Multi-objective Optimized GBT(MooGBT)
MooGBT is a library for Multi-objective optimization in Gradient Boosted Trees. MooGBT optimizes for multiple objectives by defining constraints on sub-objective(s) along with a primary objective. The constraints are defined as upper bounds on sub-objective loss function. MooGBT uses a Augmented Lagrangian(AL) based constrained optimization framework with Gradient Boosted Trees, to optimize for multiple objectives.
With AL, we introduce dual variables in Boosting. The dual variables are iteratively optimized and fit within the Boosting iterations. The Boosting objective function is updated with the AL terms and the gradient is readily derived using the GBT gradients. With the gradient and updates of dual variables, we solve the optimization problem by jointly iterating AL and Boosting steps.
This library is motivated by work done in the paper Multi-objective Relevance Ranking, which introduces an Augmented Lagrangian based method to incorporate multiple objectives (MO) in LambdaMART, which is a GBT based search ranking algorithm.
We have modified the scikit-learn GBT implementation [3] to support multi-objective optimization.
Highlights -
Current support -
Installation
Moo-GBT can be installed from PyPI
pip3 install moo-gbt
Usage
from multiobjective_gbt import MooGBTClassifier
mu = 100
b = 0.7 # upper bound on sub-objective cost
constrained_gbt = MooGBTClassifier(
loss='deviance',
n_estimators=100,
constraints=[{"mu":mu, "b":b}], # One Constraint
random_state=2021
)
constrained_gbt.fit(X_train, y_train)
Here y_train contains 2 columns, the first column should be the primary objective. The following columns are all the sub-objectives for which constraints have been specified(in the same order).
Usage Steps
- Run unconstrained GBT on Primary Objective. Unconstrained GBT is just the GBTClassifer/GBTRegressor by scikit-learn
- Calculate the loss function value for Primary Objective and sub-objective(s)
- For MooGBTClassifier calculate Log Loss between predicted probability and sub-objective label(s)
- For MooGBTRegressor calculate mean squared error between predicted value and sub-objective label(s)
- Set the value of hyperparamter b, less than the calculated cost in the previous step and run MooGBTClassifer/MooGBTRegressor with this b. The lower the value of b, the more the sub-objective will be optimized
Example with multiple binary objectives
import pandas as pd
import numpy as np
import seaborn as sns
from multiobjective_gbt import MooGBTClassifier
We'll use a publicly available dataset - available here
We define a multi-objective problem on the dataset, with the primary objective as the column "is_booking" and sub-objective as the column "is_package". Both these variables are binary.
# Preprocessing Data
train_data = pd.read_csv('examples/expedia-data/expedia-hotel-recommendations/train_data_sample.csv')
po = 'is_booking' # primary objective
so = 'is_package' # sub-objective
features = list(train_data.columns)
features.remove(po)
outcome_flag = po
# Train-Test Split
X_train, X_test, y_train, y_test = train_test_split(
train_data[features],
train_data[outcome_flag],
test_size=0.2,
stratify=train_data[[po, so]],
random_state=2021
)
# Creating y_train_, y_test_ with 2 labels
y_train_ = pd.DataFrame()
y_train_[po] = y_train
y_train_[so] = X_train[so]
y_test_ = pd.DataFrame()
y_test_[po] = y_test
y_test_[so] = X_test[so]
MooGBTClassifier without the constraint parameter, works as the standard scikit-learn GBT classifier.
unconstrained_gbt = MooGBTClassifier(
loss='deviance',
n_estimators=100,
random_state=2021
)
unconstrained_gbt.fit(X_train, y_train)
Get train and test sub-objective costs for unconstrained model.
def get_binomial_deviance_cost(pred, y):
return -np.mean(y * np.log(pred) + (1-y) * np.log(1-pred))
pred_train = unconstrained_gbt.predict_proba(X_train)[:,1]
pred_test = unconstrained_gbt.predict_proba(X_test)[:,1]
# get sub-objective costs
so_train_cost = get_binomial_deviance_cost(pred_train, X_train[so])
so_test_cost = get_binomial_deviance_cost(pred_test, X_test[so])
print (f"""
Sub-objective cost train - {so_train_cost},
Sub-objective cost test - {so_test_cost}
""")
Sub-objective cost train - 0.9114,
Sub-objective cost test - 0.9145
Constraint is specified as an upper bound on the sub-objective cost. In the unconstrained model, we see the cost of our sub-objective to be ~0.9. So setting upper bounds below 0.9 would optimise the sub-objective.
b = 0.65 # upper bound on cost
mu = 100
constrained_gbt = MooGBTClassifier(
loss='deviance',
n_estimators=100,
constraints=[{"mu":mu, "b":b}], # One Constraint
random_state=2021
)
constrained_gbt.fit(X_train, y_train_)
From the constrained model, we achieve more than 100% gain in AuROC for the sub-objective while the loss in primary objective AuROC is kept within 6%. The entire study on this dataset can be found in the example notebook.
Looking at MooGBT primary and sub-objective losses -
To get raw values of loss functions wrt boosting iteration,
# return a Pandas dataframe with loss values of objectives wrt boosting iteration
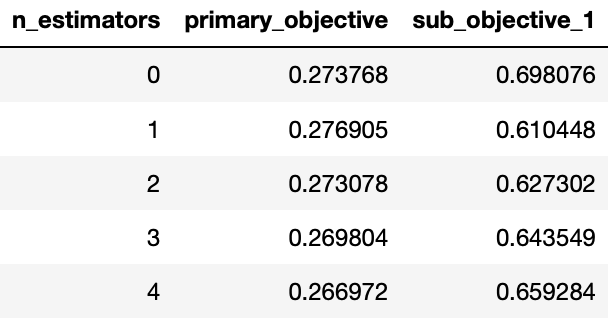
losses = constrained_gbt.loss_.get_losses()
losses.head()
Similarly, you can also look at dual variable(alpha) values for sub-objective(s),
To get raw values of alphas wrt boosting iteration,
constrained_gbt.loss_.get_alphas()
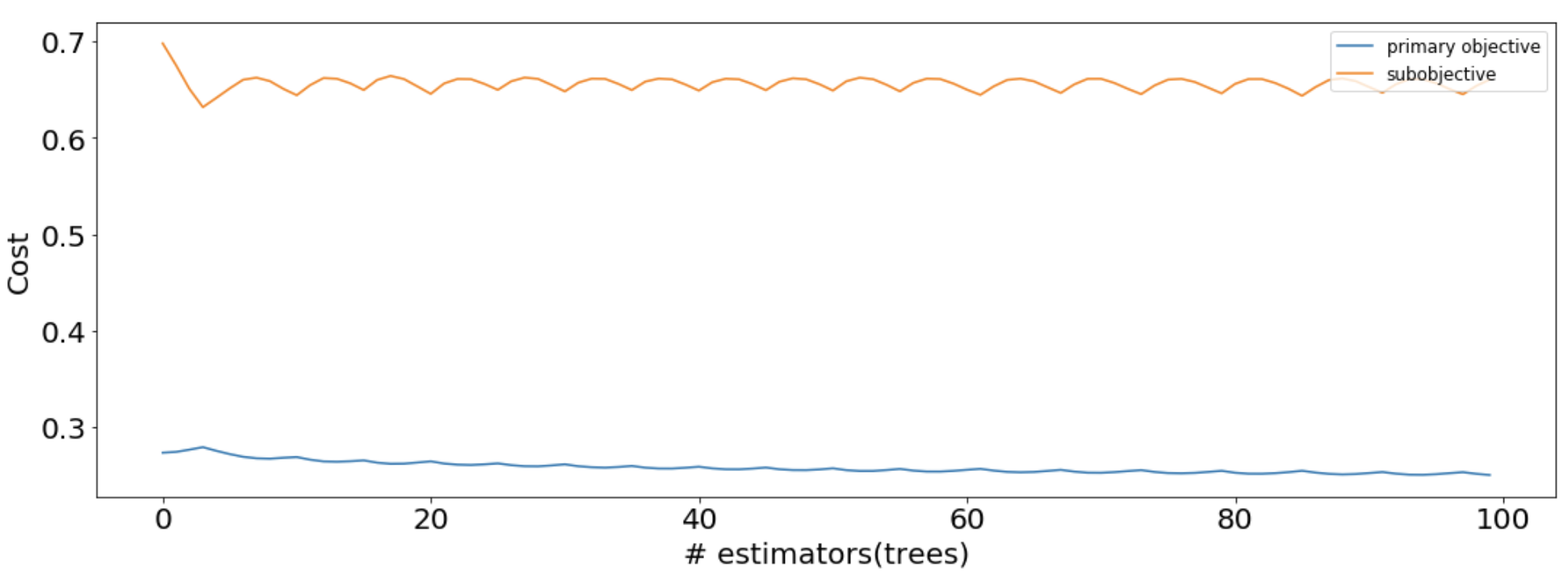
These losses can be used to look at the MooGBT Learning process.
sns.lineplot(data=losses, x='n_estimators', y='primary_objective', label='primary objective')
sns.lineplot(data=losses, x='n_estimators', y='sub_objective_1', label='subobjective')
plt.xlabel("# estimators(trees)")
plt.ylabel("Cost")
plt.legend(loc = "upper right")
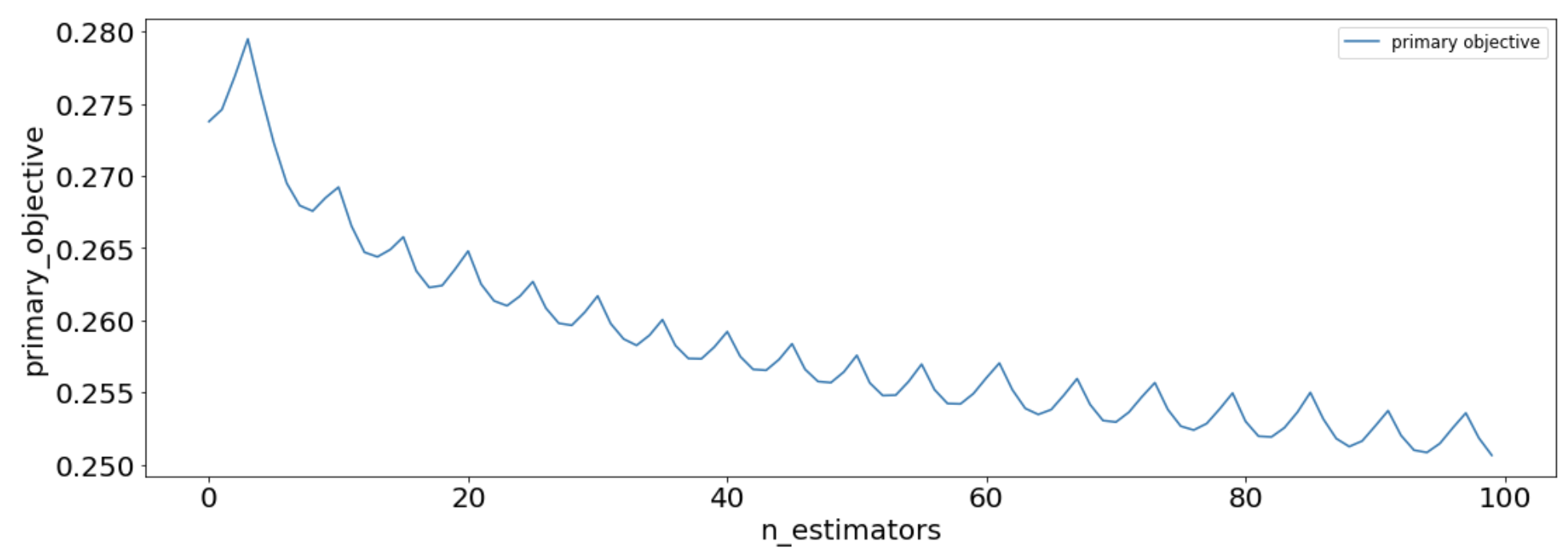
sns.lineplot(data=losses, x='n_estimators', y='primary_objective', label='primary objective')
Choosing the right upper bound constraint b and mu value
The upper bound should be defined based on a acceptable % loss in the primary objective evaluation metric. For stricter upper bounds, this loss would be greater as MooGBT will optimize for the sub-objective more.
Below table summarizes the effect of the upper bound value on the model performance for primary and sub-objective(s) for the above example.
%gain specifies the percentage increase in AUROC for the constrained MooGBT model from an uncostrained GBT model.
| b | Primary Objective - %gain | Sub-Objective - %gain |
|---|---|---|
| 0.9 | -0.7058 | 4.805 |
| 0.8 | -1.735 | 40.08 |
| 0.7 | -2.7852 | 62.7144 |
| 0.65 | -5.8242 | 113.9427 |
| 0.6 | -9.9137 | 159.8931 |
In general, across our experiments we have found that lower values of mu optimize on the primary objective better while satisfying the sub-objective constraints given enough boosting iterations(n_estimators).
The below table summarizes the results of varying mu values keeping the upper bound same(b=0.6).
| b | mu | Primary Objective - %gain | Sub-objective - %gain |
|---|---|---|---|
| 0.6 | 1000 | -20.6569 | 238.1388 |
| 0.6 | 100 | -13.3769 | 197.8186 |
| 0.6 | 10 | -9.9137 | 159.8931 |
| 0.6 | 5 | -8.643 | 146.4171 |
MooGBT Learning Process
MooGBT optimizes for multiple objectives by defining constraints on sub-objective(s) along with a primary objective. The constraints are defined as upper bounds on sub-objective loss function.
MooGBT differs from a standard GBT in the loss function it optimizes the primary objective C1 and the sub-objectives using the Augmented Lagrangian(AL) constrained optimization approach.
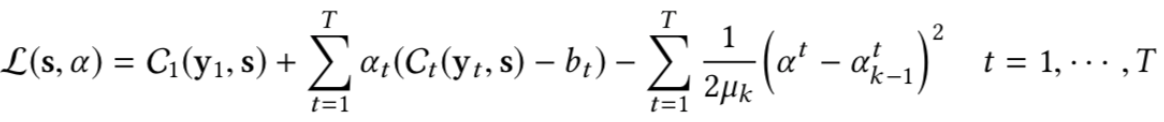
where α = [α1, α2, α3…..] is a vector of dual variables. The Lagrangian is solved by minimizing with respect to the primal variables "s" and maximizing with respect to the dual variables α. Augmented Lagrangian iteratively solves the constraint optimization. Since AL is an iterative approach we integerate it with the boosting iterations of GBT for updating the dual variable α.
Alpha(α) update -
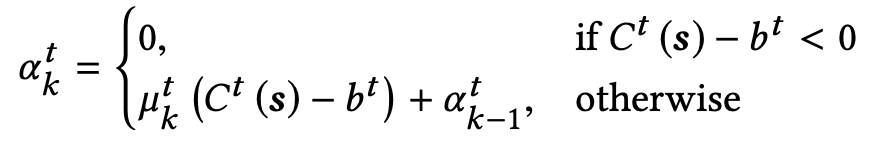
At an iteration k, if the constraint t is not satisfied, i.e., Ct(s) > bt, we have αtk > αtk-1. Otherwise, if the constraint is met, the dual variable α is made 0.
Public contents
-
_gb.py: contains the
MooGBTClassifierandMooGBTRegressorclasses. Contains implementation of the fit and predict function. Extended implementation from _gb.py from scikit-learn. -
_gb_losses.py: contains
BinomialDevianceloss function class,LeastSquaresloss function class. Extended implementation from _gb_losses.py from scikit-learn.
More examples
The examples directory contains several illustrations of how one can use this library:
-
Jupyter notebooks:
- Constrained_classifer_example.ipynb: This notebook runs MooGBTClassifier for a primary objective and a single sub-objective. Both objectives are represented as binary variable.
References -
[1] Multi-objective Ranking via Constrained Optimization - https://arxiv.org/pdf/2002.05753.pdf
[2] Multi-objective Relevance Ranking - https://sigir-ecom.github.io/ecom2019/ecom19Papers/paper30.pdf
[3] Scikit-learn GBT Implementation - GBTClassifier and GBTRegressor

 1 Jan 20, 2022
1 Jan 20, 2022
 401 Jan 08, 2023
401 Jan 08, 2023
 2 Dec 10, 2021
2 Dec 10, 2021
 16 Sep 02, 2022
16 Sep 02, 2022
 54 Aug 20, 2022
54 Aug 20, 2022
 2 Sep 13, 2021
2 Sep 13, 2021
 240 Dec 26, 2022
240 Dec 26, 2022
 3.3k Dec 28, 2022
3.3k Dec 28, 2022
 18.1k Dec 30, 2022
18.1k Dec 30, 2022
 875 Dec 27, 2022
875 Dec 27, 2022
 2 Jan 18, 2022
2 Jan 18, 2022
 2.6k Jan 08, 2023
2.6k Jan 08, 2023
 1.3k Dec 22, 2022
1.3k Dec 22, 2022
 1.1k Dec 28, 2022
1.1k Dec 28, 2022
 200 Dec 14, 2022
200 Dec 14, 2022
 1 Jan 10, 2022
1 Jan 10, 2022
 416 Jan 06, 2023
416 Jan 06, 2023
 5 Dec 06, 2022
5 Dec 06, 2022
 338 Dec 26, 2022
338 Dec 26, 2022
 558 Dec 28, 2022
558 Dec 28, 2022