当前位置:网站首页>SGM: Sequence Generation Model for Multi-Label Classification(用于多标签分类的序列生成模型)
SGM: Sequence Generation Model for Multi-Label Classification(用于多标签分类的序列生成模型)
2022-07-17 05:10:00 【一锅炖海鲜】
2018年最好的nlp文章,先说结论,有些参考的价值可以分享一下:
总结:

SSG模型细节和实现。
模型图:

Encoder
令 (X1,X2,X3,Xm)为 m 个单词的序列。我们首先通过一个嵌入矩阵 (embedding matrix),把 嵌入成一个稠密的嵌入向量 , |V|是词汇表的大小, k 是嵌入向量的维度。
我们使用一个bidirectional LSTM 从两个方向上来读取文本序列 x,并且计算每个单词的隐藏状态:

我们通过连接两个方向上的隐藏状态来得到第 i个单词的最终隐藏状态,

这使得状态具有以第 i 个单词为中心的序列信息。


这里的pack可以去pytorch官网搜一下这个官方定义的函数
pack_padded_sequence
当模型预测不同的标签的时候,并不是所有的单词贡献相同。注意力机制会通过关注文本序列中的不同部分,产生一个上下文向量 (context vector)。
特别的,本文采用的 Attention 是 global attention,什么是global attention,这里我列举一下:

原文中是这么写的,我们可以对照一下:

其中注意力模型用的是加性模型。

Decoder
这里在序列生成模型的 decode 部分进行了改造,不但考虑了标签间相关性,还自动获取了输入文本的关键信息(Attention机制)
Decoder在第 t 时刻的隐藏状态计算如下:

其中,[g(yt−1); ct−1] 的意思是g(yt−1) 和 ct−1. g(yt−1) 的连接, g(yt−1) 是标签的嵌入,这里的标签指的是在 yt-1 分布下的最高概率对应的标签。yt-1是在t-时刻在标签空间 L上的概率分布,计算如下
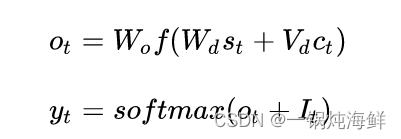
class rnn_decoder(nn.Module):
def __init__(self, config, embedding=None, use_attention=True):
super(rnn_decoder, self).__init__()
self.config = config
self.hidden_size = config.hidden_size
self.embedding = embedding if embedding is not None else nn.Embedding(config.tgt_vocab_size, config.emb_size)
input_size = 2 * config.emb_size if config.global_emb else config.emb_size
if config.cell == 'gru':
self.rnn = StackedGRU(input_size=input_size, hidden_size=config.hidden_size,
num_layers=config.dec_num_layers, dropout=config.dropout)
else:
self.rnn = StackedLSTM(input_size=input_size, hidden_size=config.hidden_size,
num_layers=config.dec_num_layers, dropout=config.dropout)
self.linear = nn.Linear(config.hidden_size, config.tgt_vocab_size)
if not use_attention or config.attention == 'None':
self.attention = None
elif config.attention == 'bahdanau':
self.attention = attention.bahdanau_attention(config.hidden_size, input_size)
elif config.attention == 'luong':
self.attention = attention.luong_attention(config.hidden_size, input_size, config.pool_size)
elif config.attention == 'luong_gate':
self.attention = attention.luong_gate_attention(config.hidden_size, input_size)
self.dropout = nn.Dropout(config.dropout)
if config.global_emb:
self.ge_proj1 = nn.Linear(config.emb_size, config.emb_size)
self.ge_proj2 = nn.Linear(config.emb_size, config.emb_size)
self.softmax = nn.Softmax(dim=1)
def forward(self, input, state, output=None, mask=None):
embs = self.embedding(input)
if self.config.global_emb:
if output is None:
output = embs.new_zeros(embs.size(0), self.config.tgt_vocab_size)
probs = self.softmax(output / self.config.tau) #标签
# 两个张量矩阵相乘,在PyTorch中可以通过torch.matmul函数实现;(embedding.weight)ei表示时刻i 输出对应的 Embedding 的 label
emb_avg = torch.matmul(probs, self.embedding.weight)
#H 是 transform gate,用于控制带权平均嵌入的比例
H = torch.sigmoid(self.ge_proj1(embs) + self.ge_proj2(emb_avg))
emb_glb = H * embs + (1 - H) * emb_avg #g(yt-1)=(1-H)*e+H*e
embs = torch.cat((embs, emb_glb), dim=-1)
output, state = self.rnn(embs, state)#embs等于ei state貌似是Ct
if self.attention is not None:
if self.config.attention == 'luong_gate':
output, attn_weights = self.attention(output)
else:
output, attn_weights = self.attention(output, embs)
else:
attn_weights = None
output = self.compute_score(output)
if self.config.mask and mask: #mask softmax
# 沿一个新维度对输入张量序列进行连接,序列中所有张量应为相同形状;stack 函数返回的结果会新增一个维度,而stack()函数指定的dim参数,就是新增维度的(下标)位置。
mask = torch.stack(mask, dim=1).long()
output.scatter_(dim=1, index=mask, value=-1e7)
return output, state, attn_weightsGlobal Embedding


其中 H 是 transform gate,用于控制带权平均嵌入的比例。所有的 为权重矩阵。通过考虑每一个 label 的概率,模型可以减少先前时间步带来的错误预测的损失。这使得模型预测得更加准确。
- 问题: 多标签分类的输出显然是不能重复的。
- 解决方法: 作者在最终 Softmax 输出的时候引入了 It将已输出的标签剔除。
yt = sof tmax(ot + It)
的表示如下,如果标签已经被输出了,则 It 为负无穷,

- 问题: Seq2Seq 中某时刻 t 的输出对时刻 t+1 的输出影响很大,也就是说时刻 出错会对时刻 之后的所有输出造成严重影响。
- 解决方法: 在多标签分类问题中,我们显然不想让标签间拥有如此强的关联性,于是作者提出 Global Embedding 来解决这个问题。
此外,作者在数据预处理阶段也采用一些技巧。比如,考虑到出现次数更多的标签在标签相关性训练中具有更强的作用,在训练时把标签按照其出现次数进行从高到低排序作为输出序列。这么做的好处是,出现次数更多的标签可以出现 LSTM 的前面,进而更好地指导整个标签的输出。
论文来源:
SGM: Sequence Generation Model for Multi-label Classification
边栏推荐
猜你喜欢







随机推荐
MySQL learning notes (5) -- join join table query, self join query, paging and sorting, sub query and nested query
zTree自定义Title属性
gradle
4. Neusoft cross border e-commerce data warehouse project - user behavior data acquisition channel construction of data acquisition channel construction (2022.6.1-2022.6.4)
Advanced operation of C language
CV-Model【1】:Mnist
Android realizes truly safe exit from App
10. DWD layer construction of data warehouse construction
1. Neusoft cross border e-commerce warehouse demand specification document
Ambari2.7.5 integration es6.4.2
USB转TTL CH340模块安装(WIN10)
微信小程序中的WXML模板语法
关于Kotlin泛型遇到的问题
JNI实用笔记
用facenet源码进行人脸识别测试过程中的一些问题
Common components of wechat applet
Geo_CNN(Tensorflow版本)
8. ODS layer construction of data warehouse
class文件格式的理解
ES6 adds -let and const (disadvantages of VaR & let and const)