k Jan 04, 2023
 18 Nov 28, 2022
18 Nov 28, 2022
 1 Nov 18, 2021
1 Nov 18, 2021
 861 Dec 29, 2022
861 Dec 29, 2022
 1 Jan 11, 2022
1 Jan 11, 2022
 1 Jul 27, 2022
1 Jul 27, 2022
 9 Nov 16, 2022
9 Nov 16, 2022
 1.3k Dec 30, 2022
1.3k Dec 30, 2022
 0 Dec 22, 2021
0 Dec 22, 2021
 2 Nov 18, 2022
2 Nov 18, 2022
 14 Jun 22, 2022
14 Jun 22, 2022
 2 Feb 10, 2022
2 Feb 10, 2022
 42 Nov 09, 2022
42 Nov 09, 2022
 1.2k Jan 07, 2023
1.2k Jan 07, 2023
 38 Dec 03, 2022
38 Dec 03, 2022