VevestaX
Track failed and successful experiments as well as features.
VevestaX is an open source Python package for ML Engineers and Data Scientists. It includes modules for tracking features sourced from data, feature engineering and variables. The output is an excel file which has tabs namely, data sourcing, feature engineering and modelling. It tracks these values in Jupyter notebook.
How to install the library:
$ pip install vevestaX
How to import a library and create the object 
How to extract features present in input data. 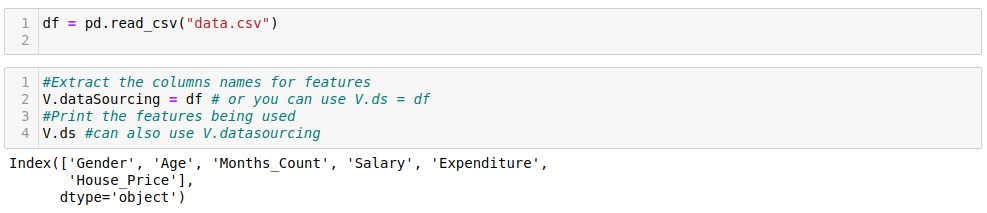
How to extract engineered features 
How to track variables used in modelling section of the code 
How to dump the features and modelling variables in an xlsx file 
For additional features, explore our tool at www.vevesta.com
 411 Dec 27, 2022
411 Dec 27, 2022
 625 Jan 2, 2023
625 Jan 2, 2023
 759 Jan 7, 2023
759 Jan 7, 2023
 3 Feb 12, 2022
3 Feb 12, 2022
 101 Dec 7, 2022
101 Dec 7, 2022
 342 Jan 7, 2023
342 Jan 7, 2023
 1 Oct 20, 2021
1 Oct 20, 2021
 5 Sep 23, 2022
5 Sep 23, 2022
 23 Dec 8, 2022
23 Dec 8, 2022


 5 Jul 13, 2022
5 Jul 13, 2022
 1 Dec 26, 2021
1 Dec 26, 2021
 906 Jan 01, 2023
906 Jan 01, 2023
 4 Jan 12, 2022
4 Jan 12, 2022
 293 Dec 29, 2022
293 Dec 29, 2022
 9 Nov 16, 2022
9 Nov 16, 2022
 1 Dec 26, 2021
1 Dec 26, 2021
 14 Jan 02, 2023
14 Jan 02, 2023
 7 Sep 27, 2022
7 Sep 27, 2022
 2 Nov 18, 2021
2 Nov 18, 2021
 1.8k Jan 09, 2023
1.8k Jan 09, 2023
 11 Oct 07, 2022
11 Oct 07, 2022
 3.7k Jan 03, 2023
3.7k Jan 03, 2023
 48 Dec 09, 2022
48 Dec 09, 2022
 1 Oct 10, 2021
1 Oct 10, 2021
 0 Apr 25, 2022
0 Apr 25, 2022
 71 Nov 05, 2022
71 Nov 05, 2022
 17 Aug 21, 2022
17 Aug 21, 2022
 4 Sep 05, 2022
4 Sep 05, 2022
 8.2k Jan 07, 2023
8.2k Jan 07, 2023