Neural Module Network (NMN) for VQA in Pytorch
Note: This is NOT an official repository for Neural Module Networks.
NMN is a network that is assembled dynamically by composing shallow network fragments called modules into a deeper structure. These modules are jointly trained to be freely composable. This is a PyTorch implementation of Neural Module Networks for Visual Question Answering. Most Ideas are directly taken from the following paper:
Neural Module Networks: Jacob Andreas, Marcus Rohrbach, Trevor Darrell and Dan Klein. CVPR 2016.
Please cite the above paper in case you use this code in your work. The instructions to reproduce the results can be found below, but first some results demo:
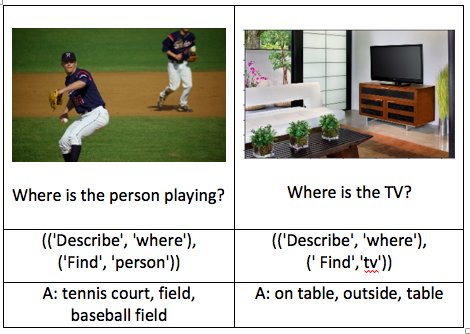
Demo:
More results can be seen with visualize_model.ipynb.
 |
 |
|---|---|
 |
 |
Dependencies:
Following are the main python dependencies of the project: torch, torchvision caffe, matplotlib, numpy, matplotlib and sexpdata.
You also need to have stanford parser available. Once dowloaded, make sure to set STANFORDPARSER in .bashrc so that directory $STANFORDPARSER/libexec/ has stanford-parser.jar
Download Data:
You need to download Images, Annotations and Questions from VQA website. And you need to download VGG model file used to preprocess the images. To save you some efforts of making sure downloaded files are appropriate placed in directory structure, I have prepared few download.txt's'
Run the following command in root directory find . | grep download.txt. You should be able to see the following directories containing download.txt:
./preprocessing/lib/download.txt
./raw_data/Annotations/download.txt
./raw_data/Images/download.txt
./raw_data/Questions/download.txt
Each download.txt has specific instruction with wget command that you need to run in the respective directory. Make sure files are as expected as mentioned in corresponding download.txt after downloading data.
Proprocessing:
preprocessing directory contains the scripts required to preprocess the raw_data. This preprocessed data is stored in preprocessed_data. All scripts in this repository operate on some set. When you download the data, the default sets (directory names) are train2014 and val2014. You can build a question type specific subsets like train2014-sub, val2014-sub by using pick_subset.py. You need to be sure that training / testing / validation set names are consistent in the following scripts (generally set at top of code). By default, everything would work on default sets, but if you need specific set, you need to follow the comments below. You need to run the following scripts in order:
1. python preprocessing/pick_subset.py [# Optional: If you want to operate on spcific question-type ]
2. python preprocessing/build_answer_vocab.py [# Run on your Training Set only]
3. python preprocessing/build_layouts.py [# Run on your Training Set only]
4. python preprocessing/build_module_input_vocab.py [# Run on your Training Set only]
5. python preprocessing/extract_image_vgg_features.py [# Run on all Train/ Test / Val Sets]
ToDo: Add setting.py to make sure set-names can be globally configured for experiment.
Run Experiments:
You can start training the model with python train_cmp_nn_vqa.py. The accuracy/loss logs will be piped to logs/cmp_nn_vqa.log. Once training is done, the selected model will be automatically saved at saved_models/cmp_nn_vqa.pt
Visualize Model:
The results can be visualized by running visualize_model.ipynb and selecting model name which was saved.
Evaluate Model:
The model can be evaluated by running python evaluation/evaluate.py. A short summary report should be seen on stdout.
To Do:
- Add more documentation
- Some more code cleaning
- Document results of this implementation on VQA datset
- Short blog on implementing NMN in PyTorch
Any Issues?
Please shoot me an email at [email protected]. I will try to fix it as soon as possible.

 3 Sep 18, 2021
3 Sep 18, 2021
 100 Dec 15, 2022
100 Dec 15, 2022
 66 Dec 11, 2022
66 Dec 11, 2022
 31 Nov 06, 2022
31 Nov 06, 2022
 813 Jan 04, 2023
813 Jan 04, 2023
 54 Dec 20, 2022
54 Dec 20, 2022
 3 Dec 30, 2022
3 Dec 30, 2022
 14 Nov 28, 2022
14 Nov 28, 2022
 221 Dec 30, 2022
221 Dec 30, 2022
 1.4k Dec 30, 2022
1.4k Dec 30, 2022
 1 Feb 09, 2022
1 Feb 09, 2022
 256 Jan 05, 2023
256 Jan 05, 2023
 85 Oct 18, 2022
85 Oct 18, 2022
 50 Dec 26, 2022
50 Dec 26, 2022
 30 Oct 31, 2022
30 Oct 31, 2022
 6 Jan 05, 2023
6 Jan 05, 2023
 459 Dec 27, 2022
459 Dec 27, 2022
 102 Jan 06, 2023
102 Jan 06, 2023
 1.7k Jan 06, 2023
1.7k Jan 06, 2023
 193 Dec 30, 2022
193 Dec 30, 2022