当前位置:网站首页>[datawhale] [machine learning] Diabetes genetic risk detection challenge
[datawhale] [machine learning] Diabetes genetic risk detection challenge
2022-07-26 09:41:00 【myaijarvis】
Diabetes genetic risk testing challenge
Introduction to the contest question
By 2022 year , Diabetes mellitus in China 1.3 Billion . The causes of diabetes in China are influenced by lifestyle 、 Aging 、 Urbanization 、 Family heredity and other factors affect . meanwhile , People with diabetes tend to be younger .
Diabetes can lead to cardiovascular disease 、 Kidneys 、 Occurrence of cerebrovascular complications . therefore , Accurate diagnosis of individuals with diabetes has very important clinical significance . Early genetic risk prediction of diabetes will help to prevent the occurrence of diabetes .
Event address :https://challenge.xfyun.cn/topic/info?type=diabetes&ch=ds22-dw-zmt01
Match task
In this competition , You need to go through Training data set structure Genetic risk prediction model of diabetes , And then predict Test data set Whether the middle-aged individual has diabetes , Join us to help diabetes patients solve this problem “ Sweet troubles ”.
Question data
The competition data consists of training set and test set , The details are as follows :
- Training set : share 5070 Data , Used to build your forecasting model
- Test set : share 1000 Data , Used to verify the performance of the prediction model .
The training set data package contains 9 A field : Gender 、 Year of birth 、 Body mass index 、 Family history of diabetes 、 diastolic pressure 、 Oral glucose tolerance test 、 Insulin release test 、 Triceps brachii skinfold thickness 、 Signs of diabetes ( Data labels ).
Standard for evaluation
Use... In the two category task F1-score Indicators for evaluation ,F1-score The larger the size, the better the performance of the prediction model ,F1-score Is defined as follows :
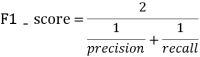
among :


Tips: According to the meaning , Diabetes genetic risk testing challenge will provide 2 Data sets , They are training data set and test data set , The training data set includes characteristic data and data labels ( Whether the patient has diabetes ), The test data set has only characteristic data , We need to Genetic risk prediction model of diabetes , The competitor evaluates the prediction accuracy of the model by testing the data set , The higher the accuracy of the model prediction, the better .
Ref:
Introduction
【 Reference resources : How to play a data mining competition - Introduction ——DATAWHALE - A community that loves learning 】
Competition questions Baseline
Tips: In this competition , We will provide python The code is used for the analysis of competition data and model construction , If you are not familiar with the relevant codes and principles in the competition , You can refer to relevant learning materials or in Datawhale Communicate in groups to solve the problems you encounter .
Install relevant third-party libraries
# Install dependent Libraries
!pip install lightgbm
!pip install pandas
!pip install sklearn
Import third-party library
Tips: In Ben baseline in , We go through pandas Process the data , adopt lightgbm Algorithm to build Genetic risk prediction model of diabetes
Ref:
import pandas as pd
import lightgbm
Data preprocessing
Tips: In this session , We usually need to check the quality of data , Including duplicate values 、 outliers 、 Missing value 、 Data distribution and data characteristics, etc , Through the preprocessing of training data , We can get higher quality training data , This helps to build a more accurate prediction model .
In Ben baseline in , We found that
diastolic pressureThere is a missing value in the feature , We use the method of filling in missing values , Of course, there are other ways to deal with it , If you are interested, you can try .Ref:
data1=pd.read_csv(' Game training set .csv',encoding='gbk')
data2=pd.read_csv(' Competition test set .csv',encoding='gbk')
# Test set label Marked as -1, In order to pick out the test set later
data2[' Signs of diabetes ']=-1
# The training set and test set are merged
data=pd.concat([data1,data2],axis=0,ignore_index=True)
# Fill the missing values in the diastolic blood pressure characteristics with -1
data[' diastolic pressure ']=data[' diastolic pressure '].fillna(-1)
Feature Engineering
Tips: In this session , We need to construct features of data , The aim is to extract features from the original data to the maximum extent for use by algorithms and models , This helps to build a more accurate prediction model .
Ref:
# Feature Engineering
""" Convert the year of birth into age """
data[' Year of birth ']=2022-data[' Year of birth '] # Change to age
""" The normal value of the body mass index for adults is 18.5-24 Between lower than 18.5 It's a low BMI stay 24-27 Between them is overweight 27 The above consideration is obesity higher than 32 You are very fat . """
def BMI(a):
if a<18.5:
return 0
elif 18.5<=a<=24:
return 1
elif 24<a<=27:
return 2
elif 27<a<=32:
return 3
else:
return 4
data['BMI']=data[' Body mass index '].apply(BMI)
# Family history of diabetes
""" No record One uncle or aunt has diabetes / One uncle or aunt has diabetes One parent has diabetes """
def FHOD(a):
if a==' No record ':
return 0
elif a==' One uncle or aunt has diabetes ' or a==' One uncle or aunt has diabetes ':
return 1
else:
return 2
data[' Family history of diabetes ']=data[' Family history of diabetes '].apply(FHOD)
""" The diastolic pressure range is 60-90 """
def DBP(a):
if a<60:
return 0
elif 60<=a<=90:
return 1
elif a>90:
return 2
else:
return a
data['DBP']=data[' diastolic pressure '].apply(DBP)
#------------------------------------
# The processed feature engineering is divided into training set and test set , The training set is used to train the model , The test set is used to evaluate the accuracy of the model
# There is no relationship between the number and whether the patient has diabetes , Irrelevant features shall be deleted
train=data[data[' Signs of diabetes '] !=-1]
test=data[data[' Signs of diabetes '] ==-1] # Take out the test set
train_label=train[' Signs of diabetes ']
train=train.drop([' Number ',' Signs of diabetes '],axis=1)
test=test.drop([' Number ',' Signs of diabetes '],axis=1)
Build the model
Tips: In this session , We need to train the training set to build the corresponding model , In Ben baseline And we used that Lightgbm Algorithm for data training , Of course, you can also use other machine learning algorithms / Deep learning algorithm , You can even synthesize the results predicted by different algorithms , Anyway, the final goal is to obtain higher prediction accuracy , Towards this goal ~
In this section , We will use training data 5 Fold cross validation training method for training , This is a good way to improve the accuracy of model prediction
Ref:
# Use Lightgbm Methods training data set , Use 5 Fold cross validation method to obtain 5 Test set prediction results
from sklearn.model_selection import KFold
def select_by_lgb(train_data,train_label,test_data,random_state=2022,n_splits=5,metric='auc',num_round=10000,early_stopping_rounds=100):
kfold = KFold(n_splits=n_splits, shuffle=True, random_state=random_state)
fold=0
result=[]
for train_idx, val_idx in kfold.split(train_data):
random_state+=1
train_x = train_data.loc[train_idx]
train_y = train_label.loc[train_idx]
test_x = train_data.loc[val_idx]
test_y = train_label.loc[val_idx]
clf=lightgbm
train_matrix=clf.Dataset(train_x,label=train_y)
test_matrix=clf.Dataset(test_x,label=test_y)
params={
'boosting_type': 'gbdt',
'objective': 'binary',
'learning_rate': 0.1,
'metric': metric,
'seed': 2020,
'nthread':-1 }
model=clf.train(params,train_matrix,num_round,valid_sets=test_matrix,early_stopping_rounds=early_stopping_rounds)
pre_y=model.predict(test_data)
result.append(pre_y)
fold+=1
return result
test_data=select_by_lgb(train,train_label,test)
#test_data Namely 5 In cross validation 5 The result of this prediction
pre_y=pd.DataFrame(test_data).T
# take 5 Calculate the average value of the prediction results , Of course, other methods can also be used
pre_y['averge']=pre_y[[i for i in range(5)]].mean(axis=1)
# Because the competition requires you to submit the final prediction and judgment , The prediction result given by the model is probability , So we think that probability >0.5 That is, the patient has diabetes , probability <=0.5 There is no diabetes
pre_y['label']=pre_y['averge'].apply(lambda x:1 if x>0.5 else 0)
pre_y
Results submitted
Tips: In this session , We need to submit the final prediction results to the data competition platform , It should be noted that we should strictly follow the file format submission requirements of the competition platform .
- Submit the address : https://challenge.xfyun.cn/topic/info?type=diabetes&ch=ds22-dw-zmt01
among result.csv The files that need to be submitted to the platform , Enter the data competition platform , Click on
Submit results, choice result.csv The document can complete the result submission
result=pd.read_csv(' Submit sample .csv')
result['label']=pre_y['label']
result.to_csv('result.csv',index=False)
follow-up
Through simple learning , We completed the diabetes genetic risk testing challenge baseline Mission , What should we do next ? It is mainly the following several aspects :
- Continue to try different prediction models or feature engineering to improve the accuracy of model prediction
- Join in Datawhale Competition exchange group , Get other more effective scoring information
- Refer to relevant data on genetic risk prediction of diabetes , Get other model building methods
- …
All in all , Is in the baseline On the basis of continuous transformation and try , Improve your data mining ability through continuous practice , As the saying goes 【 It's on paper , We must know that we must do it 】, Maybe you are proficient in machine learning algorithms , Be able to deduce various formulas skillfully , But how to apply the learned methods to practical engineering , We need to constantly try and improve , No model is a one-step result , To the final champion ~
Ref:
- Fishman : From data competition to work !
- Next Station , To the champion !
- My path to machine learning
- My introductory list and route of machine learning !
- Machine learning artifact Scikit-Learn Nanny course !
- 《Datawhale Artificial intelligence training program 》 Release !
Advanced ( It is highly recommended to read )
【 Reference resources : How to play a data mining competition - Introduction —— DATAWHALE 】

It is highly recommended to read , Well written , You can learn ideas and codes
- Logical regression ( fraction :0.74):
- Decision tree ( fraction :0.93):
- lightgbm edition 5 Crossover verification ( fraction :0.96):
- Model fusion
边栏推荐
- 高斯消元求解异或线性方程组
- 微信小程序图片无法显示时显示默认图片
- R language ggplot2 visualization: align the legend title to the middle of the legend box in ggplot2 (default left alignment, align legend title to middle of legend)
- 服务器、客户端双认证
- Unstoppable, pure domestic PCs have been in place, and the monopoly of the U.S. software and hardware system has been officially broken
- (1) Hand eye calibration of face scanner and manipulator (eye on hand)
- How to add a PDB
- (2) Hand eye calibration of face scanner and manipulator (eye out of hand: nine point calibration)
- Due to fierce competition in the new market, China Mobile was forced to launch a restrictive ultra-low price 5g package
- 解决npm -v突然失效 无反应
猜你喜欢
Does volatile rely on the MESI protocol to solve the visibility problem? (top)

The diagram of user login verification process is well written!

【Mysql数据库】mysql基本操作集锦-看得会的基础(增删改查)

R语言ggplot2可视化: 将图例标题(legend title)对齐到ggplot2中图例框的中间(默认左对齐、align legend title to middle of legend)

面试突击68:为什么 TCP 需要 3 次握手?

Redis sentinel mode setup under Windows

V-permission add permission

Due to fierce competition in the new market, China Mobile was forced to launch a restrictive ultra-low price 5g package

A new paradigm of distributed deep learning programming: Global tensor

配置ADCS后访问certsrv的问题
随机推荐
IIS website configuration
E. Two Small Strings
The difference between thread join and object wait
The combination of officially issued SSL certificate and self signed certificate realizes website two-way authentication
Antd treeselect gets the value of the parent node
Mo team learning notes (I)
搜索模块用例编写
服务器、客户端双认证(2)
IIS网站配置
Great reward for interview questions
服务器、客户端双认证
Matlab Simulink realizes fuzzy PID control of time-delay temperature control system of central air conditioning
The diagram of user login verification process is well written!
QT handy notes (II) edit control and float, qstring conversion
OFDM Lecture 16 - OFDM
Search module use case writing
调用DLL开启线程的问题
Global variables in DLL
Interview shock 68: why does TCP need three handshakes?
AR model in MATLAB for short-term traffic flow prediction