HyperTag
HyperTag helps humans intuitively express how they think about their files using tags and machine learning. Represent how you think using tags. Find what you look for using semantic search for your text documents (yes, even PDF's) and images. Instead of introducing proprietary file formats like other existing file organization tools, HyperTag just smoothly layers on top of your existing files without any fuss.
Objective Function: Minimize time between a thought and access to all relevant files.
Accompanying blog post: https://blog.neotree.uber.space/posts/hypertag-file-organization-made-for-humans
Table of Contents
- HyperTag
- Install
- Community
- Overview
- CLI Functions
- Import existing directory recursively
- Add file/s or URL/s manually
- Tag file/s (with values)
- Untag file/s
- Tag a tag
- Merge tags
- Query using Set Theory
- Index supported image and text files
- Semantic search for text files
- Semantic search for image files
- Start HyperTag Daemon
- Print all tags of file/s
- Print all metatags of tag/s
- Print all tags
- Print all files
- Visualize HyperTag Graph
- Generate HyperTagFS
- Add directory to auto import list
- Set HyperTagFS directory path
- Architecture
- Development
- Inspiration
Install
Available on PyPI
$ pip install hypertag (supports both CPU only & CUDA accelerated execution!)
Community
Join the HyperTag matrix chat room to stay up to date on the latest developments or to ask for help.
Overview
HyperTag offers a slick CLI but more importantly it creates a directory called HyperTagFS which is a file system based representation of your files and tags using symbolic links and directories.
Directory Import: Import your existing directory hierarchies using $ hypertag import path/to/directory. HyperTag converts it automatically into a tag hierarchy using metatagging.
Semantic Text & Image Search (Experimental): Search for images (jpg, png) and text documents (yes, even PDF's) content with a simple text query. Text search is powered by the awesome Sentence Transformers library. Text to image search is powered by OpenAI's CLIP model. Currently only English queries are supported.
HyperTag Daemon (Experimental): Monitors HyperTagFS and directories added to the auto import list for user changes (see section "Start HyperTag Daemon" below). Also spawns the DaemonService which speeds up semantic search significantly (warning: daemon process is a RAM hog with ~2GB usage).
Fuzzy Matching Queries: HyperTag uses fuzzy matching to minimize friction in the unlikely case of a typo.
File Type Groups: HyperTag automatically creates folders containing common files (e.g. Images: jpg, png, etc., Documents: txt, pdf, etc., Source Code: py, js, etc.), which can be found in HyperTagFS.
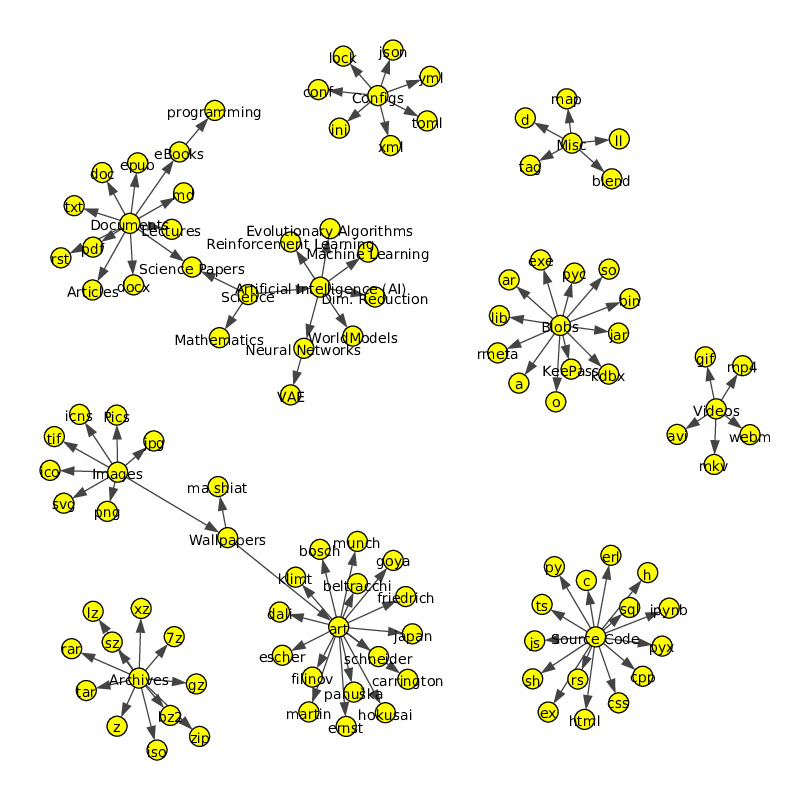
HyperTag Graph: Quickly get an overview of your HyperTag Graph! HyperTag visualizes the metatag graph on every change and saves it at HyperTagFS/hypertag-graph.pdf.
CLI Functions
Import existing directory recursively
Import files with tags inferred from the existing directory hierarchy.
$ hypertag import path/to/directory
Add file/s or URL/s manually
$ hypertag add path/to/file https://github.com/SeanPedersen/HyperTag
Tag file/s (with values)
Manually tag files. Shortcut: $ hypertag t
$ hypertag tag humans/*.txt with human "Homo Sapiens"
Add a value to a file's tag:
$ hypertag tag sean.txt with name="Sean Pedersen"
Untag file/s
Manually remove tag/s from file/s.
$ hypertag untag humans/*.txt with human "Homo Sapiens"
Tag a tag
Metatag tag/s to create tag hierarchies. Shortcut: $ hypertag tt
$ hypertag metatag human with animal
Merge tags
Merge all associations (files & tags) of tag A into tag B.
$ hypertag merge human into "Homo Sapiens"
Query using Set Theory
Print file names of the resulting set matching the query. Queries are composed of tags (with values) and operands. Tags are fuzzy matched for convenience. Nesting is currently not supported, queries are evaluated from left to right.
Shortcut: $ hypertag q
Query with a value using a wildcard: $ hypertag query name="Sean*"
Print paths: $ hypertag query human --path
Print fuzzy matched tag: $ hypertag query man --verbose
Disable fuzzy matching: $ hypertag query human --fuzzy=0
Default operand is AND (intersection):
$ hypertag query human name="Sean*" is equivalent to $ hypertag query human and name="Sean*"
OR (union):
$ hypertag query human or "Homo Sapiens"
MINUS (difference):
$ hypertag query human minus "Homo Sapiens"
Index supported image and text files
Only indexed files can be searched.
$ hypertag index
To parse even unparseable PDF's, install tesseract: # pacman -S tesseract tesseract-data-eng
Index only image files: $ hypertag index --image
Index only text files: $ hypertag index --text
Semantic search for text files
A custom search algorithm combining semantic with token matching search. Print text file names sorted by matching score. Performance benefits greatly from running the HyperTag daemon.
Shortcut: $ hypertag s
$ hypertag search "your important text query" --path --score --top_k=10
Semantic search for image files
Print image file names sorted by matching score. Performance benefits greatly from running the HyperTag daemon.
Shortcut: $ hypertag si
Text to image: $ hypertag search_image "your image content description" --path --score --top_k=10
Image to image: $ hypertag search_image "path/to/image.jpg" --path --score --top_k=10
Start HyperTag Daemon
Start daemon process with triple functionality:
- Watches
HyperTagFSdirectory for user changes- Maps file (symlink) and directory deletions into tag / metatag removal/s
- On directory creation: Interprets name as set theory tag query and automatically populates it with results
- On directory creation in
Search ImagesorSearch Texts: Interprets name as semantic search query (add top_k=42 to limit result size) and automatically populates it with results
- Watches directories on the auto import list for user changes:
- Maps file changes (moves & renames) to DB
- On file creation: Adds new file/s with inferred tag/s and auto-indexes it (if supported file format).
- Spawns DaemonService to load and expose models used for semantic search, speeding it up significantly
$ hypertag daemon
Print all tags of file/s
$ hypertag tags filename1 filename2
Print all metatags of tag/s
$ hypertag metatags tag1 tag2
Print all tags
$ hypertag show
Print all files
Print names: $ hypertag show files
Print paths: $ hypertag show files --path
Visualize HyperTag Graph
Visualize the metatag graph hierarchy (saved at HyperTagFS root).
$ hypertag graph
Specify layout algorithm (default: fruchterman_reingold):
$ hypertag graph --layout=kamada_kawai
Generate HyperTagFS
Generate file system based representation of your files and tags using symbolic links and directories.
$ hypertag mount
Add directory to auto import list
Directories added to the auto import list will be monitored by the daemon for new files or changes.
$ hypertag add_auto_import_dir path/to/directory
Set HyperTagFS directory path
Default is the user's home directory.
$ hypertag set_hypertagfs_dir path/to/directory
Architecture
- Python and it's vibrant open-source community power HyperTag
- Many other awesome open-source projects make HyperTag possible (listed in
pyproject.toml) - SQLite3 serves as the meta data storage engine (located at
~/.config/hypertag/hypertag.db) - Added URLs are saved in
~/.config/hypertag/web_pagesfor websites, others in~/.config/hypertag/downloads - Symbolic links are used to create the HyperTagFS directory structure
- Semantic Search: boosted using hnswlib
- Text to text search is powered by the awesome DistilBERT
- Text to image & image to image search is powered by OpenAI's impressive CLIP model
Development
- Find prioritized issues here: TODO List
- Pick an issue and comment how you plan to tackle it before starting out, to make sure no dev time is wasted.
- Clone repo:
$ git clone https://github.com/SeanPedersen/HyperTag.git $ cd HyperTag/- Install Poetry
- Install dependencies:
$ poetry install - Activate virtual environment:
$ poetry shell - Run all tests:
$ pytest -v - Run formatter:
$ black hypertag/ - Run linter:
$ flake8 - Run type checking:
$ mypy **/*.py - Run security checking:
$ bandit --exclude tests/ -r . - Codacy: Dashboard
- Run HyperTag:
$ python -m hypertag
Inspiration
What is the point of HyperTag's existence?
HyperTag offers many unique features such as the import, semantic search, graphing and fuzzy matching functions that make it very convenient to use. All while HyperTag's code base staying relatively tiny at <2000 LOC compared to similar projects like TMSU (>10,000 LOC in Go) and SuperTag (>25,000 LOC in Rust), making it easy to hack on.

 2 Dec 29, 2022
2 Dec 29, 2022
 128 Dec 29, 2022
128 Dec 29, 2022
 189 Nov 29, 2022
189 Nov 29, 2022
 79 Dec 30, 2022
79 Dec 30, 2022
 94 Dec 08, 2022
94 Dec 08, 2022
 10.4k Jan 09, 2023
10.4k Jan 09, 2023
 1.7k Dec 20, 2022
1.7k Dec 20, 2022
 858 Dec 29, 2022
858 Dec 29, 2022
 1 Dec 13, 2021
1 Dec 13, 2021
 98 Nov 24, 2022
98 Nov 24, 2022
 48 Dec 14, 2022
48 Dec 14, 2022
 5.8k Jan 04, 2023
5.8k Jan 04, 2023
 2 Oct 20, 2021
2 Oct 20, 2021
 77 Dec 27, 2022
77 Dec 27, 2022
 42 Mar 16, 2022
42 Mar 16, 2022
 27 Dec 22, 2022
27 Dec 22, 2022
 2.2k Jan 09, 2023
2.2k Jan 09, 2023
 7.8k Jan 09, 2023
7.8k Jan 09, 2023
 253 Dec 21, 2022
253 Dec 21, 2022
 9 Dec 20, 2022
9 Dec 20, 2022