当前位置:网站首页>Supervised learning week 3: logistic regression option_ Lab harvest record
Supervised learning week 3: logistic regression option_ Lab harvest record
2022-07-18 23:17:00 【_ Doris___】
Catalog
1. skill one: Use Boolean index to draw pictures separately
3. In the course define Of loss and cost difference :
4.Cost Function for Logistic Regression
7.Logistic Regression using Scikit-Learn
8.To avoid the overfitting->Regularized Cost and Gradient Goals
1. skill one: Use Boolean index to draw pictures separately
x_train = np.array([0., 1, 2, 3, 4, 5])
y_train = np.array([0, 0, 0, 1, 1, 1])
X_train2 = np.array([[0.5, 1.5], [1,1], [1.5, 0.5], [3, 0.5], [2, 2], [1, 2.5]])
y_train2 = np.array([0, 0, 0, 1, 1, 1])
pos = y_train == 1 #positive-> Be careful : The method adopted here is bool Indexes
neg = y_train == 0 #negeative
fig,ax = plt.subplots(1,2,figsize=(8,3))
#plot 1, single variable
ax[0].scatter(x_train[pos], y_train[pos], marker='x', s=80, c = 'red', label="y=1")
ax[0].scatter(x_train[neg], y_train[neg], marker='o', s=100,
label="y=0", facecolors='none', edgecolors=dlc["dlblue"],lw=3)
ax[0].set_ylim(-0.08,1.1)
ax[0].set_ylabel('y', fontsize=12)
ax[0].set_xlabel('x', fontsize=12)
ax[0].set_title('one variable plot')
ax[0].legend()
#plot 2, two variables
plot_data(X_train2, y_train2, ax[1])
ax[1].axis([0, 4, 0, 4])
ax[1].set_ylabel('$x_1$', fontsize=12)
ax[1].set_xlabel('$x_0$', fontsize=12)
ax[1].set_title('two variable plot')
ax[1].legend()
plt.tight_layout()
plt.show()
2. Be careful : of numpy
① One dimensional array C_ Connect by column
②1/1+z( When z When it is matrix , The operation , Each number will be operated in turn )
③NumPy has a function called exp(), which offers a convenient way to calculate the exponential ( 𝑒𝑧ez) of all elements in the input array (
z).

3. In the course define Of loss and cost difference :
Definition Note: In this course, these definitions are used:
Loss is a measure of the difference of a single example to its target value while the
Cost is a measure of the losses over the training set
4.Cost Function for Logistic Regression
Note that the variables X and y are not scalar values but matrices of shape (𝑚,𝑛m,n) and (𝑚𝑚,) respectively, where 𝑛𝑛 is the number of features and 𝑚𝑚 is the number of training examples.
def compute_cost_logistic(X, y, w, b): """ Args: X (ndarray (m,n)): Data, m examples with n features y (ndarray (m,)) : target values w (ndarray (n,)) : model parameters b (scalar) : model parameter""" m = X.shape[0] cost = 0.0 for i in range(m): z_i = np.dot(X[i],w) + b f_wb_i = sigmoid(z_i) cost += -y[i]*np.log(f_wb_i) - (1-y[i])*np.log(1-f_wb_i) cost = cost / m return cost

5.compute_gradient_logistic
def compute_gradient_logistic(X, y, w, b): """ Args: X (ndarray (m,n): Data, m examples with n features y (ndarray (m,)): target values w (ndarray (n,)): model parameters b (scalar) : model parameter Returns dj_dw (ndarray (n,)): The gradient of the cost w.r.t. the parameters w. dj_db (scalar) : The gradient of the cost w.r.t. the parameter b. """ m,n = X.shape dj_dw = np.zeros((n,)) #(n,) dj_db = 0. for i in range(m): f_wb_i = sigmoid(np.dot(X[i],w) + b) #(n,)(n,)=scalar err_i = f_wb_i - y[i] #scalar for j in range(n): dj_dw[j] = dj_dw[j] + err_i * X[i,j] #scalar dj_db = dj_db + err_i dj_dw = dj_dw/m #(n,) dj_db = dj_db/m #scalar return dj_db, dj_dw

6.Gradient Descent
def gradient_descent(X, y, w_in, b_in, alpha, num_iters): """ Args: X (ndarray (m,n) : Data, m examples with n features y (ndarray (m,)) : target values w_in (ndarray (n,)): Initial values of model parameters b_in (scalar) : Initial values of model parameter alpha (float) : Learning rate num_iters (scalar) : number of iterations to run gradient descent Returns: w (ndarray (n,)) : Updated values of parameters b (scalar) : Updated value of parameter """ J_history = [] # for graphing later w = copy.deepcopy(w_in) #avoid modifying global w within function b = b_in for i in range(num_iters): dj_db, dj_dw = compute_gradient_logistic(X, y, w, b) # Calculate the gradient and update the parameters w = w - alpha * dj_dw # Update Parameters using w, b, alpha and gradient b = b - alpha * dj_db if i<100000: # prevent resource exhaustion J_history.append( compute_cost_logistic(X, y, w, b) ) # Save cost J at each iteration if i% math.ceil(num_iters / 10) == 0: print(f"Iteration {i:4d}: Cost {J_history[-1]} ") # Print cost every at intervals 10 times or as many iterations if < 10 return w, b, J_history #return final w,b and J history for graphing

7.Logistic Regression using Scikit-Learn
① Dataset
import numpy as np X = np.array([[0.5, 1.5], [1,1], [1.5, 0.5], [3, 0.5], [2, 2], [1, 2.5]]) y = np.array([0, 0, 0, 1, 1, 1])②Fit the model
The code below imports the logistic regression model from scikit-learn. You can fit this model on the training data by calling
fitfunction.from sklearn.linear_model import LogisticRegression lr_model = LogisticRegression() lr_model.fit(X, y)③Make Predictions
see the predictions made by this model by calling the
predictfunction.y_pred = lr_model.predict(X) print("Prediction on training set:", y_pred)Prediction on training set: [0 0 0 1 1 1]④Calculate accuracy
calculate this accuracy of this model by calling the
scorefunction.print("Accuracy on training set:", lr_model.score(X, y))Accuracy on training set: 1.0
8.To avoid the overfitting->Regularized Cost and Gradient Goals
①theory and formula
②Cost functions with regularization
(i)Cost function for regularized linear regression
No punishment b
def compute_cost_linear_reg(X, y, w, b, lambda_ = 1): """ Args: X (ndarray (m,n): Data, m examples with n features y (ndarray (m,)): target values w (ndarray (n,)): model parameters b (scalar) : model parameter lambda_ (scalar): Controls amount of regularization Returns: total_cost (scalar): cost """ m = X.shape[0] n = len(w) cost = 0. for i in range(m): f_wb_i = np.dot(X[i], w) + b #(n,)(n,)=scalar, see np.dot cost = cost + (f_wb_i - y[i])**2 #scalar cost = cost / (2 * m) #scalar reg_cost = 0 for j in range(n): reg_cost += (w[j]**2) #scalar reg_cost = (lambda_/(2*m)) * reg_cost #scalar total_cost = cost + reg_cost #scalar return total_cost(ii)Cost function for regularized logistic regression
def compute_cost_logistic_reg(X, y, w, b, lambda_ = 1): """Args: X (ndarray (m,n): Data, m examples with n features y (ndarray (m,)): target values w (ndarray (n,)): model parameters b (scalar) : model parameter lambda_ (scalar): Controls amount of regularization Returns:total_cost (scalar): cost """ m,n = X.shape cost = 0. for i in range(m): z_i = np.dot(X[i], w) + b #(n,)(n,)=scalar, see np.dot f_wb_i = sigmoid(z_i) #scalar cost += -y[i]*np.log(f_wb_i) - (1-y[i])*np.log(1-f_wb_i) #scalar cost = cost/m #scalar reg_cost = 0 for j in range(n): reg_cost += (w[j]**2) #scalar reg_cost = (lambda_/(2*m)) * reg_cost #scalar total_cost = cost + reg_cost #scalar return total_cost #scalar③Gradient descent with regularization
(i) for regularized linear regression
def compute_gradient_linear_reg(X, y, w, b, lambda_): """ Args: X (ndarray (m,n): Data, m examples with n features y (ndarray (m,)): target values w (ndarray (n,)): model parameters b (scalar) : model parameter lambda_ (scalar): Controls amount of regularization Returns: dj_dw (ndarray (n,)): The gradient of the cost w.r.t. the parameters w. dj_db (scalar): The gradient of the cost w.r.t. the parameter b. """ m,n = X.shape #(number of examples, number of features) dj_dw = np.zeros((n,)) dj_db = 0. for i in range(m): err = (np.dot(X[i], w) + b) - y[i] for j in range(n): dj_dw[j] = dj_dw[j] + err * X[i, j] dj_db = dj_db + err dj_dw = dj_dw / m dj_db = dj_db / m for j in range(n): dj_dw[j] = dj_dw[j] + (lambda_/m) * w[j] return dj_db, dj_dw(ii)for regularized logistic regression
def compute_gradient_logistic_reg(X, y, w, b, lambda_): """Args: X (ndarray (m,n): Data, m examples with n features y (ndarray (m,)): target values w (ndarray (n,)): model parameters b (scalar) : model parameter lambda_ (scalar): Controls amount of regularization Returns dj_dw (ndarray Shape (n,)): The gradient of the cost w.r.t. the parameters w. dj_db (scalar) : The gradient of the cost w.r.t. the parameter b. """ m,n = X.shape dj_dw = np.zeros((n,)) #(n,) dj_db = 0.0 #scalar for i in range(m): f_wb_i = sigmoid(np.dot(X[i],w) + b) #(n,)(n,)=scalar err_i = f_wb_i - y[i] #scalar for j in range(n): dj_dw[j] = dj_dw[j] + err_i * X[i,j] #scalar dj_db = dj_db + err_i dj_dw = dj_dw/m #(n,) dj_db = dj_db/m #scalar for j in range(n): dj_dw[j] = dj_dw[j] + (lambda_/m) * w[j] return dj_db, dj_dw



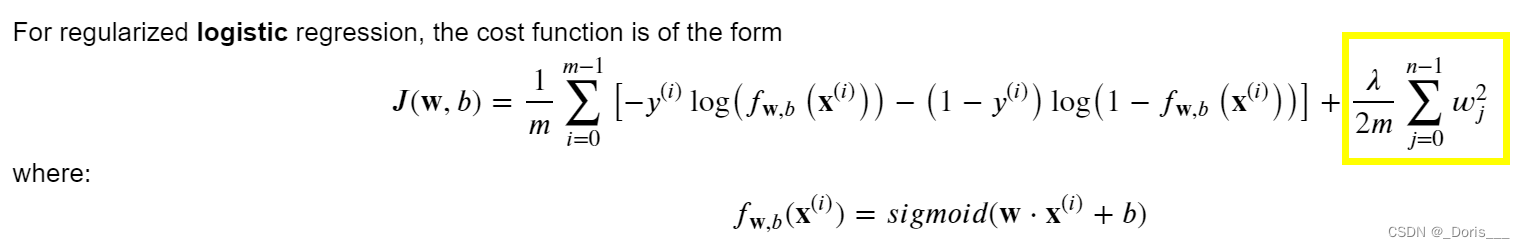

边栏推荐
- Why is SaaS so important for enterprise digital transformation?
- [CVPR2019] On Stabilizing Generative Adversarial Training with Noise
- 11(2).结构体的存储方式,结构体变量和结构体变量指针作为函数参数传递的问题,指针的优点
- Developers must see | devweekly issue 1: what is time complexity?
- PMP每日一练 | 考试不迷路-7.16
- 3D point cloud course (IV) -- clustering and model fitting
- Interviewer: tell me about the most valuable bug you found in your work
- C # network application programming, experiment 7: asynchronous programming practice
- "Interface automation" software tests the core skills of salary increase and increases salary by 200%
- Nosklattack tool installation and use problem solving
猜你喜欢

关于产品 | 要怎么进行产品规划?
![[C #] positive sequence, reverse sequence, maximum value, minimum value and average value](/img/a8/253bbae10b4d02c74a119d60ba10ad.png)
[C #] positive sequence, reverse sequence, maximum value, minimum value and average value
![[untitled]](/img/03/5c1a62d885b991186db8d554441695.png)
[untitled]

深入剖析斐波拉契数列

ospf综合实验

ZVS电路初步测试

开发者必看 | DevWeekly 第1期:什么是时间复杂度?
![[paddleseg source code reading] about the trivial matter that the paddleseg model returns a list](/img/a4/bc61237e6557762487783f21602973.png)
[paddleseg source code reading] about the trivial matter that the paddleseg model returns a list

Comparative investigation of three commonly used time series databases - incluxdb, Prometheus, iotdb

【开发教程3】疯壳·ARM功能手机-整板资源介绍
随机推荐
Encapsulation and invocation of old store classes in business class library
[remote desktop] rustdesk open source remote desktop, a substitute for TeamViewer and sunflower
Log collection scheme efk
ospf综合实验
Overflow valve Rexroth zdb10vp2-4x/315v
MySQL related commands
3大场景带你了解单元测试
T-infinite Road
[Ji Zhong] July 13, 2022 3058 Torchbearer
Error: the solution of diamond operator is not supported in -source 1.6
How to learn MySQL efficiently and systematically?
Shallow copy and deep copy
10 minutes to customize the pedestrian analysis system, detection and tracking, behavior recognition, human attributes all in one
[fluent -- actual combat] dart language quick start
C # - adding thread, loading case of progress bar, adding video effect for the first time
Nosklattack tool download and use
2022年软考网络管理员备考指南
Servo valve moogd634-374c
Database design pattern of multi tenant SaaS
Pytorch installation (very detailed)