guess the correlation
data inspection
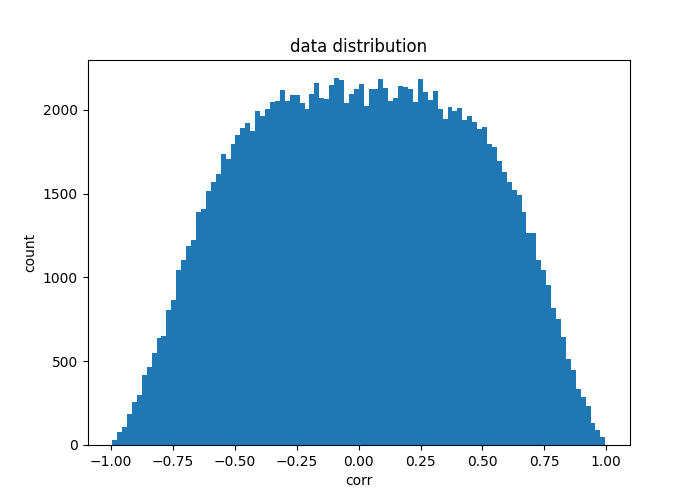
a pretty normal distribution
train/val/test split
splitting amount
.dataset: 150000 instances
├─80%─├─80%─training 96000 instances
│ └─20%─validation 24000 instances
├─20%─testing 30000 instances
after a rough glance at the dataset distribution, considered the dataset is pretty normal distributed and has enough instances to keep the variance low after 80/20 splitting.
splitting method
def _split_dataset(self, split, training=True):
if split == 0.0:
return None, None
# self.correlations_frame = pd.read_csv('path/to/csv_file')
n_samples = len(self.correlations_frame)
idx_full = np.arange(n_samples)
# fix seed for referenceable testing set
np.random.seed(0)
np.random.shuffle(idx_full)
if isinstance(split, int):
assert split > 0
assert split < n_samples, "testing set size is configured to be larger than entire dataset."
len_test = split
else:
len_test = int(n_samples * split)
test_idx = idx_full[0:len_test]
train_idx = np.delete(idx_full, np.arange(0, len_test))
if training:
dataset = self.correlations_frame.ix[train_idx]
else:
dataset = self.correlations_frame.ix[test_idx]
return dataset
training/validation splitting uses the same logic
model inspection
CorrelationModel(
(features): Sequential(
(0): Conv2d(1, 16, kernel_size=(3, 3), stride=(2, 2), padding=(2, 2))
#(0): params: (3*3*1+1) * 16 = 160
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
#(1): params: 16 * 2 = 32
(2): ReLU(inplace=True)
(3): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2))
#(4): params: (3*3*16+1) * 32 = 4640
(5): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
#(5): params: 32 * 2 = 64
(6): ReLU(inplace=True)
(7): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(8): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
#(8): params: (3*3*32+1) * 64 = 18496
(9): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
#(9): params: 64 * 2 = 128
(10): ReLU(inplace=True)
(11): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(12): Conv2d(64, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
#(12): params: (3*3*64+1) * 32 = 18464
(13): ReLU(inplace=True)
(14): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(15): Conv2d(32, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(#15): params: (3*3*32+1) * 16 = 4624
(16): ReLU(inplace=True)
(17): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(18): Conv2d(16, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(#18): params: (3*3*16+1) * 8 = 1160
(19): ReLU(inplace=True)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(linear): Sequential(
(0): Conv2d(8, 1, kernel_size=(1, 1), stride=(1, 1))
#(0): params: (8+1) * 1 = 9
(1): Tanh()
)
)
Trainable parameters: 47777
loss function
the loss function of choice is smooth_l1, which has the advantages of both l1 and l2 loss
def SmoothL1(yhat, y): <--- final choice
return torch.nn.functional.smooth_l1_loss(yhat, y)
def MSELoss(yhat, y):
return torch.nn.functional.mse_loss(yhat, y)
def RMSELoss(yhat, y):
return torch.sqrt(MSELoss(yhat, y))
def MSLELoss(yhat, y):
return MSELoss(torch.log(yhat + 1), torch.log(y + 1))
def RMSLELoss(yhat, y):
return torch.sqrt(MSELoss(torch.log(yhat + 1), torch.log(y + 1)))
evaluation metric
def mse(output, target):
# mean square error
with torch.no_grad():
assert output.shape[0] == len(target)
mae = torch.sum(MSELoss(output, target)).item()
return mae / len(target)
def mae(output, target):
# mean absolute error
with torch.no_grad():
assert output.shape[0] == len(target)
mae = torch.sum(abs(target-output)).item()
return mae / len(target)
def mape(output, target):
# mean absolute percentage error
with torch.no_grad():
assert output.shape[0] == len(target)
mape = torch.sum(abs((target-output)/target)).item()
return mape / len(target)
def rmse(output, target):
# root mean square error
with torch.no_grad():
assert output.shape[0] == len(target)
rmse = torch.sum(torch.sqrt(MSELoss(output, target))).item()
return rmse / len(target)
def msle(output, target):
# mean square log error
with torch.no_grad():
assert output.shape[0] == len(target)
msle = torch.sum(MSELoss(torch.log(output + 1), torch.log(target + 1))).item()
return msle / len(target)
def rmsle(output, target):
# root mean square log error
with torch.no_grad():
assert output.shape[0] == len(target)
rmsle = torch.sum(torch.sqrt(MSELoss(torch.log(output + 1), torch.log(target + 1)))).item()
return rmsle / len(target)
training result
trainer - INFO - epoch : 1
trainer - INFO - smooth_l1loss : 0.0029358651146370296
trainer - INFO - mse : 9.174910654958997e-05
trainer - INFO - mae : 0.04508562459920844
trainer - INFO - mape : 0.6447089369893074
trainer - INFO - rmse : 0.0008826211761528006
trainer - INFO - msle : 0.0002885178522810747
trainer - INFO - rmsle : 0.0016459243478796756
trainer - INFO - val_loss : 0.000569225614812846
trainer - INFO - val_mse : 1.7788300462901436e-05
trainer - INFO - val_mae : 0.026543946107228596
trainer - INFO - val_mape : 0.48582320946455004
trainer - INFO - val_rmse : 0.0005245986936303476
trainer - INFO - val_msle : 9.091730712680146e-05
trainer - INFO - val_rmsle : 0.0009993902465794235
.
.
.
.
.
.
trainer - INFO - epoch : 7 <--- final model
trainer - INFO - smooth_l1loss : 0.00017805844737449661
trainer - INFO - mse : 5.564326480453019e-06
trainer - INFO - mae : 0.01469234253714482
trainer - INFO - mape : 0.2645472921580076
trainer - INFO - rmse : 0.0002925463738307978
trainer - INFO - msle : 3.3151906652316634e-05
trainer - INFO - rmsle : 0.0005688522928685416
trainer - INFO - val_loss : 0.00017794455110561102
trainer - INFO - val_mse : 5.560767222050344e-06
trainer - INFO - val_mae : 0.014510956528286139
trainer - INFO - val_mape : 0.25059283276398975
trainer - INFO - val_rmse : 0.0002930224982944007
trainer - INFO - val_msle : 3.403802761204133e-05
trainer - INFO - val_rmsle : 0.0005525556141122554
trainer - INFO - Saving checkpoint: saved/models/correlation/1031_043742/checkpoint-epoch7.pth ...
trainer - INFO - Saving current best: model_best.pth ...
.
.
.
.
.
.
trainer - INFO - epoch : 10 <--- early stop
trainer - INFO - smooth_l1loss : 0.00014610137016279624
trainer - INFO - mse : 4.565667817587382e-06
trainer - INFO - mae : 0.013266990386570494
trainer - INFO - mape : 0.24146838792661826
trainer - INFO - rmse : 0.00026499629460158757
trainer - INFO - msle : 2.77259079665176e-05
trainer - INFO - rmsle : 0.0005148174095957074
trainer - INFO - val_loss : 0.00018394086218904705
trainer - INFO - val_mse : 5.74815194340772e-06
trainer - INFO - val_mae : 0.01494487459709247
trainer - INFO - val_mape : 0.27262411576509477
trainer - INFO - val_rmse : 0.0002979971170425415
trainer - INFO - val_msle : 3.1850282267744966e-05
trainer - INFO - val_rmsle : 0.0005451643197642019
trainer - INFO - Validation performance didn't improve for 2 epochs. Training stops.
loss graph 
testing result
Loading checkpoint: saved/models/correlation/model_best.pth ...
Done
Testing set samples: 30000
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 59/59 [00:19<00:00, 3.04it/s]
Testing result:
{'loss': 0.0001722179292468354, 'mse': 6.77461177110672e-07, 'mae': 0.014289384969075522, 'mape': 0.2813985677083333, 'rmse': 3.6473782857259115e-05, 'msle': 3.554690380891164e-06, 'rmsle': 7.881066799163819e-05}

 64 Dec 17, 2022
64 Dec 17, 2022
 2 Jan 12, 2022
2 Jan 12, 2022
 5 Mar 26, 2022
5 Mar 26, 2022
 5.9k Dec 30, 2022
5.9k Dec 30, 2022
 8 Feb 27, 2022
8 Feb 27, 2022
 4 May 14, 2022
4 May 14, 2022
 44 Nov 15, 2022
44 Nov 15, 2022
 1.2k Dec 30, 2022
1.2k Dec 30, 2022
 10 Dec 29, 2022
10 Dec 29, 2022
 5 Nov 21, 2022
5 Nov 21, 2022
 74 Mar 07, 2022
74 Mar 07, 2022
 619 Dec 21, 2022
619 Dec 21, 2022
 4 Mar 30, 2022
4 Mar 30, 2022
 8 Dec 06, 2022
8 Dec 06, 2022
 0 Jul 11, 2022
0 Jul 11, 2022
 4 Dec 09, 2021
4 Dec 09, 2021
 36 Dec 27, 2022
36 Dec 27, 2022
 13 Dec 16, 2022
13 Dec 16, 2022
 1.8k Jan 02, 2023
1.8k Jan 02, 2023
 1 Jan 09, 2022
1 Jan 09, 2022