wseg
Overview
The Pytorch implementation of Weakly Supervised Semantic Segmentation by Pixel-to-Prototype Contrast.
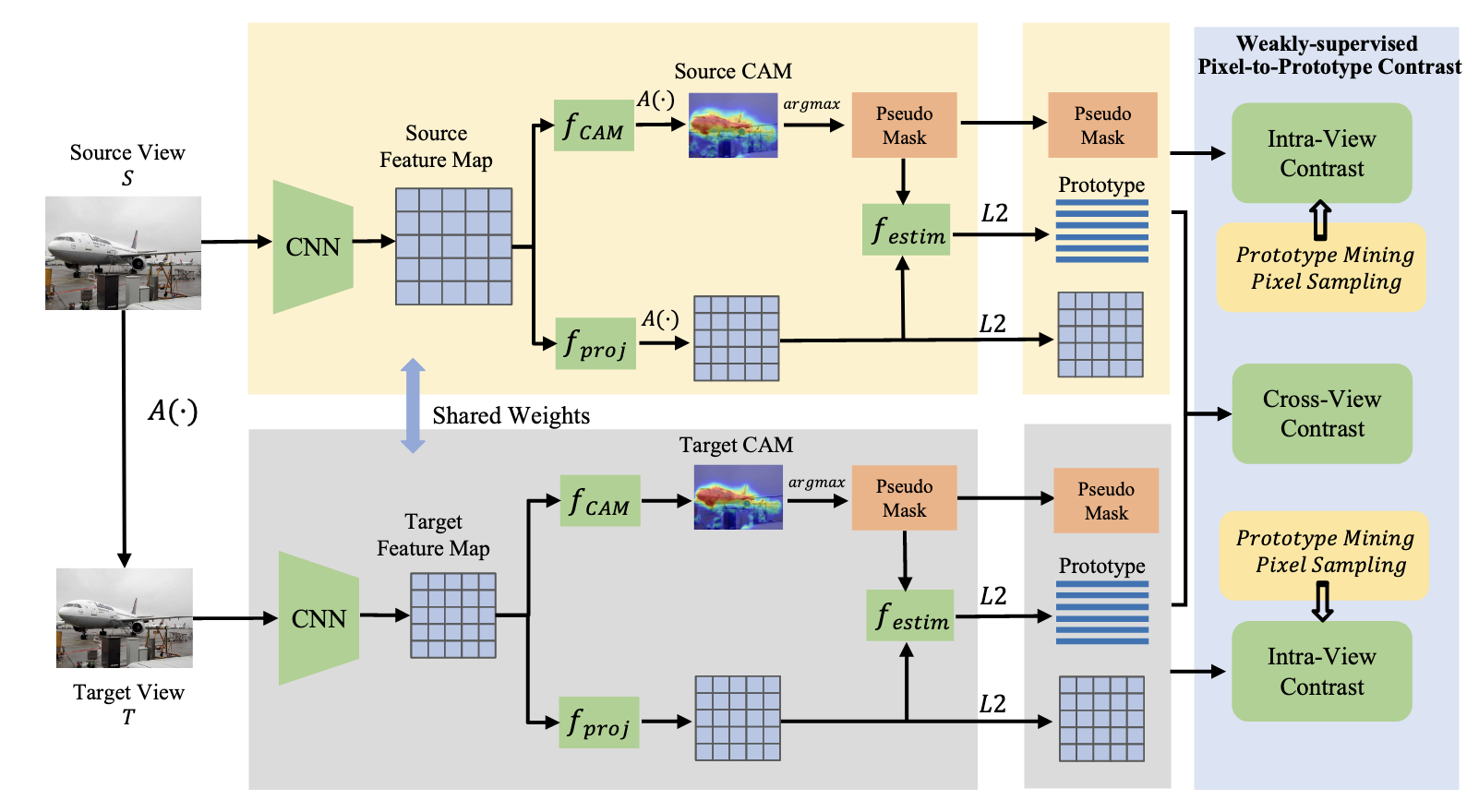
Though image-level weakly supervised semantic segmentation (WSSS) has achieved great progress with Class Activation Maps (CAMs) as the cornerstone, the large supervision gap between classification and segmentation still hampers the model to generate more complete and precise pseudo masks for segmentation. In this study, we propose weakly-supervised pixel-to-prototype contrast that can provide pixel-level supervisory signals to narrow the gap. Guided by two intuitive priors, our method is executed across different views and within per single view of an image, aiming to impose cross-view feature semantic consistency regularization and facilitate intra(inter)-class compactness(dispersion) of the feature space. Our method can be seamlessly incorporated into existing WSSS models without any changes to the base networks and does not incur any extra inference burden. Extensive experiments manifest that our method consistently improves two strong baselines by large margins, demonstrating the effectiveness.
Prerequisites
- Python 3.6
- pytorch>=1.6.0
- torchvision
- CUDA>=9.0
- pydensecrf from https://github.com/lucasb-eyer/pydensecrf
- others (opencv-python etc.)
Preparation
- Clone this repository.
- Data preparation. Download PASCAL VOC 2012 devkit following instructions in http://host.robots.ox.ac.uk/pascal/VOC/voc2012/#devkit. It is suggested to make a soft link toward downloaded dataset. Then download the annotation of VOC 2012 trainaug set (containing 10582 images) from https://www.dropbox.com/s/oeu149j8qtbs1x0/SegmentationClassAug.zip?dl=0 and place them all as
VOC2012/SegmentationClassAug/xxxxxx.png. Download the image-level labelscls_label.npyfrom https://github.com/YudeWang/SEAM/tree/master/voc12/cls_label.npy and place it intovoc12/, or you can generate it by yourself. - Download ImageNet pretrained backbones. We use ResNet-38 for initial seeds generation and ResNet-101 for segmentation training. Download pretrained ResNet-38 from https://drive.google.com/file/d/15F13LEL5aO45JU-j45PYjzv5KW5bn_Pn/view. The ResNet-101 can be downloaded from https://download.pytorch.org/models/resnet101-5d3b4d8f.pth.
Model Zoo
Download the trained models and category performance below.
| baseline | model | train(mIoU) | val(mIoU) | test (mIoU) | checkpoint | category performance |
|---|---|---|---|---|---|---|
| SEAM | contrast | 61.5 | 58.4 | - | [download] | |
| affinitynet | 69.2 | - | [download] | |||
| deeplabv1 | - | 67.7* | 67.4* | [download] | [link] | |
| EPS | contrast | 70.5 | - | - | [download] | |
| deeplabv1 | - | 72.3* | 73.5* | [download] | [link] | |
| deeplabv2 | - | 72.6* | 73.6* | [download] | [link] |
* indicates using densecrf.
The training results including initial seeds, intermediate products and pseudo masks can be found here.
Usage
Step1: Initial Seed Generation with Contrastive Learning.
-
Contrast train.
python contrast_train.py \ --weights $pretrained_model \ --voc12_root VOC2012 \ --session_name $your_session_name \ --batch_size $bs -
Contrast inference.
Download the pretrained model from https://1drv.ms/u/s!AgGL9MGcRHv0mQSKoJ6CDU0cMjd2?e=dFlHgN or train from scratch, set
--weightsand then run:python contrast_infer.py \ --weights $contrast_weight \ --infer_list $[voc12/val.txt | voc12/train.txt | voc12/train_aug.txt] \ --out_cam $your_cam_npy_dir \ --out_cam_pred $your_cam_png_dir \ --out_crf $your_crf_png_dir -
Evaluation.
Following SEAM, we recommend you to use
--curveto select an optimial background threshold.python eval.py \ --list VOC2012/ImageSets/Segmentation/$[val.txt | train.txt] \ --predict_dir $your_result_dir \ --gt_dir VOC2012/SegmentationClass \ --comment $your_comments \ --type $[npy | png] \ --curve True
Step2: Refine with AffinityNet.
-
Preparation.
Prepare the files (
la_crf_dirandha_crf_dir) needed for training AffinityNet. You can also use our processed crf outputs withalpha=4/8from here.python aff_prepare.py \ --voc12_root VOC2012 \ --cam_dir $your_cam_npy_dir \ --out_crf $your_crf_alpha_dir -
AffinityNet train.
python aff_train.py \ --weights $pretrained_model \ --voc12_root VOC2012 \ --la_crf_dir $your_crf_dir_4.0 \ --ha_crf_dir $your_crf_dir_8.0 \ --session_name $your_session_name -
Random walk propagation & Evaluation.
Use the trained AffinityNet to conduct RandomWalk for refining the CAMs from Step1. Trained model can be found in Model Zoo (https://1drv.ms/u/s!AgGL9MGcRHv0mQXi0SSkbUc2sl8o?e=AY7AzX).
python aff_infer.py \ --weights $aff_weights \ --voc12_root VOC2012 \ --infer_list $[voc12/val.txt | voc12/train.txt] \ --cam_dir $your_cam_dir \ --out_rw $your_rw_dir -
Pseudo mask generation. Generate the pseudo masks for training the DeepLab Model. Dense CRF is used in this step.
python aff_infer.py \ --weights $aff_weights \ --infer_list voc12/trainaug.txt \ --cam_dir $your_cam_dir \ --voc12_root VOC2012 \ --out_rw $your_rw_dir
Step3: Segmentation training with DeepLab
-
Training.
we use the segmentation repo from https://github.com/YudeWang/semantic-segmentation-codebase. Training and inference codes are available in
segmentation/experiment/. SetDATA_PSEUDO_GT: $your_pseudo_label_pathinconfig.py. Then run:python train.py -
Inference.
Check test configration in
config.py(ckpt path, trained model: https://1drv.ms/u/s!AgGL9MGcRHv0mQgpb3QawPCsKPe9?e=4vly0H) and val/test set selection intest.py. Then run:python test.pyFor test set evaluation, you need to download test set images and submit the segmentation results to the official voc server.
For integrating our approach into the EPS model, you can change branch to EPS via:
git checkout eps
Then conduct train or inference following instructions above. Segmentation training follows the same repo in segmentation. Trained models & processed files can be download in Model Zoo.
Acknowledgements
We sincerely thank Yude Wang for his great work SEAM in CVPR'20. We borrow codes heavly from his repositories SEAM and Segmentation. We also thank Seungho Lee for his EPS and jiwoon-ahn for his AffinityNet and IRN. Without them, we could not finish this work.
Citation
@inproceedings{du2021weakly,
title={Weakly Supervised Semantic Segmentation by Pixel-to-Prototype Contrast},
author={Du, Ye and Fu, Zehua and Liu, Qingjie and Wang, Yunhong},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
year={2022}
}

 36 Dec 21, 2022
36 Dec 21, 2022
 11 Oct 17, 2022
11 Oct 17, 2022
 1 Feb 01, 2022
1 Feb 01, 2022
 6.2k Jan 01, 2023
6.2k Jan 01, 2023
 10 Dec 20, 2022
10 Dec 20, 2022
 3 Apr 18, 2022
3 Apr 18, 2022
 744 Jan 04, 2023
744 Jan 04, 2023
 348 Dec 24, 2022
348 Dec 24, 2022
 375 Dec 06, 2022
375 Dec 06, 2022
 6 May 15, 2022
6 May 15, 2022
 21 Dec 21, 2022
21 Dec 21, 2022
 100 Dec 01, 2022
100 Dec 01, 2022
 280 Dec 23, 2022
280 Dec 23, 2022
 171 Jan 06, 2023
171 Jan 06, 2023
 8 Mar 26, 2022
8 Mar 26, 2022
 148 Dec 28, 2022
148 Dec 28, 2022
 40 Dec 09, 2022
40 Dec 09, 2022
 86 Dec 28, 2022
86 Dec 28, 2022
 6 Jan 01, 2023
6 Jan 01, 2023
 214 Jan 01, 2023
214 Jan 01, 2023