MixFaceNets
This is the official repository of the paper: MixFaceNets: Extremely Efficient Face Recognition Networks.
(Accepted in IJCB2021) https://ieeexplore.ieee.org/abstract/document/9484374
| Model | MFLOPs | Params (M) | LFW% | AgeDB-30% | IJB-B( TAR at FAR1e–6) | IJB-C( TAR at FAR1e–6) | Pretrained model |
|---|---|---|---|---|---|---|---|
| MixFaceNet-M | 626.1 | 3.95 | 99.68 | 97.05 | 91.55 | 93.42 | pretrained-mode |
| ShuffleMixFaceNet-M | 626.1 | 3.95 | 99.60 | 96.98 | 91.47 | 93.5 | pretrained-mode |
| MixFaceNet-S | 451.7 | 3.07 | 99.60 | 96.63 | 90.17 | 92.30 | pretrained-mode |
| ShuffleMixFaceNet-S | 451.7 | 3.07 | 99.58 | 97.05 | 90.94 | 93.08 | pretrained-mode |
| MixFaceNet-XS | 161.9 | 1.04 | 99.60 | 95.85 | 88.48 | 90.73 | pretrained-mode |
| ShuffleMixFaceNet-XS | 161.9 | 1.04 | 99.53 | 95.62 | 87.86 | 90.43 | pretrained-mode |
FLOPs vs. performance on LFW (accuracy), AgeDB-30 (accuracy), MegaFace (TAR at FAR1e-6), IJB-B (TAR at FAR1e-4), IJB-C (TAR at FAR1e-4) and refined version of MegaFace, noted as MegaFace (R), (TAR at FAR1e-6). Our MixFaceNet models are highlighted with triangle marker and red edge color.
LFW 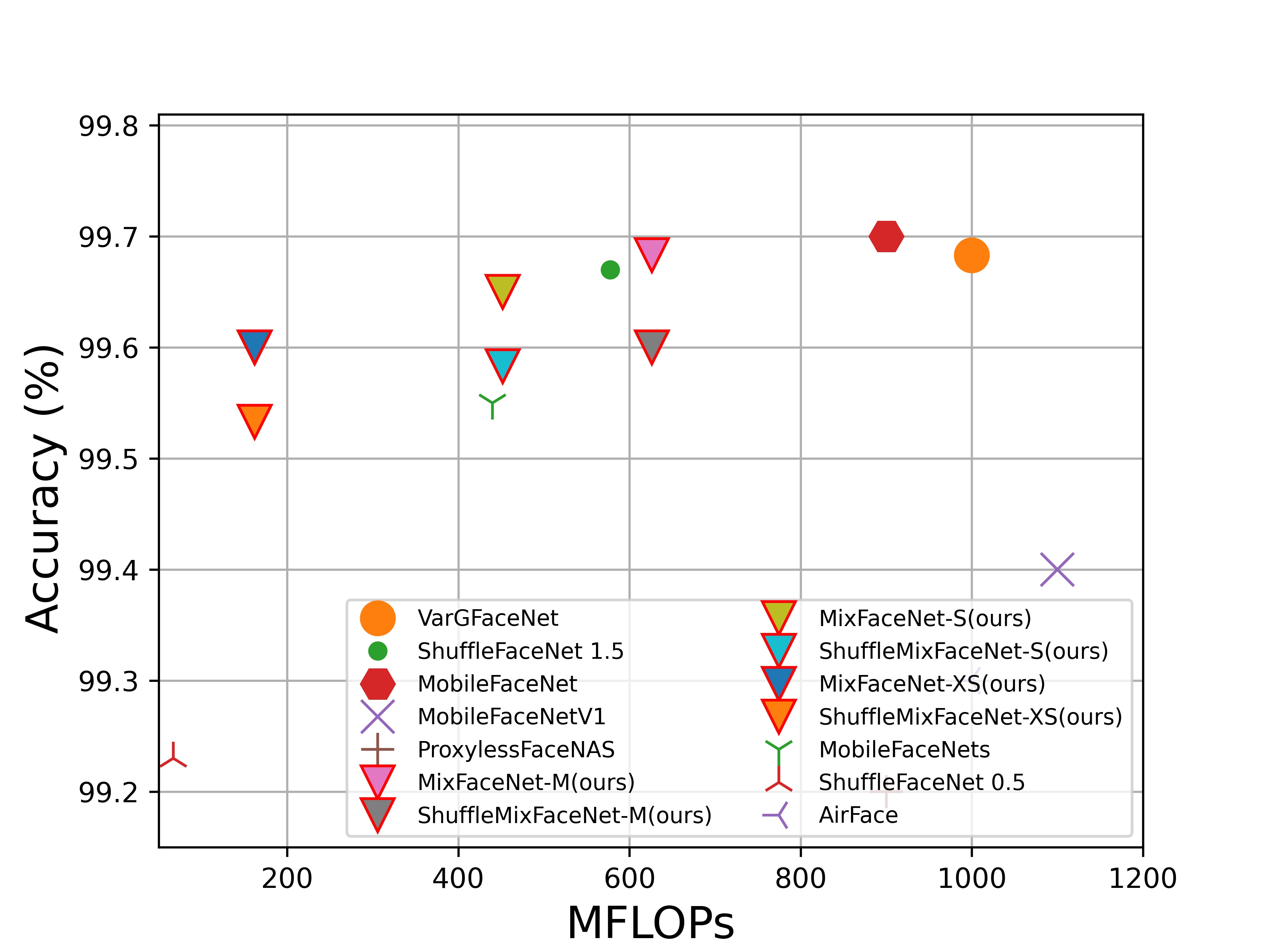
AgeDb-30 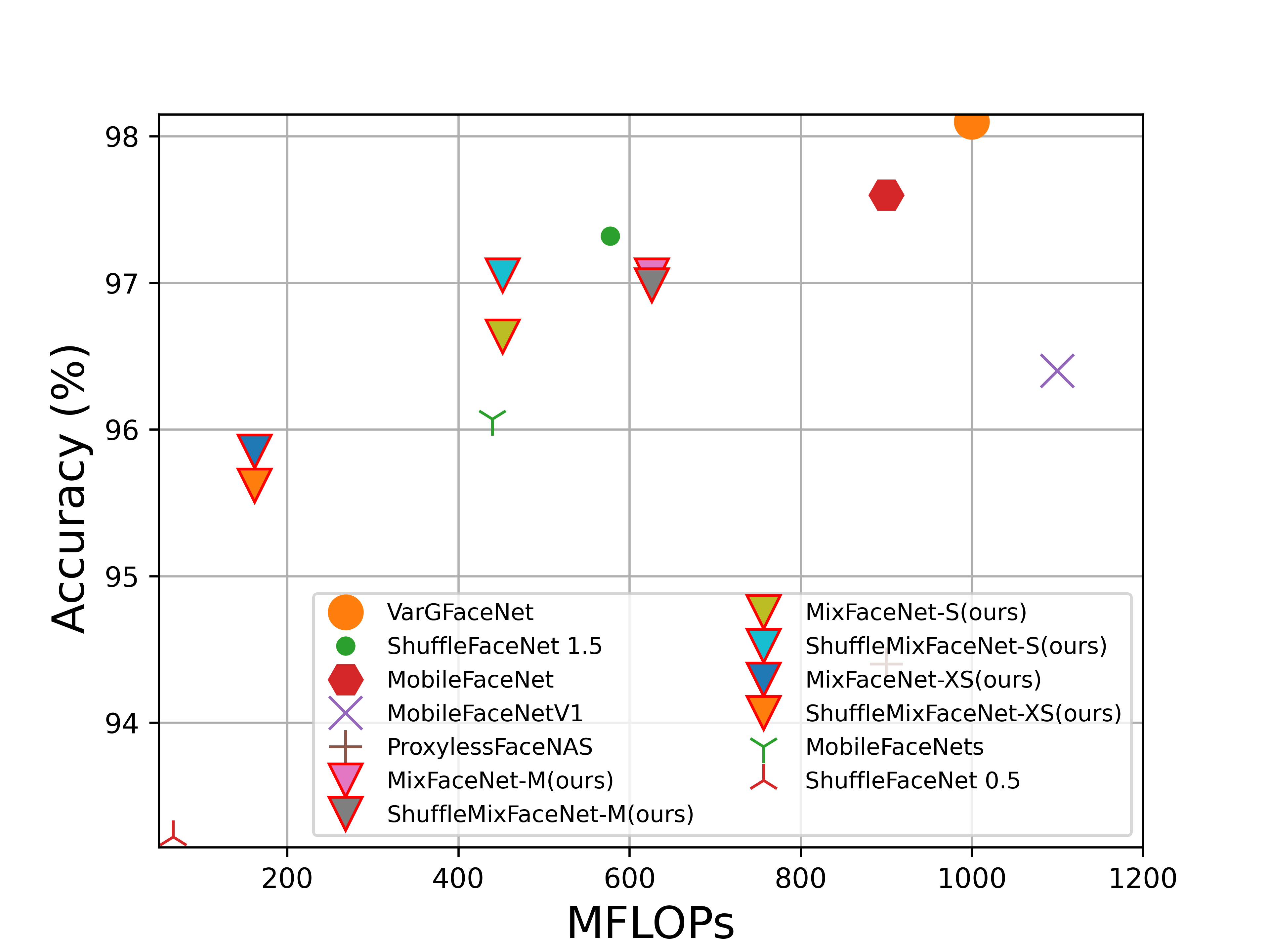
MegaFace 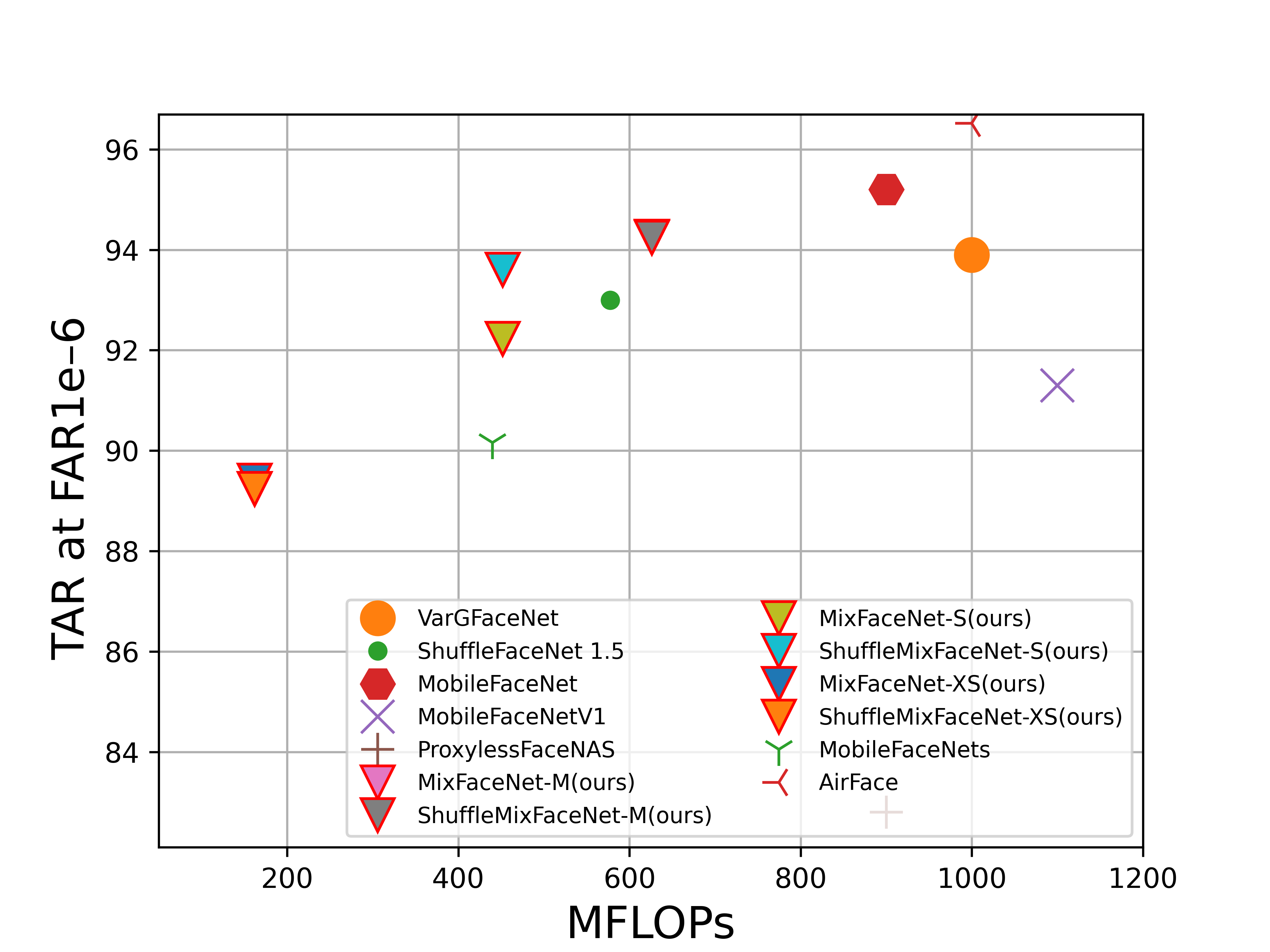
MegaFace(R) 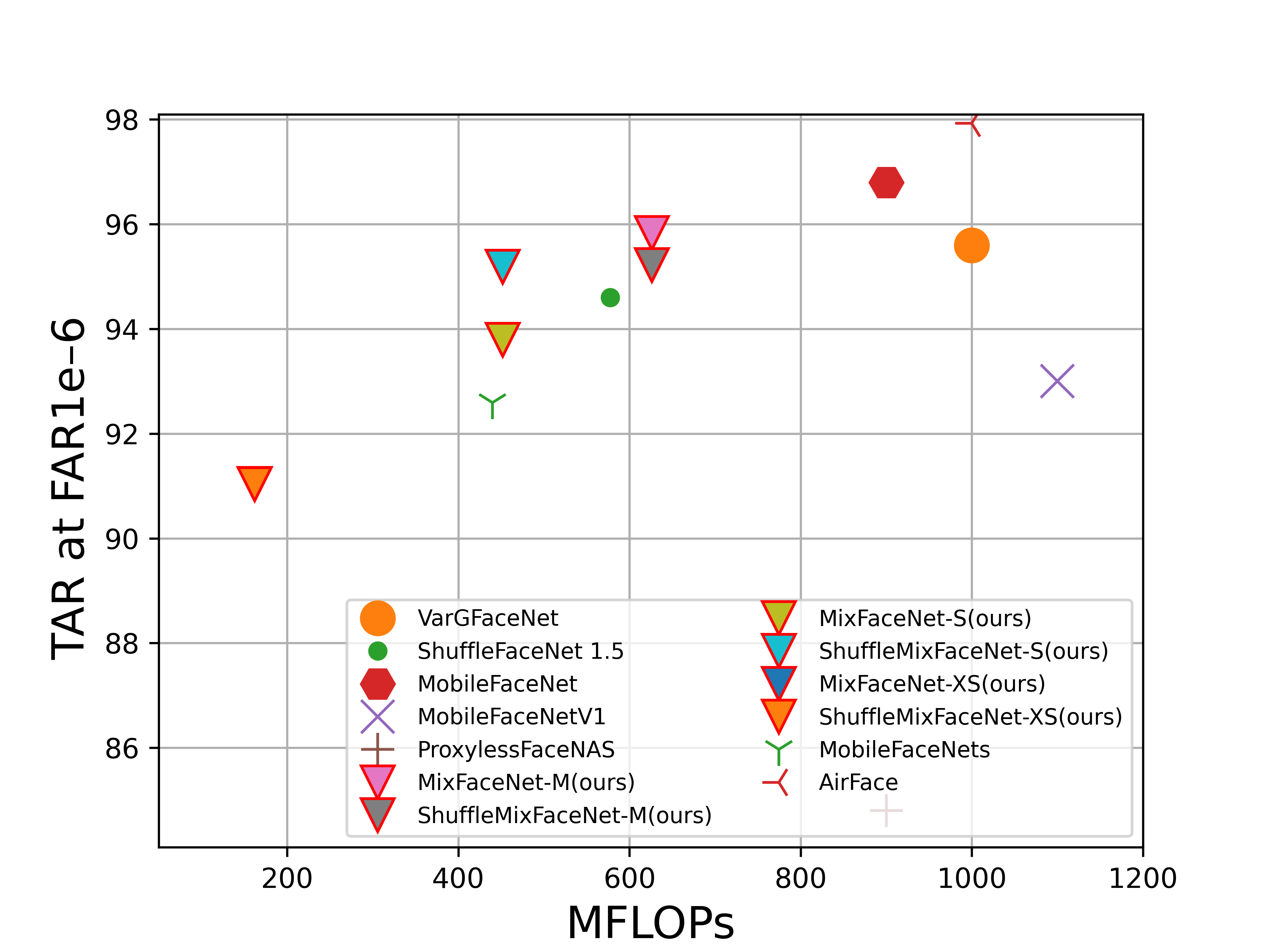
IJB-B 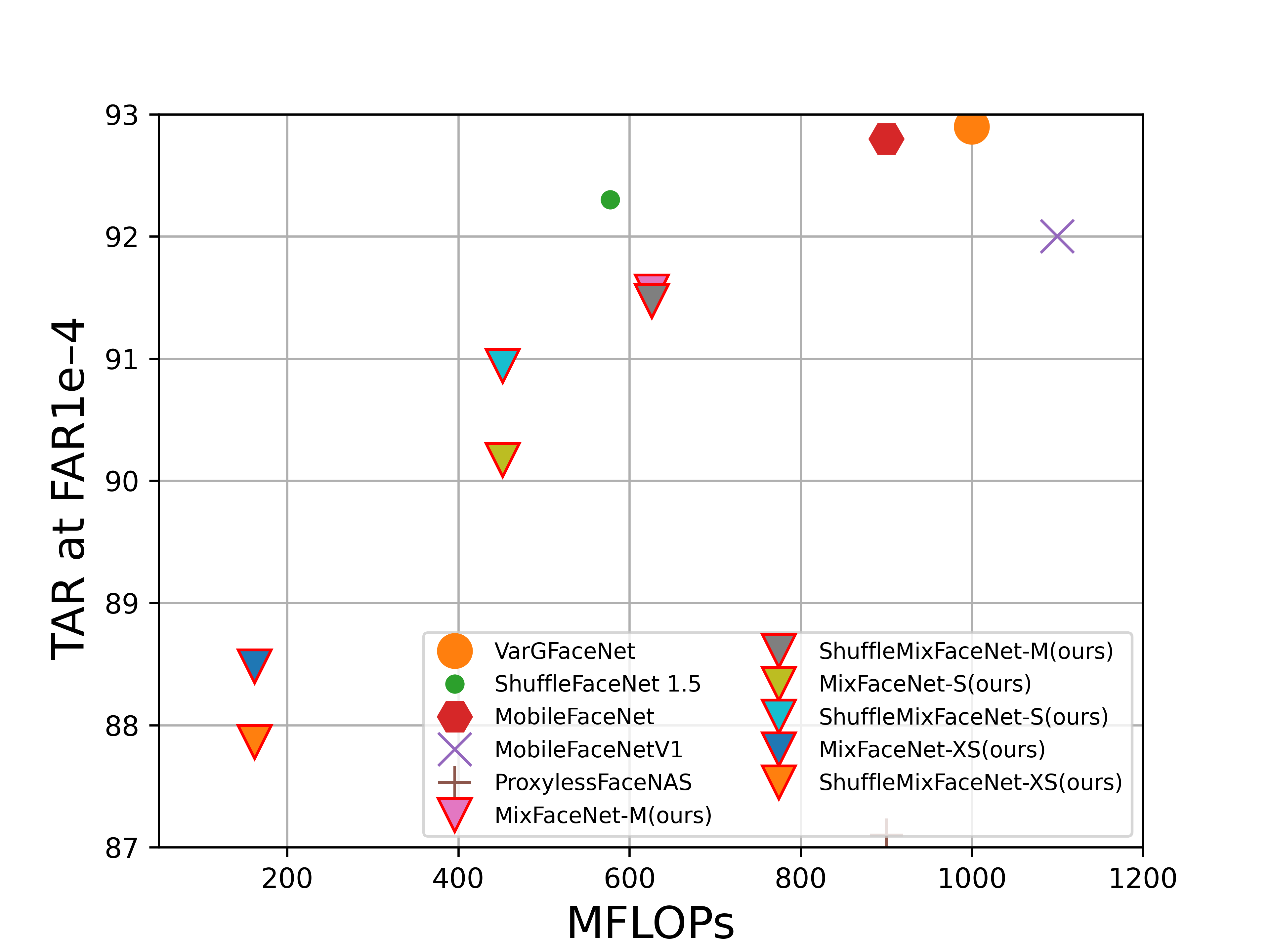
IJB-C 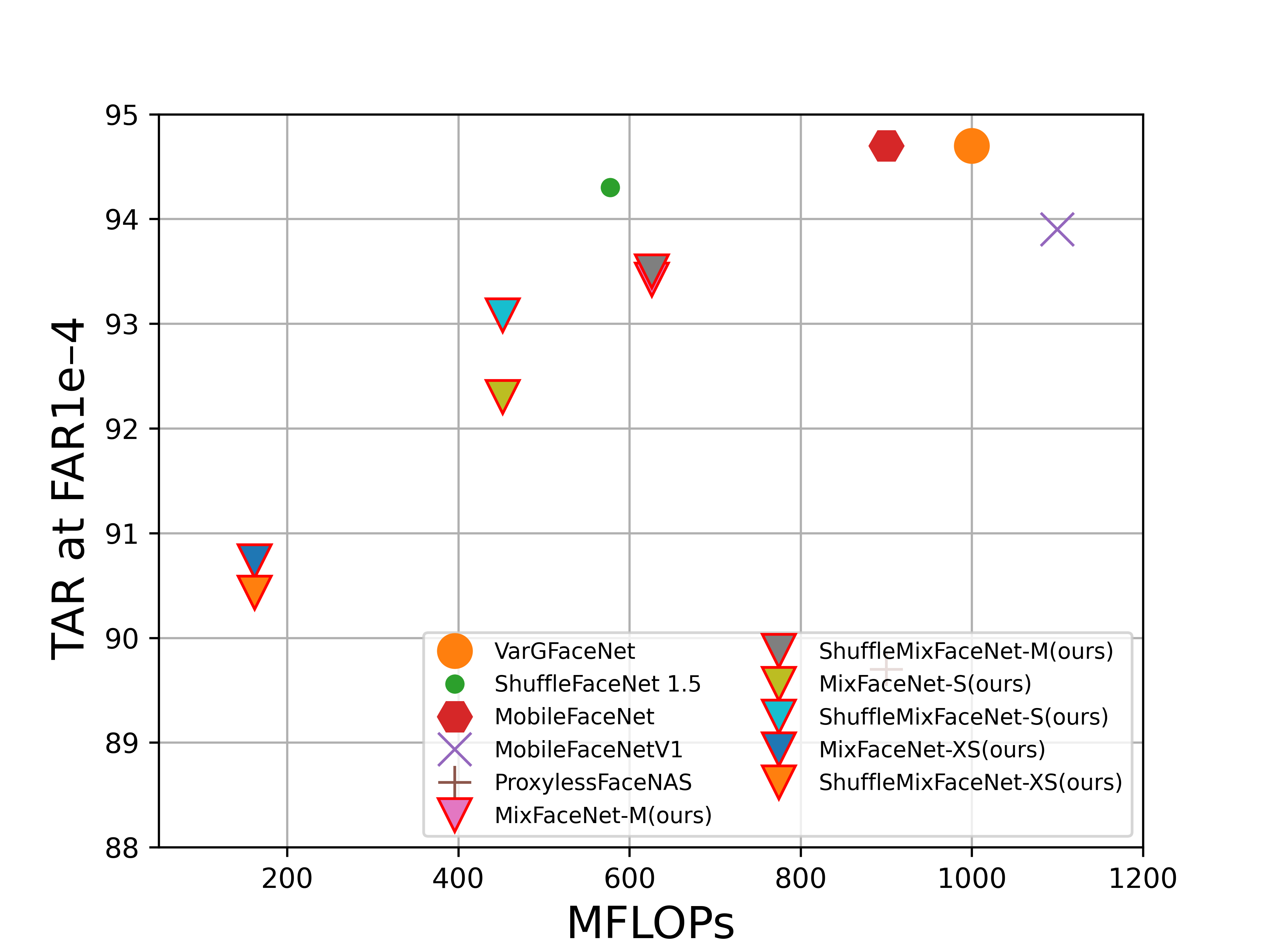
If you find MixFaceNets useful in your research, please cite the following paper:
Citation
@INPROCEEDINGS{9484374,
author={Boutros, Fadi and Damer, Naser and Fang, Meiling and Kirchbuchner, Florian and Kuijper, Arjan},
booktitle={2021 IEEE International Joint Conference on Biometrics (IJCB)},
title={MixFaceNets: Extremely Efficient Face Recognition Networks},
year={2021},
volume={},
number={},
pages={1-8},
doi={10.1109/IJCB52358.2021.9484374}}
The model is trained with ArcFace loss using Partial-FC algorithms. If you train the MixfaceNets with ArcFace and Partial-FC, please follow their distribution licenses.
Citation
@inproceedings{deng2019arcface,
title={Arcface: Additive angular margin loss for deep face recognition},
author={Deng, Jiankang and Guo, Jia and Xue, Niannan and Zafeiriou, Stefanos},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
pages={4690--4699},
year={2019}
}
@inproceedings{an2020partical_fc,
title={Partial FC: Training 10 Million Identities on a Single Machine},
author={An, Xiang and Zhu, Xuhan and Xiao, Yang and Wu, Lan and Zhang, Ming and Gao, Yuan and Qin, Bin and
Zhang, Debing and Fu Ying},
booktitle={Arxiv 2010.05222},
year={2020}
}

 1 Jan 27, 2022
1 Jan 27, 2022
 12 Oct 23, 2022
12 Oct 23, 2022
 10 Jul 14, 2022
10 Jul 14, 2022
 284 Dec 27, 2022
284 Dec 27, 2022
 2 Sep 09, 2022
2 Sep 09, 2022
 105 Dec 25, 2022
105 Dec 25, 2022
 36 Dec 02, 2022
36 Dec 02, 2022
 0 Oct 19, 2021
0 Oct 19, 2021
 150 Dec 23, 2022
150 Dec 23, 2022
 3 Aug 29, 2022
3 Aug 29, 2022
 170 Dec 15, 2022
170 Dec 15, 2022
 312 Jan 07, 2023
312 Jan 07, 2023
 63 Nov 23, 2022
63 Nov 23, 2022
 9 Jun 06, 2022
9 Jun 06, 2022
 32 Nov 22, 2022
32 Nov 22, 2022
 628 Dec 28, 2022
628 Dec 28, 2022
 1 Jun 28, 2022
1 Jun 28, 2022
 139 Jan 04, 2023
139 Jan 04, 2023
 115 Dec 30, 2022
115 Dec 30, 2022
 7 May 03, 2022
7 May 03, 2022