当前位置:网站首页>电商用户行为实时分析系统(Flink1.10.1)
电商用户行为实时分析系统(Flink1.10.1)
2022-07-17 05:09:00 【Mmj666】
文章目录
【实验题目】电商用户行为实时分析系统
【实验描述】
电商平台中的用户行为频繁且较复杂,系统上线运行一段时间后,可以收集到大量的用户行为数据,进而利用大数据技术进行深入挖掘和分析,得到感兴趣的商业指标并增强对风险的控制。
对于电商用户行为的数据,电商用户行为数据多样,整体可以分为用户行为习惯数据和业务行为数据两大类。
用户的行为习惯数据包括了用户的登录方式、上线的时间点及时长、点击和浏览页面、页面停留时间以及页面跳转等等,我们可以从中进行流量统计和热门商品的统计,也可以深入挖掘用户的特征;这些数据往往可以从 web 服务器日志中直接读取到。
而业务行为数据就是用户在电商平台中针对每个业务(通常是某个具体商品)所作的操作,我们一般会在业务系统中相应的位置埋点,然后收集日志进行分析。业务行为数据又可以简单分为两类:一类是能够明显地表现出用户兴趣的行为,比如对商品的收藏、喜欢、评分和评价,我们可以从中对数据进行深入分析,得到用户画像,进而对用户给出个性化的推荐商品列表,这个过程往往会用到机器学习相关的算法;另一类则是常规的业务操作,但需要着重关注一些异常状况以做好风控,比如登录和订单支付。
该项目主要涉及到两个模块,实时统计分析模块和业务流程及风险控制模块,详细模块信息如下所示:
实时统计分析模块:
- 实时热门商品统计
- 实时热门页面流量统计
- 实时访问流量统计
- APP市场推广统计
- 页面广告点击量统计
业务流程及风险控制模块:
- 页面广告黑名单过滤
- 恶意登录监控
- 订单支付失效监控
该项目共八个功能点。在本次的项目当中,我们的技术栈为Flink+Zookeeper+Kafka+Flume+Superset+Mysql+Redis。在该项目中,我们将综合运用 flink 的各种 API,基于 EventTime 去处理基本的业务需求,并且灵活地使用底层的 processFunction,基于状态编程和 CEP 去处理更加复杂的情形。
【实验目的】
掌握Flink生态组件的综合应用,能够融合Flink与Hadoop相关技术,能够应用相关技术解决实际问题。
综合应用Hadoop、Flink、Kafka、Flume等组件,合理的进行程序设计,实现一个小型的大数据综合分析案例,培养学生独立自主的分析问题、解决问题以及编程能力。
【实验时间】
2022年3月11日
【实验环境】
操作系统:Windows 10;
虚拟机环境:VMware Workstation 16 Pro;
Linux系统:CentOS 7
开发工具:IntelliJ IDEA 2020.2.1 x64
JDK环境:JDK 1.8.0_301。
Flink: 1.10.1
Hadoop版本:3.2.2
Zookeeper版本:3.6.3
Flume版本:1.9.0
Kafka版本:2.12-2.6.0
Mysql版本:8.0.26
Redis版本:2.4.5
Superset版本:1.2.0
Python版本:3.7(安装Superset时,需指定python版本为3.7)
【实验内容】
实验第一部分统计手机流量模块主要有以下四个需求:统计手机的上行流量、下行流量、总流量功能等共四个功能。实验第二部分连续登录失败检测模块有一个功能。本实验的功能点结构图如下图所示:
由于数据的限制,本次实验不再继续沿用Hadoop综合应用和Spark综合应用的数据集以及代码,而是重新另找数据集以及根据新的业务来进行代码的编写与展示。
该电商用户行为分析系统的内容主要包括实时统计分析模块和业务流程及风险控制模块两大部分,这两个模块的实现均使用实时的处理技术。
其中第一模块实时统计分析模块的功能点如下:
1.实时热门商品统计
2.实时热门页面流量统计
3.实时访问流量统计
4.APP市场推广统计
5.页面广告点击量统计
第二模块业务流程及风险控制模块实现的功能点如下:
1.页面广告黑名单过滤
2.恶意登录监控
3.订单支付失效监控
由于时间限制,本次仅对第一模块的功能点实现添加了可视化大屏的展示,由于第二模块主要涉及到业务流程以及一些告警的显示,因此第二模块的展示将放在控制台当中进行。
本项目的功能点结构图如下图所示:
本次项目的技术架构如下所示:
【实验步骤】
本次实验的话采取逐个模块进行编写的方式,总体实现步骤如下图所示
- 创建Maven项目
- 实时热门商品统计功能实现
- 实时热门页面流量统计功能实现
- 实时访问流量统计功能实现
- APP市场推广统计功能实现
- 页面广告点击量统计功能实现
- 页面广告黑名单过滤功能实现
- 恶意登录监控功能实现
- 订单支付失效监控功能实现
- 安装superset并将上述模块数据与superset进行对接,制作可视化展示页面
接下来是详细的实验过程:
1. 创建Maven项目
1.1项目框架搭建
项目的框架为先建立一个maven项目,该项目中包含了多个模块,我们的每个功能点将在不同的模块当中进行分别实现,框架结构图如下图所示:
热门商品统计功能在HotItemsAnalysis模块当中实现。
实时热门页面流量统计功能在NetWorkFlowAnalysis模块当中实现
实时访问流量统计功能也在NetWorkFlowAnalysis模块当中实现
APP市场推广统计功能在MarketAnalysis模块当中实现
页面广告点击量统计功能和页面广告黑名单过滤功能也在MarketAnalysis模块当中实现。
恶意登录监控功能在LoginFailDetect模块当中实现
订单支付失效监控功能在OrderPayDetect模块当中实现
CommonUtil模块放置的是进行数据库连接的通用类
MockDataProduct模块放置的是用来产生向kafka发送模拟数据的相关类
1.2 声明项目中工具的版本信息
我们在本次实验中,需要用到的一些工具的版本信息如下所示:
1.3 添加项目依赖
下面是我们需要添加的一些依赖信息:

以及一些插件信息:

至此为止,项目的整体框架搭建起来。
2. 实时热门商品统计功能实现
2.1 数据集分析以及模拟数据的生成
本功能在实现时使用的数据集有两种,首先是在csv文件中存的用户行为数据集:
其中第一个字段是用户id,第二个字段是物品id,第三个字段是物品的种类id,第四个字段是用户的行为,第五个字段是时间戳。
第二种数据就是我们根据上述的数据的形式来模拟生成数据,将数据每隔一定时间输入到kafka当中一批。
2.2 功能代码实现思路
实现一个“实时热门商品”的需求,该需求的具体描述为:每隔 5 分钟输出最近一小时内点击量最多的前 N 个商品。将这个需求进行分解大概要做以下几件事情:
• 抽取出业务时间戳,告诉 Flink 框架基于业务时间做窗口
• 过滤出点击行为数据
• 按一小时的窗口大小,每 5 分钟统计一次,做滑动窗口聚合(Sliding Window)
• 按每个窗口聚合,输出每个窗口中点击量前 N 名的商品
2.3 程序主体代码

我们实现的第一步是读取数据,注释掉的是从文件中读取数据,这里的话可以从文件或者kafka当中读数据。之后由于数据当中包含有时间戳,我们需要设置时间语义为EventTime。我们下一步将读取到的数据转换为POJO并分配时间戳和水位线。然后我们在进行分组开窗,得到每个窗口的各个商品的count值,收集同一窗口的所有商品的count数据,排序输出top n。
同时,为了后续我们进行图表的绘制,我们还需要在每个窗口统计count时,将数据也同步输入到数据库当中,方便后续与superset进行对接。
ItemCountAgg代码:
WindowItemCountResult代码: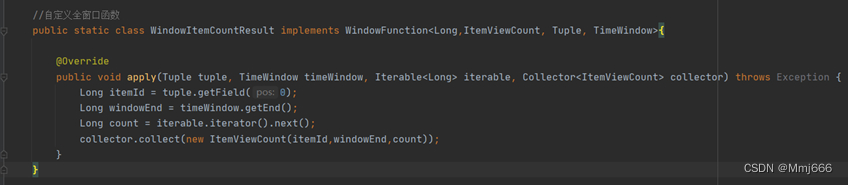
TopNHotItems代码:

该部分代码则是在定时器进行触发时,对商品信息进行统计输出,并且同步输出到数据库当中。
HotItemsDaoImpl代码:

该部分代码负责和数据库进行连接并向数据库进行数据插入的操作。
之后进行该模块的演示展示:
3.实时热门页面流量统计功能实现
3.1数据集分析以及模拟数据的生成
我们现在要实现的模块是 “实时流量统计”。对于一个电商平台而言,用户登录的入口流量、不同页面的访问流量都是值得分析的重要数据,而这些数据,可以简单地从 web 服务器的日志中提取出来。具体数据的形式如下: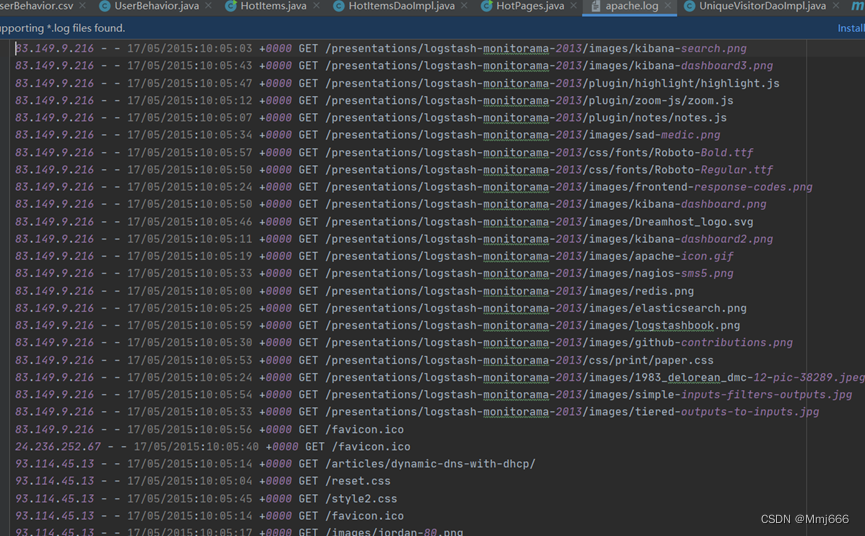
我们可以从数据中提取出有效信息并进行处理。后续为了进行模拟,我们还可以使用python脚本来不断向文件中生成模拟数据,来模拟日志生成的过程,之后使用flume进行日志的监听,将监听到的数据写入kafka当中。之后,flink再从kafka中获取数据进行业务处理即可。
3.2 功能代码实现思路
我们在这里先实现“热门页面浏览数”的统计,也就是读取服务器日志中的每一行 log,统计在一段时间内用户访问每一个 url 的次数,然后排序输出显示。
具体做法为:每隔 5 秒,输出最近 10 分钟内访问量最多的前 N 个 URL。可以看出,这个需求与之前“实时热门商品统计”非常类似,所以我们完全可以借鉴此前的代码。但需要注意的是,我们需要将读取到的时间转换成时间戳再进行使用。
3.3 完整代码


该部分代码是主体代码,我们注意到在日志时,每条数据的接收时间是无序的,因此我们需要使用BoundedOutOfOrdernessTimestampExtractor并且设置watermark,通过观察,我们先设置watermark为1s,并且设置允许数据迟到,迟到的时间为1分钟。之后可以设置测输出流,来将收集到的迟到的数据进行处理输出。
自定义聚合函数: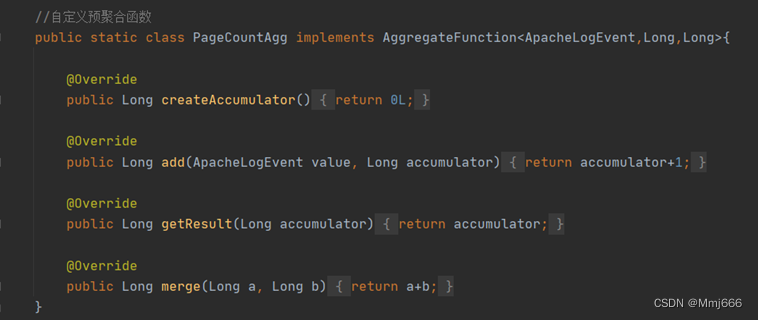
自定义窗口函数:
自定义处理函数:

我们可以看到,当定时器被触发时,我们便对当前窗口进行计算,统计出页面url在当前窗口下的浏览量。
最终在superset中展示的结果为:

4.实时访问流量统计功能实现
4.1 数据源分析以及模拟数据的生成
该部分的数据使用和在统计热门商品时的数据使用的是同一批数据,因此该部分分析可以看前面的分析,不过多赘述。
4.2 网站总浏览量(PV)的统计
用户浏览页面时,会从浏览器向网络服务器发出一个请求(Request),网络服务器接到这个请求后,会将该请求对应的一个网页(Page)发送给浏览器,从而产生了一个 PV。所以我们的统计方法,可以是从 web 服务器的日志中去提取对应的页面访问然后统计,就向上一节中的做法一样;也可以直接从埋点日志中提取用户发来的页面请求,从而统计出总浏览量。
具体代码实现如下所示:

该部分的实现较为简单,我们最直接的思路就是读入数据之后,先过滤出行为为pv的数据,之后在使用map+keyBy+timeWindow+sum的组合,便可以实现该功能。但是这样的话,实际上只使用了一个通道,因为keyBy的key都是“pv”,不是一个高效的方法。
因此,我们在后续进行了并行任务的改进,设计了随机的key,从而解决了数据倾斜的问题,如上图中显示的所示。
最终在superset中展示的结果如下图所示:

4.3 网站独立访客数(UV)的统计
该功能是统计1h内的访客的数量。该功能的实现其实和pv的实现类似,由于是独立访客,所以我们只需要在全窗口函数当中定义一个HashSet进行筛选即可,具体代码实现如下所示:

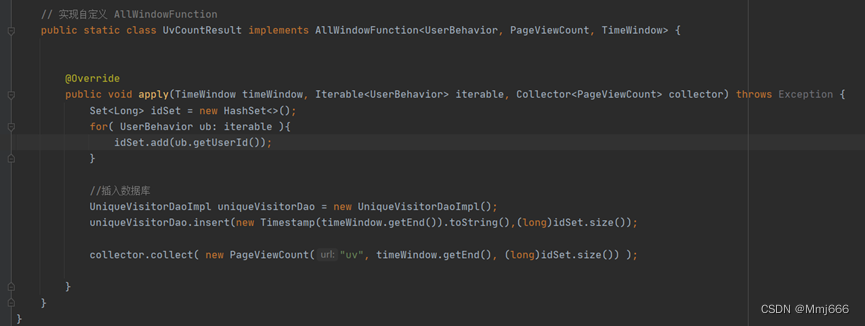
从图中我们可以看到,只需要在全窗口函数当中加一个HashSet来进行过滤筛选即可,考虑到需要进行图形界面展示,所有在此处处理时也同步加入到数据库当中。
最终在superset中展示的结果如下图所示:
4.4 使用布隆过滤器的 UV 统计
上面的做法中,我们把所有数据的 userId 都存在了窗口计算的状态里,在窗口收集数据的过程中,状态会不断增大。一般情况下,只要不超出内存的承受范围,这种做法也没什么问题;但如果我们遇到的数据量很大,那么则会内存不够使用。把所有数据暂存放到内存里,显然不是一个好注意。我们会想到,可以利用 redis这种内存级 k-v 数据库,为我们做一个缓存。但如果我们遇到的情况非常极端,数据大到惊人,比如上亿级的用户,要去重计算 UV。如果放到 redis 中,亿级的用户 id(每个 20 字节左右的话)可能需要几 G 甚至几十 G 的空间来存储。当然放到 redis 中,用集群进行扩展也不是不可以,但明显代价太大了。
因此,我们最终的方案是使用布隆过滤器。本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
完整的代码实现如下所示:

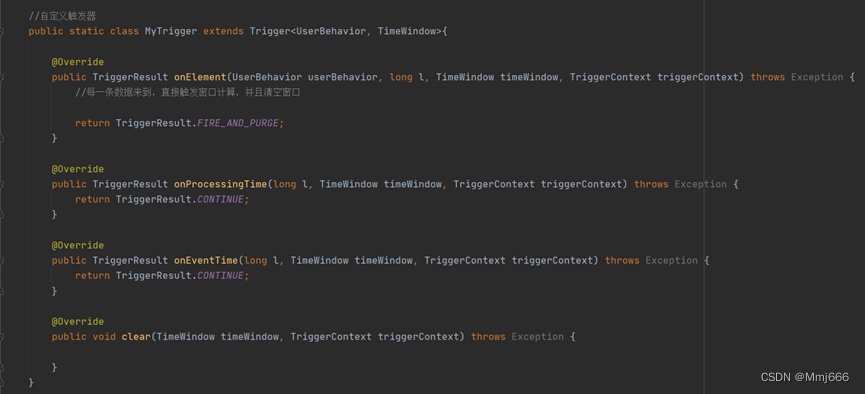



在该功能的实现上,我们使用到了触发器和自定义的布隆过滤器以及使用到了redis数据库。
5. APP市场推广统计功能实现
5.1 自定义数据源
随着智能手机的普及,在如今的电商网站中已经有越来越多的用户来自移动端,相比起传统浏览器的登录方式,手机 APP 成为了更多用户访问电商网站的首选。对于电商企业来说,一般会通过各种不同的渠道对自己的 APP 进行市场推广,而这些渠道的统计数据(比如,不同网站上广告链接的点击量、APP 下载量)就成了市场营销的重要商业指标。首先我们考察分渠道的市场推广统计。 由于我们没有具体的数据,因此我们进进行自定义数据源:
该数据源当中有用户的id,行为,渠道和时间戳。
5.2 分渠道统计思路
分渠道统计的设计思路较为简单,就是根据渠道和用户行为进行keyBy分组,之后再进行开窗统计即可,较为简单。
5.3 分渠道统计代码实现
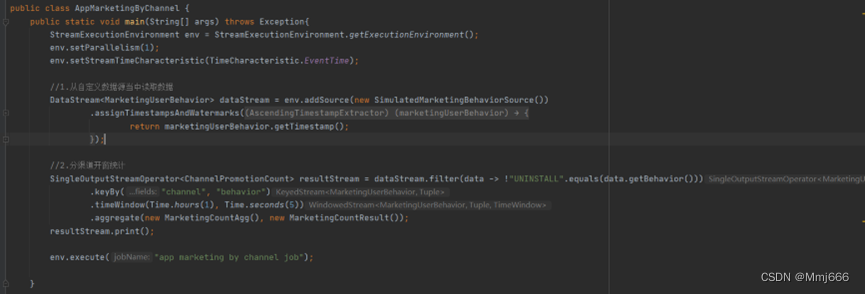

5.4 效果展示

我们可以实时统计不同渠道不同行为随时间的变化其热度的变化。
6. 页面广告点击量统计功能实现
6.1 数据集分析
我们进行页面广告按照省份划分的点击量的统计。在 src/main/java 下创建 AdStatisticsByProvince 类。同样由于没有现成的数据,我们定义一些测试数据,放在 AdClickLog.csv 中,用来生成用户点击广告行为的事件流。
数据集的格式如下所示:
其中第一个字段是用户id,第二个字段是广告id,第三个字段是省份,第四个字段是城市,第五个字段是时间戳。
6.2 功能实现思路
我们先读取文件并转换成对象,并且设置时间戳和水位线。之后我们基于省份进行分组并且开窗聚合。时间窗口大小为1h,滑动步长为5min。
6.3 代码实现


7. 页面广告黑名单过滤功能实现
7.1 功能需求分析
上节我们进行的点击量统计,同一用户的重复点击是会叠加计算的。在实际场景中,同一用户确实可能反复点开同一个广告,这也说明了用户对广告更大的兴趣;但是如果用户在一段时间非常频繁地点击广告,这显然不是一个正常行为,有刷点击量的嫌疑。所以我们可以对一段时间内(比如一天内)的用户点击行为进行约束,如果对同一个广告点击超过一定限额(比如 100 次),应该把该用户加入黑名单并报警,此后其点击行为不应该再统计。
7.2 功能数据集分析
数据集的话和上面数据集使用的是相同的数据集,就不进行多次分析。
7.3 代码设计思路
首先我们先从文件当中读取数据。之后,我们对同一个用户点击同一个广告超过20次的行为进行检测报警。
7.4 代码具体实现

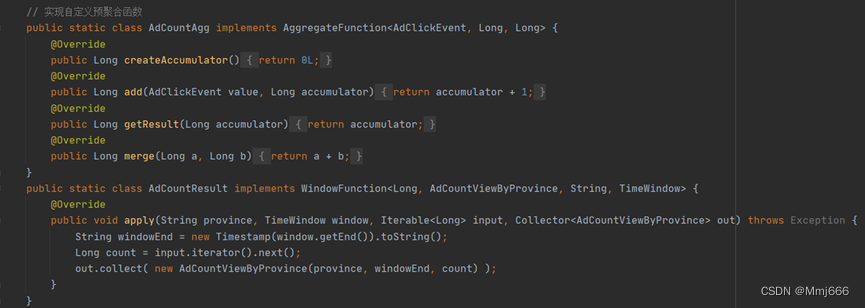


本功能实现的核心代码就在processElement当中,我们判断同一用户对同一广告的点击次数,如果不够上限,就count+1正常输出;如果达到上限,直接过滤掉,并测输出黑名单信息。我们首先获取当前的count值。之后判断是否是第一个数据,如果是的话,注册一个第二天0点的定时器。之后判断是否报警,如果超过了最大的点击次数的话,进行报警,判断是否输出到黑名单过,如果没有的话,输出到测输出流。如果没有超过最大点击次数的话,点击次数加一,更新状态,正常输出当前数据到主流。
8. 恶意登录监控功能实现
8.1 功能需求分析
对于网站而言,用户登录并不是频繁的业务操作。如果一个用户短时间内频繁登录失败,就有可能是出现了程序的恶意攻击,比如密码暴力破解。因此我们考虑,应该对用户的登录失败动作进行统计,具体来说,如果同一用户(可以是不同 IP)在 2 秒之内连续两次登录失败,就认为存在恶意登录的风险,输出相关的信息进行报警提示。
8.2 功能数据集分析
数据源来自于LoginLog.csv文件当中,该文件模拟的是经过ETL清理好的用户登录的日志。该文件内的数据格式如下图所示: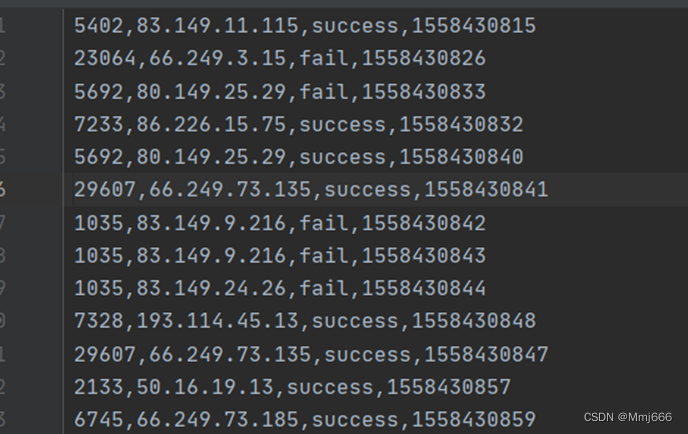
其中,每一行数据的第一个字段为用户的id,第二个字段为用户登录时的ip地址,第三个字段为用户登录的状态(success/fail),第四个字段为时间戳。
8.3 代码设计思路
由于引入了时间,我们可以想到,最简单的方法为进行状态编程。只需要按照用户 ID 分流,然后遇到登录失败的事件时将其保存在 ListState 中,然后设置一个定时器,2 秒后触发。定时器触发时检查状态中的登录失败事件个数,如果大于等于 2,那么就输出报警信息。
8.4 代码具体实现

由于读取的数据当中含有时间戳,因此我们需要设置时间语义为EventTime并设置wartermark和timestamp。由于我们需要进行状态编程,并且需要设置和使用定时器,因此我们使用底层api来解决该问题。
LoginFailDetectWarning代码:


我们在该部分需求当中使用状态编程,针对于用户id进行keyBy(),我们在该函数当中首先定义了最大失败的次数,本次实验当中,最大的失败次数设为2次。之后,我们设置了一个状态列表,用于保存两秒内所有失败的登录事件。另外,我们还设置了一个状态值,用于表示注册的定时器的时间戳,用于判断当前是否有定时器以及触发定时器之后执行完业务在对定时器进行删除操作。
每进来一个登录事件,我们首先要判断是否为失败事件,如果是的话,加入到状态队列列表当中,再进行判断是否有定时器,没有的话注册一个两秒之后的定时器;如果登录成功,则删除定时器,清空状态,重新开始。
当定时器触发之后,我们需要判断状态列表当中失败事件的个数,如果大于最大失败次数的话,则输出报警。最后清空状态。
8.5 效果展示

9. 订单支付失效监控功能实现
9.1 功能需求分析
在电商网站中,订单的支付作为直接与营销收入挂钩的一环,在业务流程中非常重要。对于订单而言,为了正确控制业务流程,也为了增加用户的支付意愿,网站一般会设置一个支付失效时间,超过一段时间不支付的订单就会被取消。
9.2 功能数据集分析
数据集格式如下图所示: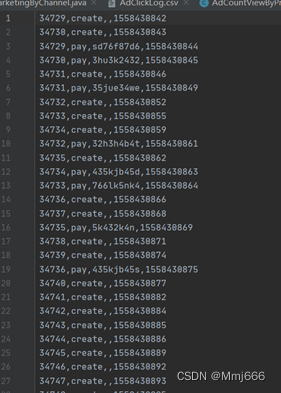
其中,第一个字段表示订单的id,第二个字段表示用户进行的操作(创建和支付订单操作),第三个字段是第三方交易吗,第四个字段是时间戳。
9.3 代码设计思路分析
在电商平台中,最终创造收入和利润的是用户下单购买的环节;更具体一点,是用户真正完成支付动作的时候。用户下单的行为可以表明用户对商品的需求,但在现实中,并不是每次下单都会被用户立刻支付。当拖延一段时间后,用户支付的意愿会降低。所以为了让用户更有紧迫感从而提高支付转化率,同时也为了防范订单支付环节的安全风险,电商网站往往会对订单状态进行监控,设置一个失效时间(比如 15 分钟),如果下单后一段时间仍未支付,订单就会被取消。
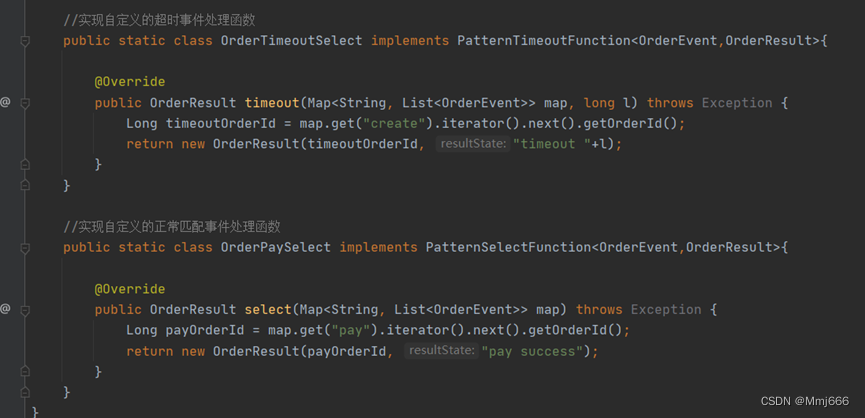
我们还是利用 CEP 库来实现这个功能。我们先将事件流按照订单号 orderId分流,然后定义这样的一个事件模式:在 15 分钟内,事件“create”与“pay”非严格紧邻,之后便可以实现该功能。
9.4 代码具体实现

9.5 效果展示
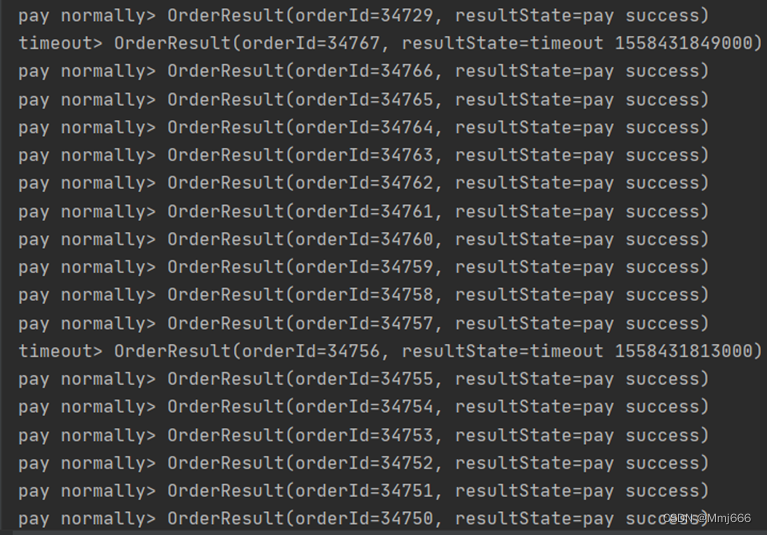
我们可以看到,该程序可以成功将完成订单支付的消息输出,并且也可以将订单超时的信息输出。
10.安装superset并将上述模块数据与superset进行对接,制作可视化展示页面
在本次的项目可视化部分,我选择使用的工具是apache-superset。该软件需要安装在linux系统当中并且python的版本需要为3.7。
当我们安装好superset之后,我们需要下载和mysql数据库连接的驱动,之后便可以和mysql数据库进行连接,拿到需要的数据,之后再进行图表的设计,最终可完成图形界面可视化的任务。
我们首先启动superset:
之后输入端口号进入登录界面:
具体的制表过程不详细介绍,直接看最终的展示效果:
至此,本次实时项目完工。
边栏推荐
- 【函数的效率】
- 1.东软跨境电商数仓需求规格说明文档
- The first smart contract program faucet sol
- 11.数据仓库搭建之DWS层搭建
- Shell script configures root to login to other hosts without secret
- 判断素数
- [first launch in the whole network] one month later, we switched from MySQL dual master to master-slave
- Constants and constant pointers
- 2.6.2 memory leakage
- 2020-10-22
猜你喜欢

Data visualization

C语言&位域

4.东软跨境电商数仓项目--数据采集通道搭建之用户行为数据采集通道搭建(2022.6.1-2022.6.4)

柠檬班软件测试培训可靠吗 这个从培训班逆袭成功的案例告诉你

Implementation of synchronization interface of 6 libcurl based on libco

Nacos configuration management

C语言文件的操作

UML (use case diagram, class diagram, object diagram, package diagram)

Talk about 20 negative teaching materials for writing code

mysql的锁
随机推荐
Syntax differences between PgSQL and Oracle (SQL migration records)
函数与参数
User mode protocol stack - UDP implementation based on netmap
GoFrame 错误处理的常用方法&错误码的使用
mysql - 索引
3.东软跨境电商数仓项目架构设计
Network command: network card information, netstat, ARP
Talk about 20 negative teaching materials for writing code
MySQL学习笔记(5)——JOIN联表查询,自连接查询,分页和排序,子查询与嵌套查询
Some applications of special pointers
Router loopback port experiment
Wechat applet learning notes
MySQL installation and configuration tutorial (super detailed)
一次全面的性能优化,从5秒优化到1秒
Rk356x u-boot Institute (command section) 3.4 usage of MEM memory related commands
Parent components plus scoped sometimes affect child components
redis 源码分析 动态字符串实现(sds)
C语言文件的操作
Data visualization
Three methods for cesium to obtain the longitude and latitude at the mouse click