QC-Formula | 青尘公式 OCR
介绍
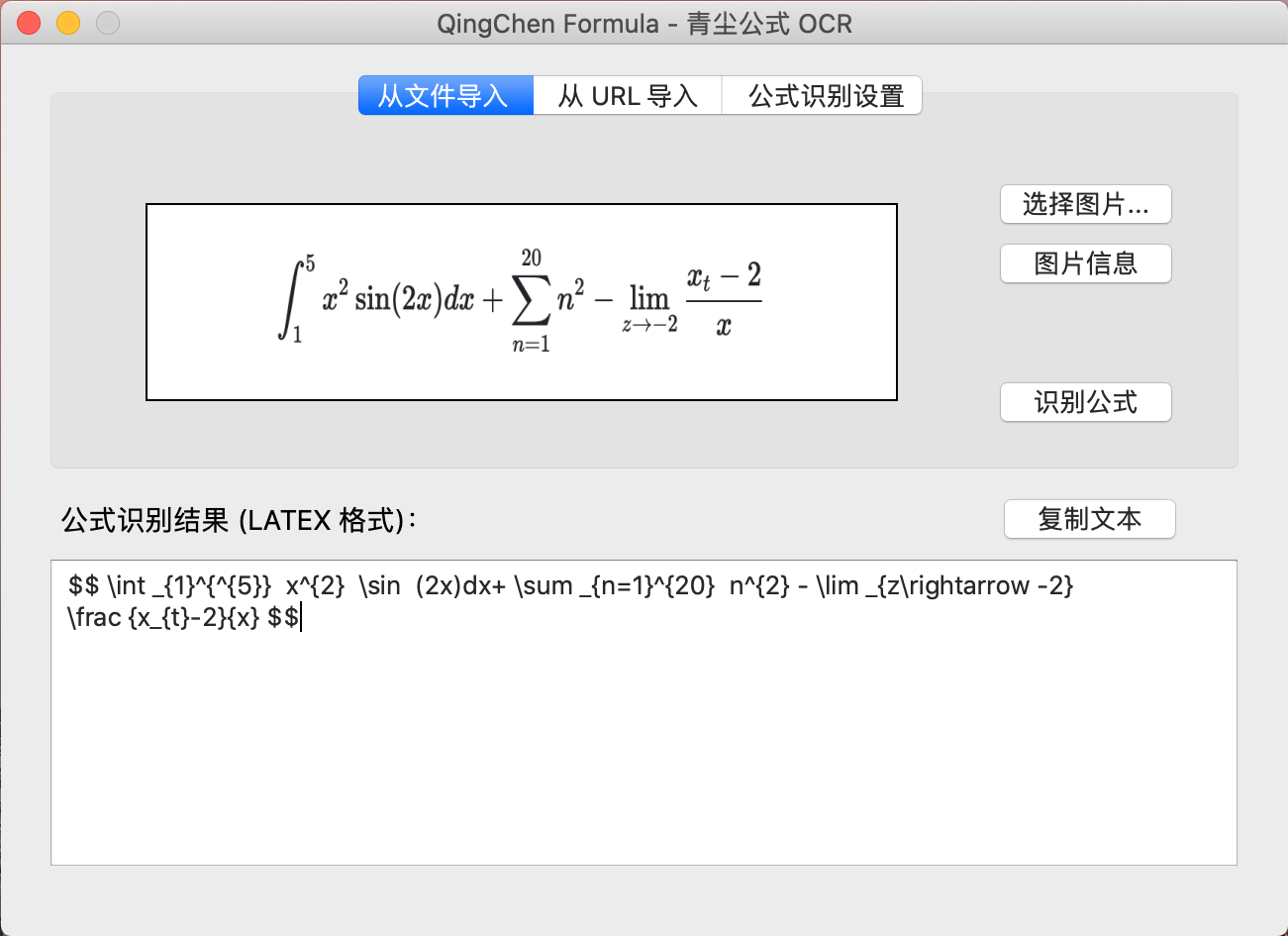
轻量级开源公式 OCR 小工具:一键识别公式图片,并转换为 LaTeX 格式。
- 支持从 电脑本地 导入公式图片;(后续版本将支持直接从网页导入图片)
- 公式图片支持 .png / .jpg / .bmp,大小为 4M 以内均可;
- 支持印刷体及手写体,前者识别效果更佳。
软件下载地址:https://github.com/QingchenWait/QC-Formula/releases
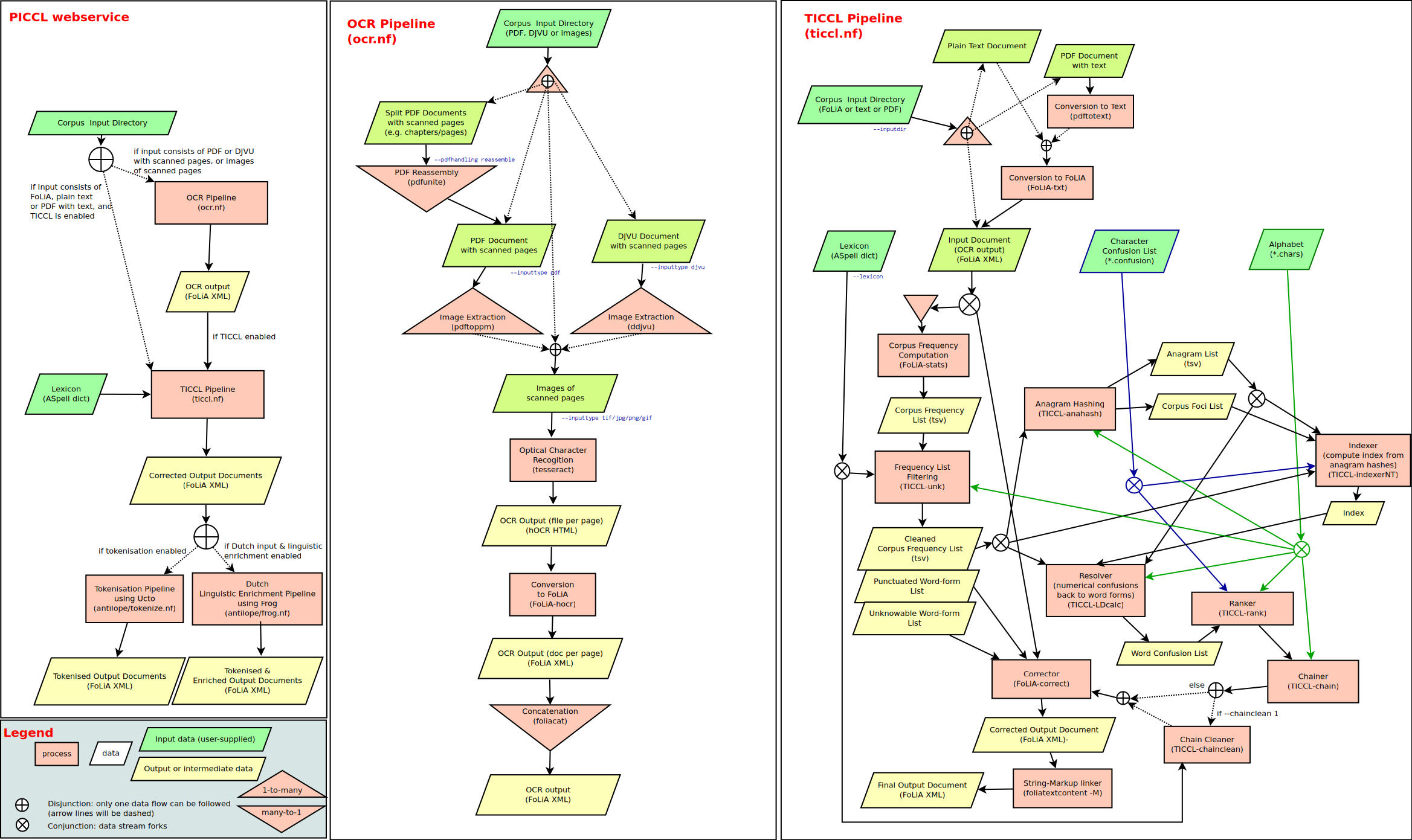
1 软件架构
- 软件基于
Python 3.7开发,界面基于PyQt 5,项目 完全开源。 - 软件在 macOS 10.15.1 、Windows 10 测试通过,Linux 平台用户亦可自行编译。
2 使用教程
2.1 获取 API(必需)
本软件调用了 讯飞 的 API(后续有望增加更多源,以提高准确率),目前的免费额度为 500次 / 天,可以满足个人用户的使用需求。
在进行识别前,需要先自行申请 API 额度,然后在软件的 设置 页面,填写获得的 API。
API 的获取方法如下:
-
进入讯飞开放平台注册页面,注册一个新的账号;
-
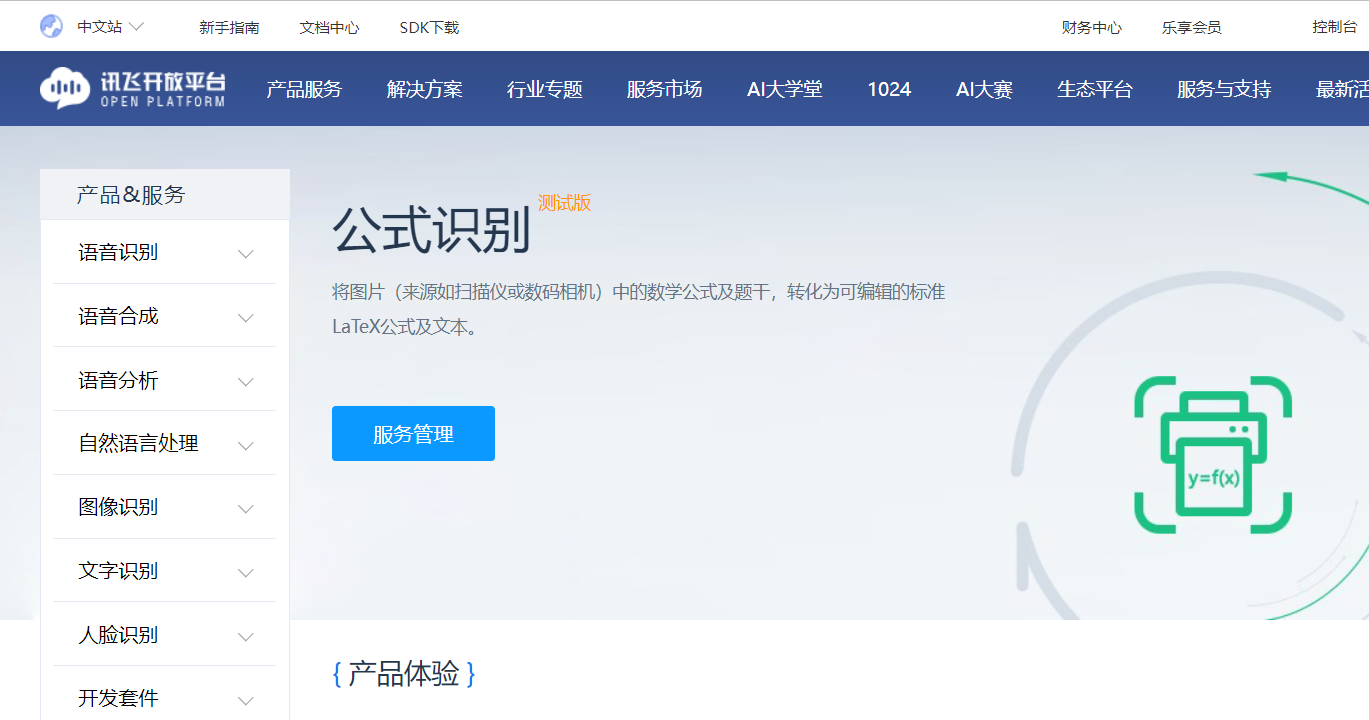
进入公式识别业务页面,可以在首页顶栏的 “产品服务 - 文字识别 - 公式识别” 中找到;
-
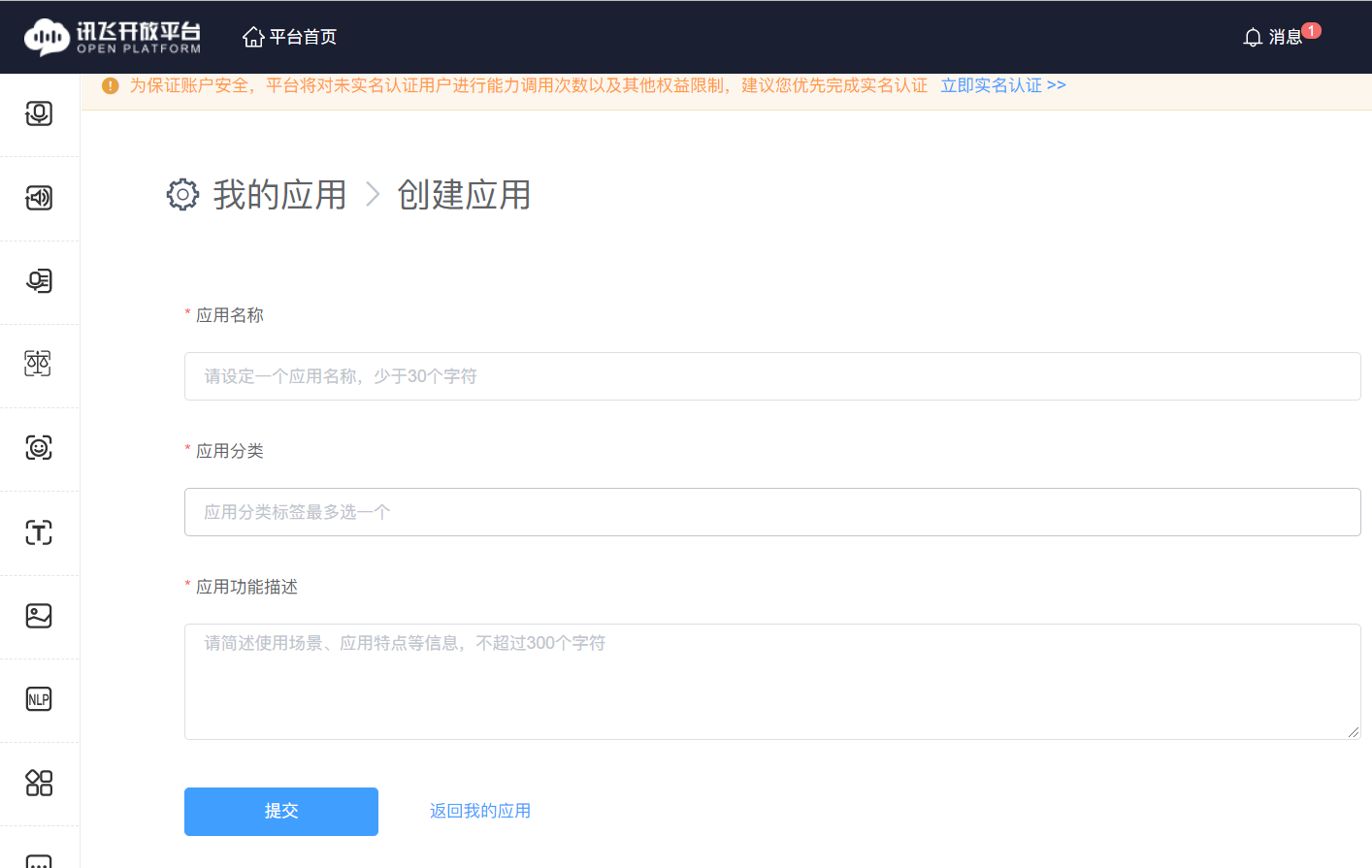
点击 “服务管理”,会提示创建一个应用(如果之前没有账号的话),界面如下图所示。
依次填写 “应用名称”、“应用分类” 与 “应用功能描述” 项,可以按自己喜好任意填写。
-
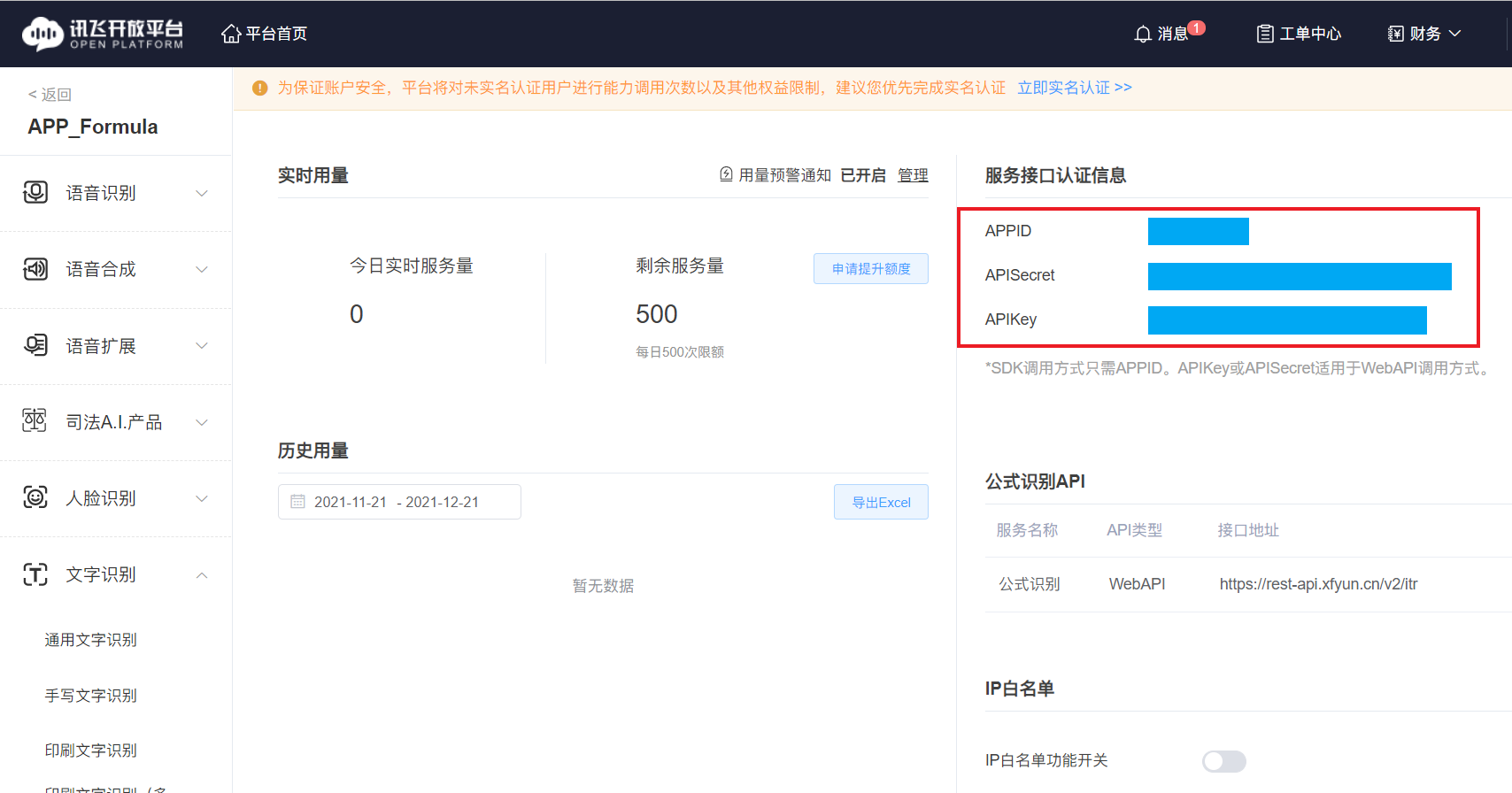
点击 “提交” ,即可进入服务管理页面,如下图所示。
右侧的 APPID 、 APISecret 、 APIKey 三项,即是我们需要的 API 值。
2.2 将获取的 API 填入软件
-
进入软件,点击
设置页面,可以看到如下图所示的界面。 -
将获取到的 APPID 、 APISecret 、 APIKey 三项,分别填入对应的位置,然后点击
确定。
至此,软件已经配置成功!可以选择需要的公式,进行识别了!
3 开发说明
3.1 软件需求
-
Python IDE 及环境:PyCharm Community 2020.2 + Python 3.7
- 建议新建项目及 venv 虚拟环境进行开发。
- 注意:在上述开发环境中,较高的 pip 版本似乎会导致在 PyCharm 中添加包失败。如果出现了同样的错误,请使用命令行将 pip 版本手动降级至 20.2.4 及以下,或尝试使用最新版本的 PyCharm。
-
GUI 编辑工具:PyQt5
-
安装 Qt Designer,随后在 对应的 PyCharm 工程中配置 External Tools:Qt Designer 、 PyUIC 与 PyRcc。
-
可参照下列教程进行配置:
-
若不需要使用 Qt Designer 进行可视化开发,或不打算对界面 GUI 进行修改,可以不安装 pyqt5-tools 包,在配置 External Tools 的过程中也不需要配置 Qt Designer 与 PyUIC 项。
-
3.2 文件树
- /Examples :存放示例图片。
- main_v104.py:软件主程序。
- 此文件调用了 Init_Window_v104.py 与 OCR_iFLY_v104.py 中定义的类。
- Init_Window_v104.py:PyQt GUI 控件定义及绘制源码,使用 PyUIC 生成。
- Init_Window_v104.ui:Qt 窗口样式文件,可使用 Qt Designer 打开及编辑。
- OCR_iFLY_v104.py:定义公式识别相关后端函数(讯飞接口)。
- config.ini:配置文件,存放公式图片路径及 API 参数。
- requirements.txt:程序的依赖项列表。
3.3 依赖配置
-
程序的第三方依赖项已经包含在根目录的 requirements.txt 文档中,使用 pipreqs 生成。
-
除此之外,还包含一个使用 pip freeze 命令生成的 requirements_all.txt 文档,包含此程序所需的所有依赖包。
可以根据需求,选用以上两个文档中的一个。
-
文档的使用方式:
在命令行或使用 PyCharm 建立的虚拟环境中,使用以下命令:
pip install -r requirements.txt
3.4 调试方法
- 在 PyCharm 等 IDE 中,使用 requirements.txt 安装好相关依赖,随后运行 main_v104.py ,即可运行程序。
- 程序的部分运行状态(如图片加载状态、公式识别结果完整 JSON 文本等)会输出到终端中,便于实时查看和调试。
4 目前已知的问题
- 请勿使用 Windows 记事本直接编辑及保存 config.ini 配置文件!!!
- 原因:Windows 记事本默认使用 ANCI 编码方式保存文件,而本程序使用 utf-8 编码格式读取,在读取中文路径 的时候会产生冲突。
- 报错解决方式:若程序无法打开,并提示:UnicodeDecodeError:'utf-8' code can't ... ,则执行以下步骤:
- 使用记事本打开 config.ini 文件,选择 “文件 - 另存为”;
- 文件名填写 “config.ini”,保存类型填写 “所有文件”,最下方的编码选择 “utf-8”。
- 确认替换,重新打开软件即可。
- 对于结构比较复杂的公式,识别准确率不高。后续将尝试引入其他识别 API 以提高准确率。
5 参与贡献
这个软件的界面和功能还非常原始,随时欢迎大家对它进行后续的开发。
- Fork 本仓库
- 新建 Feat_xxx 分支
- 提交代码
- 新建 Pull Request
6 关于作者
软件作者:青尘工作室
官方网站:https://qingchen1995.gitee.io
本程序 GitHub 仓库地址:https://github.com/QingchenWait/QC-Formula

 444 Dec 30, 2022
444 Dec 30, 2022
 38 Dec 5, 2022
38 Dec 5, 2022
 38 Oct 14, 2022
38 Oct 14, 2022
 41 Dec 27, 2022
41 Dec 27, 2022
 489 Dec 21, 2022
489 Dec 21, 2022
 646 Nov 11, 2022
646 Nov 11, 2022

 90 Dec 22, 2022
90 Dec 22, 2022
 32 Jul 24, 2022
32 Jul 24, 2022
 99 Nov 1, 2022
99 Nov 1, 2022

 7 Jan 04, 2023
7 Jan 04, 2023
 2 Dec 16, 2021
2 Dec 16, 2021
 0 Nov 01, 2021
0 Nov 01, 2021
 541 Dec 28, 2022
541 Dec 28, 2022
 208 Nov 15, 2022
208 Nov 15, 2022
 13.2k Jan 02, 2023
13.2k Jan 02, 2023
 4 Mar 19, 2022
4 Mar 19, 2022
 763 Jan 01, 2023
763 Jan 01, 2023
 120 Dec 28, 2022
120 Dec 28, 2022
 4 May 29, 2022
4 May 29, 2022
 23 Oct 05, 2021
23 Oct 05, 2021
 363 Jan 03, 2023
363 Jan 03, 2023
 13 Mar 31, 2022
13 Mar 31, 2022
 815 Dec 29, 2022
815 Dec 29, 2022
 1 Jan 05, 2022
1 Jan 05, 2022
 1.9k Jan 02, 2023
1.9k Jan 02, 2023
 343 Dec 24, 2022
343 Dec 24, 2022
 283 Jan 05, 2023
283 Jan 05, 2023
 6 Apr 16, 2022
6 Apr 16, 2022
 154 Dec 07, 2022
154 Dec 07, 2022