当前位置:网站首页>Aperçu de l'apprentissage auto - supervisé
Aperçu de l'apprentissage auto - supervisé
2022-07-19 05:47:00 【Byzy】
Entrée sans étiquette,Apprendre un Expression de
Expression de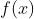 , Pour l'appliquer Plus efficace Résoudre les tâches en aval (Par exemple, classification:AvecAprès représentation,Vous pouvez utiliser un classificateur linéaire).
, Pour l'appliquer Plus efficace Résoudre les tâches en aval (Par exemple, classification:AvecAprès représentation,Vous pouvez utiliser un classificateur linéaire).
Étapes
Première étape:Apprendre un bon(Je ne sais pas quelle est la tâche en aval pour le moment.,C'est la différence entre l'apprentissage auto - supervisé et l'apprentissage semi - supervisé.).
Deuxième étape:UtiliserEtPetite quantitélabelEt résoudre le problème de classification à l'aide d'un modèle linéaire.
Idées:Établissement d'un problème d'apprentissage supervisé par l'homme à l'aide d'une structure de données non étiquetées,Et ensuite résoudre le problème avec un apprentissage profond(Dans ce processus,Peut - être qu'il crée une expression interne utile pour la tâche suivante![]() ).
).
Classification: L'apprentissage auto - supervisé est divisé en apprentissage génératif et en apprentissage comparatif. .
Apprentissage génératif
Générer des étiquettes manuelles pour prévoir , Apprendre à s'exprimer dans ce processus .
【Exemple】Reconnaissance numérique manuscrite
Première étape: Générer des étiquettes manuelles , Apprendre à exprimer
Tourner l'image à un angle (Par exemple: ), Étiquette manuelle avec angle de rotation .AvecConvNet Angle de rotation prévu .Et mettreheadEnlevez,Je l'ai.embedding().
), Étiquette manuelle avec angle de rotation .AvecConvNet Angle de rotation prévu .Et mettreheadEnlevez,Je l'ai.embedding().
Deuxième étape: Ajouter un en - tête de classification pour la reconnaissance manuscrite des chiffres (Classificateur linéaire), Former cet en - tête de classification à l'aide de données réellement étiquetées .
Les résultats expérimentaux montrent que le classificateur linéaire est très efficace. .
Apprentissage comparatif
Trouver une expression qui rend les entrées similaires très similaires , Les entrées non similaires sont caractérisées par une faible similitude .
【Exemple1】 Application du traitement du langage naturel —— Trouver la bonne expression dans la phrase
Choisissez une phrase Et sa prochaine phrase  (Échantillon positif; Penser que les phrases adjacentes ont des informations sémantiques similaires ), Plus une phrase aléatoire
(Échantillon positif; Penser que les phrases adjacentes ont des informations sémantiques similaires ), Plus une phrase aléatoire  (Échantillon négatif; Les pensées et les phrases Il y a différentes informations sémantiques ),Objectifs:
(Échantillon négatif; Les pensées et les phrases Il y a différentes informations sémantiques ),Objectifs:
![\min_f E\left [ \log\left ( 1+e^{f(x)^Tf(x^-)-f(x)^Tf(x^+)} \right ) \right ]](http://img.inotgo.com/imagesLocal/202207/19/202207170508421494_14.gif)
Est en fait de minimiser le produit intérieur de l'expression de phrases non contiguës (Similitude), Maximiser le produit intérieur de l'expression des phrases adjacentes ( Ici, la fonction de perte est appelée perte de contraste ).
【Exemple2】 Appliquer l'apprentissage par contraste aux images ——SimCLR
Lien vers le texte original:https://arxiv.org/pdf/2002.05709.pdf
(1) Utilisation accrue des données (Culture aléatoire&Zoom,random color distortion,random Gaussian blur) Créer deux vues connexes d'un graphique : (Générer un échantillon positif);
(Générer un échantillon positif);
(2)Utilisation de l'encodeur(Par exemple:ResNet)Je l'ai. ,Appeléembedding(Correspondant à);
,Appeléembedding(Correspondant à);
(3)Utiliser une double coucheMLP( )Oui.
)Oui. Convertir en
Convertir en (Appeléprojection head);
(Appeléprojection head);
(4)Fonction de perte:
 Défini comme suit:
Défini comme suit: Et
Et Similitude cosinus de.Choisir
Similitude cosinus de.Choisir Images pour 1- Oui.batch, Avec son élargissement à
Images pour 1- Oui.batch, Avec son élargissement à  Images
Images ,Calculer la matrice de similarité
,Calculer la matrice de similarité ,Parmi eux
,Parmi eux .
.
Éléments diagonaux
( Chaque image a la plus grande similitude avec elle - même ), Entre les autres échantillons positifs
Pour se rapprocher
Nombre de( La similitude de chaque image avec son extension est proche du maximum ), Les autres endroits devraient être petits. .
 ( Chaque image a la plus grande similitude avec elle - même ), Entre les autres échantillons positifs
( Chaque image a la plus grande similitude avec elle - même ), Entre les autres échantillons positifs  Pour se rapprocher
Pour se rapprocher Nombre de( La similitude de chaque image avec son extension est proche du maximum ), Les autres endroits devraient être petits. .
Nombre de( La similitude de chaque image avec son extension est proche du maximum ), Les autres endroits devraient être petits. .
Contient la matrice de similarité iNormalisation des lignes

Réduction au minimum de la somme des pertes entre les échantillons positifs ;
Et
Tous
Et
Similitude, En théorie, ça devrait être pareil , Mais la normalisation ci - dessus conduit à la différence , Alors prenez la moyenne .
 Et
Et Tous
TousQuelques conclusions :
(1) La composition élargie des données est importante ( Mélange de plusieurs options d'expansion , Plus que d'utiliser seulement 1 Le Programme d'expansion des semences fonctionne bien );
(2)Grandebatchsize Et de longues séances d'entraînement ;
(3) Introduction d'une double couche MLP() Bon pour le résultat final .
边栏推荐
- 2021-05-21
- Android realizes truly safe exit from App
- Unable to determine Electron version. Please specify an Electron version
- 基于四叉树的图像压缩问题
- MySQL learning notes (4) - (basic crud) operate the data of tables in the database
- Transform the inriapearson data set into Yolo training format and visualize it
- Face detection based on OpenCV and face interception
- Paddle的OCR标签转化为TXT格式
- 多模态融合方法总结
- CV-Model【3】:VGG16
猜你喜欢

static 关键字对作用域和生命周期的影响

微信小程序的常用组件

Try some methods to solve the delay of yolov5 reasoning RTSP

Page navigation of wechat applet

软件过程与管理复习(十)

8. ODS layer construction of data warehouse

seq2seq (中英对照翻译)Attention

Pointnet++ code details (II): Square_ Distance function

微信小程序中的WXML模板语法

DEEP JOINT TRANSMISSION-RECOGNITION FOR POWER-CONSTRAINED IOT DEVICES
随机推荐
Use of MySQL
CV学习笔记【1】:transforms
Run yolov5 process record based on mindspire
Face detection based on OpenCV and face interception
BottomSheetDialogFragment仿制抖音评论框
Kotlin scope function
软件过程与管理总复习
配置tabBar和request网络数据请求
dlib库和.dat文件地址
OpenCV读取中文路径下的图片,并对其格式转化不改变颜色
Selective Kernel Networks方法简单整理
对比学习用于图像语义分割(两篇文章)
JNI practical notes
简单Web服务器程序设计与实现
深度聚类相关(三篇文章)
微信小程序的常用组件
SGM: Sequence Generation Model for Multi-Label Classification(用于多标签分类的序列生成模型)
DEEP JOINT TRANSMISSION-RECOGNITION FOR POWER-CONSTRAINED IOT DEVICES
Unable to determine Electron version. Please specify an Electron version
Geo_ CNN (tensorflow version)