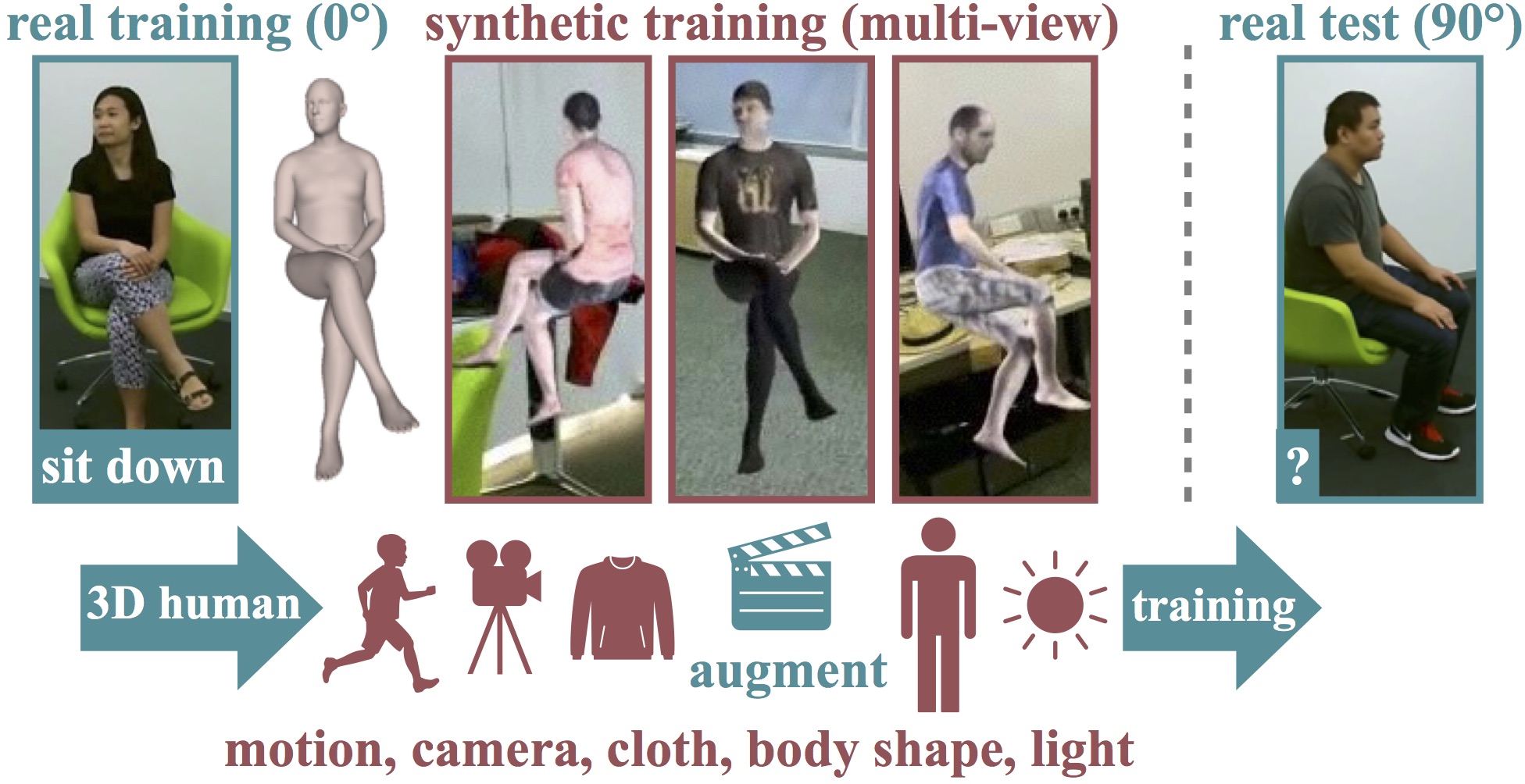
SURREACT: Synthetic Humans for Action Recognition from Unseen Viewpoints
Gül Varol, Ivan Laptev and Cordelia Schmid, Andrew Zisserman, Synthetic Humans for Action Recognition from Unseen Viewpoints, IJCV 2021.
Contents
- 1. Synthetic data generation from motion estimation
- 2. Training action recognition models
- 3. Download SURREACT datasets
- Citation
- License
- Acknowledgements
1. Synthetic data generation from motion estimation
Please follow the instructions at datageneration/README.md for setting up the Blender environment and downloading required assets.
Once ready, you can generate one clip by running:
# set `BLENDER_PATH` and `CODE_PATH` variables in this script
bash datageneration/exe/run.sh
Note that -t 1 option in run.sh can be removed to run faster on multi cores. We used submit_multi_job*.sh to generate clips for the whole datasets in parallel on the cluster, you can adapt this for your infrastructure. This script also has sample argument-value pairs. Find in utils/argutils.py a list of arguments and their explanations. You can enable/disable outputting certain modalities by setting output_types here.
2. Training action recognition models
Please follow the instructions at training/README.md for setting up the Pytorch environment and preparing the datasets.
Once ready, you can launch training by running:
cd training/
bash exp/surreact_train.sh
3. Download SURREACT datasets
In order to download SURREACT datasets, you need to accept the license terms from SURREAL. The links to license terms and download procedure are available here:
https://www.di.ens.fr/willow/research/surreal/data/
Once you receive the credentials to download the dataset, you will have a personal username and password. Use these to download the synthetic videos from the following links. Note that due to storage complexity, we only provide .mp4 video files and metadata, but not the other modalities such as flow and segmentation. You are encouraged to run the data generation code to obtain those. We provide videos corresponding to NTU and UESTC datasets.
- surreact_ntu_vibe.tar.gz, (8.4GB) with 105,642 videos (105,162 training, 480 test). This is used in Table 1 of the paper, obtains the best results.
- surreact_ntu_hmmr.tar.gz, (9.1GB) with 105,983 videos (105,503 training, 480 test). This is used in most experiments in the paper.
- surreact_uestc_vibe.tar.gz, (3.2GB) with 12800 videos (12800 training, 0 test). This is not used in the paper.
- surreact_uestc_hmmr.tar.gz, (646MB) with 3193 videos (3154 training, 39 test). This is a subset due to computational complexity, it is used in the paper.
The structure of the folders can be as follows:
surreact/
------- uestc/ # using motion estimates from the UESTC dataset
------------ hmmr/
------------ vibe/
------- ntu/ # using motion estimates from the NTU dataset
------------ hmmr/
------------ vibe/
---------------- train/
---------------- test/
--------------------- <sequenceName>/ # e.g. S001C002P003R002A001 for NTU, a25_d1_p048_c1_color.avi for UESTC
------------------------------ <sequenceName>_v%03d_r%02d.mp4 # RGB - 240x320 resolution video
------------------------------ <sequenceName>_v%03d_r%02d_info.mat # metadata
# bg [char] - name of the background image file
# cam_dist [1 single] - camera distance
# cam_height [1 single] - camera height
# cloth [chat] - name of the texture image file
# gender [1 uint8] - gender (0: 'female', 1: 'male')
# joints2D [2x24xT single] - 2D coordinates of 24 SMPL body joints on the image pixels
# joints3D [3x24xT single] - 3D coordinates of 24 SMPL body joints in world meters
# light [9 single] - spherical harmonics lighting coefficients
# pose [72xT single] - SMPL parameters (axis-angle)
# sequence [char] - <sequenceName>
# shape [10 single] - body shape parameters
# source [char] - 'ntu' | 'hri40'
# zrot_euler [1 single] - rotation in Z (euler angle), zero
# *** v%03d stands for the viewpoint in euler angles, we render 8 views: 000, 045, 090, 135, 180, 225, 270, 315.
# *** r%02d stands for the repetition, when the same video is rendered multiple times (this is always 00 for the released files)
# *** T is the number of frames, note that this can be smaller than the real source video length due to motion estimation dropping frames
Citation
If you use this code or data, please cite the following:
@INPROCEEDINGS{varol21_surreact,
title = {Synthetic Humans for Action Recognition from Unseen Viewpoints},
author = {Varol, G{\"u}l and Laptev, Ivan and Schmid, Cordelia and Zisserman, Andrew},
booktitle = {IJCV},
year = {2021}
}
License
Please check the SURREAL license terms before downloading and/or using the SURREACT data and data generation code.
Acknowledgements
The data generation code was extended from gulvarol/surreal. The training code was extended from bearpaw/pytorch-pose. The source of assets include action recognition datasets NTU and UESTC, SMPL and SURREAL projects. The motion estimation was possible thanks to mkocabas/VIBE or akanazawa/human_dynamics (HMMR) repositories. Please cite the respective papers if you use these.
Special thanks to Inria clusters sequoia and rioc.

 11 Dec 11, 2022
11 Dec 11, 2022
 17 Dec 08, 2022
17 Dec 08, 2022
 3 Oct 17, 2021
3 Oct 17, 2021
 28 Sep 16, 2022
28 Sep 16, 2022
 33 Dec 23, 2022
33 Dec 23, 2022
 157 Jan 01, 2023
157 Jan 01, 2023
 46 Dec 19, 2022
46 Dec 19, 2022
 4 Aug 19, 2022
4 Aug 19, 2022
 26 Nov 18, 2022
26 Nov 18, 2022
 11 Sep 16, 2022
11 Sep 16, 2022
 85 Dec 22, 2022
85 Dec 22, 2022
 7 Dec 03, 2022
7 Dec 03, 2022
 19 Dec 12, 2022
19 Dec 12, 2022
 60 Jan 05, 2023
60 Jan 05, 2023
 17 Aug 30, 2021
17 Aug 30, 2021
 28 Nov 06, 2022
28 Nov 06, 2022
 12 Nov 14, 2022
12 Nov 14, 2022
 116 Jan 05, 2023
116 Jan 05, 2023
 730 Jan 09, 2023
730 Jan 09, 2023
 187 Oct 01, 2022
187 Oct 01, 2022