Few-NERD: Not Only a Few-shot NER Dataset
This is the source code of the ACL-IJCNLP 2021 paper: Few-NERD: A Few-shot Named Entity Recognition Dataset. Check out the website of Few-NERD.
Contents
Overview
Few-NERD is a large-scale, fine-grained manually annotated named entity recognition dataset, which contains 8 coarse-grained types, 66 fine-grained types, 188,200 sentences, 491,711 entities and 4,601,223 tokens. Three benchmark tasks are built, one is supervised: Few-NERD (SUP) and the other two are few-shot: Few-NERD (INTRA) and Few-NERD (INTER).
The schema of Few-NERD is:
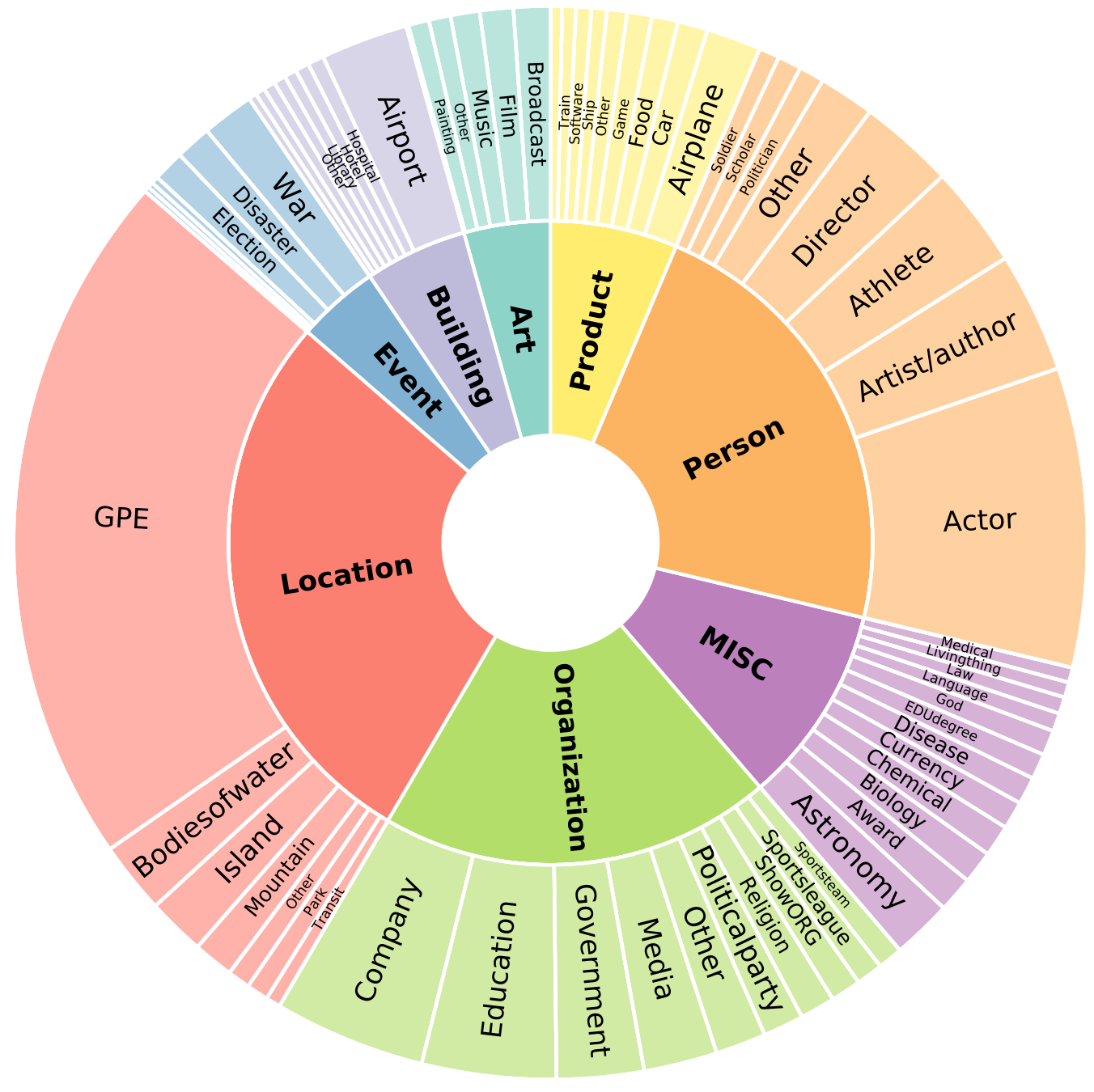
Few-NERD is manually annotated based on the context, for example, in the sentence "London is the fifth album by the British rock band…", the named entity London is labeled as Art-Music.
Requirements
Run the following script to install the remaining dependencies,
pip install -r requirements.txt
Few-NERD Dataset
Get the Data
- Few-NERD contains 8 coarse-grained types, 66 fine-grained types, 188,200 sentences, 491,711 entities and 4,601,223 tokens.
- We have splitted the data into 3 training mode. One for supervised setting-
supervised, theo ther two for few-shot settinginterandintra. Each contains three filestrain.txt,dev.txt,test.txt.superviseddatasets are randomly split.interdatasets are randomly split within coarse type, i.e. each file contains all 8 coarse types but different fine-grained types.intradatasets are randomly split by coarse type. - The splitted dataset can be downloaded automatically once you run the model. If you want to download the data manually, run data/download.sh, remember to add parameter supervised/inter/intra to indicte the type of the dataset
To obtain the three benchmarks datasets of Few-NERD, simply run the bash file data/download.sh
bash data/download.sh supervised
Data Format
The data are pre-processed into the typical NER data forms as below (token\tlabel).
Between O
1789 O
and O
1793 O
he O
sat O
on O
a O
committee O
reviewing O
the O
administrative MISC-law
constitution MISC-law
of MISC-law
Galicia MISC-law
to O
little O
effect O
. O
Structure
The structure of our project is:
--util
| -- framework.py
| -- data_loader.py
| -- viterbi.py # viterbi decoder for structshot only
| -- word_encoder
| -- fewshotsampler.py
-- proto.py # prototypical model
-- nnshot.py # nnshot model
-- train_demo.py # main training script
Key Implementations
Sampler
As established in our paper, we design an N way K~2K shot sampling strategy in our work , the implementation is sat util/fewshotsampler.py.
ProtoBERT
Prototypical nets with BERT is implemented in model/proto.py.
How to Run
Run train_demo.py. The arguments are presented below. The default parameters are for proto model on intermode dataset.
-- mode training mode, must be inter, intra, or supervised
-- trainN N in train
-- N N in val and test
-- K K shot
-- Q Num of query per class
-- batch_size batch size
-- train_iter num of iters in training
-- val_iter num of iters in validation
-- test_iter num of iters in testing
-- val_step val after training how many iters
-- model model name, must be proto, nnshot or structshot
-- max_length max length of tokenized sentence
-- lr learning rate
-- weight_decay weight decay
-- grad_iter accumulate gradient every x iterations
-- load_ckpt path to load model
-- save_ckpt path to save model
-- fp16 use nvidia apex fp16
-- only_test no training process, only test
-- ckpt_name checkpoint name
-- seed random seed
-- pretrain_ckpt bert pre-trained checkpoint
-- dot use dot instead of L2 distance in distance calculation
-- use_sgd_for_bert use SGD instead of AdamW for BERT.
# only for structshot
-- tau StructShot parameter to re-normalizes the transition probabilities
-
For hyperparameter
--tauin structshot, we use0.32in 1-shot setting,0.318for 5-way-5-shot setting, and0.434for 10-way-5-shot setting. -
Take
structshotmodel oninterdataset for example, the expriments can be run as follows.
5-way-1~5-shot
python3 train_demo.py --train data/mydata/train-inter.txt \
--val data/mydata/val-inter.txt --test data/mydata/test-inter.txt \
--lr 1e-3 --batch_size 2 --trainN 5 --N 5 --K 1 --Q 1 \
--train_iter 10000 --val_iter 500 --test_iter 5000 --val_step 1000 \
--max_length 60 --model structshot --tau 0.32
5-way-5~10-shot
python3 train_demo.py --train data/mydata/train-inter.txt \
--val data/mydata/val-inter.txt --test data/mydata/test-inter.txt \
--lr 1e-3 --batch_size 2 --trainN 5 --N 5 --K 5 --Q 5 \
--train_iter 10000 --val_iter 500 --test_iter 5000 --val_step 1000 \
--max_length 60 --model structshot --tau 0.318
10-way-1~5-shot
python3 train_demo.py --train data/mydata/train-inter.txt \
--val data/mydata/val-inter.txt --test data/mydata/test-inter.txt \
--lr 1e-3 --batch_size 2 --trainN 10 --N 10 --K 1 --Q 1 \
--train_iter 10000 --val_iter 500 --test_iter 5000 --val_step 1000 \
--max_length 60 --model structshot --tau 0.32
10-way-5~10-shot
python3 train_demo.py --train data/mydata/train-inter.txt \
--val data/mydata/val-inter.txt --test data/mydata/test-inter.txt \
--lr 1e-3 --batch_size 2 --trainN 5 --N 5 --K 5 --Q 1 \
--train_iter 10000 --val_iter 500 --test_iter 5000 --val_step 1000 \
--max_length 60 --model structshot --tau 0.434
Citation
If you use Few-NERD in your work, please cite our paper:
@inproceedings{ding2021few,
title={Few-NERD: A Few-Shot Named Entity Recognition Dataset},
author={Ding, Ning and Xu, Guangwei and Chen, Yulin, and Wang, Xiaobin and Han, Xu and Xie, Pengjun and Zheng, Hai-Tao and Liu, Zhiyuan},
booktitle={ACL-IJCNLP},
year={2021}
}
Connection
If you have any questions, feel free to contact

 86 Oct 05, 2022
86 Oct 05, 2022
 15 Dec 06, 2022
15 Dec 06, 2022
 163 Dec 19, 2022
163 Dec 19, 2022
 87 Dec 24, 2022
87 Dec 24, 2022
 0 Sep 28, 2022
0 Sep 28, 2022
 47 Nov 02, 2022
47 Nov 02, 2022
 666 Jan 03, 2023
666 Jan 03, 2023
 726 Dec 29, 2022
726 Dec 29, 2022
 2 Sep 15, 2022
2 Sep 15, 2022
 71 Dec 17, 2022
71 Dec 17, 2022
 [email protected]">
18 Sep 10, 2022
[email protected]">
18 Sep 10, 2022
 659 Dec 27, 2022
659 Dec 27, 2022
 36 Dec 16, 2022
36 Dec 16, 2022
 64 Dec 29, 2022
64 Dec 29, 2022
 8 Dec 27, 2022
8 Dec 27, 2022
 58 Nov 22, 2022
58 Nov 22, 2022
 215 Jan 01, 2023
215 Jan 01, 2023
 2.6k Dec 29, 2022
2.6k Dec 29, 2022
 3 Sep 08, 2022
3 Sep 08, 2022
 21 Aug 16, 2022
21 Aug 16, 2022