当前位置:网站首页>Summary of common activation functions for deep learning
Summary of common activation functions for deep learning
2022-07-26 09:03:00 【Weiyaner】
1 Why do we need activation functions
First of all, the distribution of data is nonlinear , The calculation of general neural network is linear , Introduce activation function , Is to introduce nonlinearity into neural networks , Strengthen the learning ability of the network . So the biggest feature of the activation function is nonlinearity .
Different activation functions , According to its characteristics , Applications are also different .
Sigmoid and tanh The feature of is to limit the output to (0,1) and (-1,1) Between , explain Sigmoid and tanh Suitable for processing probability value , for example LSTM Various doors in ;
and ReLU No way. , because ReLU No maximum limit , There may be large values . Again , according to ReLU Characteristics of ,Relu Suitable for deep network training , and Sigmoid and tanh No way. , Because they disappear in gradients .
2 Common activation functions
1 Sigmoid
sigmoid The function is also called Logistic function , because Sigmoid The function can be derived from Logistic Return to (LR) Infer from , It's also LR Activation function specified by the model .
sigmod The value range of the function is (0, 1) Between , The output of the network can be mapped in this range , Easy to analyze .
| Activation function | expression | Leading form | Value range | Images | apply |
|---|---|---|---|---|---|
| Sigmoid | f = 1 1 + e x f = \frac{1}{1+e^x} f=1+ex1 | f ′ = f ( 1 − f ) f'=f(1-f) f′=f(1−f) | (0,1) |  | Calculate the probability value |
Analysis of advantages and disadvantages :
- advantage :
Easy to find , The data conforms to Poisson distribution - shortcoming :
- The activation function is computationally expensive ( Both forward propagation and back propagation contain power operation and division );
- When calculating the error gradient by back propagation , Derivation involves division ;
- Sigmoid The derivative range is [0, 0.25], Due to the of neural network back propagation “ The chain reaction ”, It's easy to see the gradient disappear .
- Sigmoid The output of is not 0 mean value ( namely zero-centered); This will cause the neurons of the latter layer to get the non output of the previous layer 0 Mean signal as input , With the deepening of the network , Will change the original distribution of the data .|
2 Tanh
tanh Is a hyperbolic tangent function , Its English reading is Hyperbolic Tangent.tanh and sigmoid be similar , All belong to saturation activation function , The difference is that the output value range consists of (0,1) Change into (-1,1), You can put tanh The function is seen as sigmoid The result of translation and stretching down .
| Activation function | expression | Leading form | Value range | Images | apply |
|---|---|---|---|---|---|
| tanh | f = e x − e − x e x + e − x f = \frac{e^x-e^{-x}}{e^x+e^{-x}} f=ex+e−xex−e−x | f ′ = 2 1 + e − 2 x − 1 f'=\frac{2}{1+e^{-2x}}-1 f′=1+e−2x2−1 | (-1,1) |  |
Tanh Characteristics
- advantage
- tanh When the output range of (-1, 1), It's solved Sigmoid Function is not zero-centered Output problems ;
- shortcoming
- The problem of power operation still exists ;
- tanh The derivative range is (0, 1) Between , comparison sigmoid Of (0, 0.25), The gradient disappears and is relieved , But there is still .
3 Relu And its variants (2012 AlexNet)
Due to the gradient disappearance problem of the above activation function , therefore 2012 Rectification linear unit was proposed in (Relu).
| Activation function | expression | Leading form | Value range | Images | apply |
|---|---|---|---|---|---|
| Relu | f = m a x ( 0 , x ) f =max(0,x) f=max(0,x) | f ′ = 1 , 0 f'=1, 0 f′=1,0 | [0,1) | 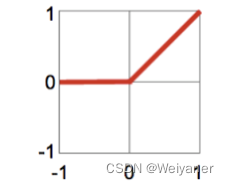 | Avoiding the disappearance of gradients , Suitable for deep network |
| P R e l u ( a i Variable ) / / L e a k y R e l u ( a i = 0.01 ) PRelu(a_i Variable )//LeakyRelu(a_i=0.01) PRelu(ai Variable )//LeakyRelu(ai=0.01) | f ( x ) = { a i x , x < 0 x , x > = 0 f(x)=\left\{\begin{aligned}a_ix, x<0 \\x,x>=0\end{aligned}\right. f(x)={ aix,x<0x,x>=0 | f ′ ( x ) = { a i , x < 0 1 , x > = 0 f'(x)=\left\{\begin{aligned}a_i, x<0 \\1,x>=0\end{aligned}\right. f′(x)={ ai,x<01,x>=0 | (-1,1) | 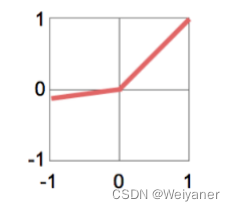 | improve Relu Of 0 gradient , Is a small negative value , Prevent neuron death |
| RRelu | y = { x , x ≥ 0 a ( e x − 1 ) , x < 0 y=\left\{\begin{array}{lc}x, & x \geq 0 \\ a\left(e^{x}-1\right), & x<0\end{array}\right. y={ x,a(ex−1),x≥0x<0 | (-1,1) |  | In the negative part ai It's from a uniform distribution U(I,u) A random number from |
summary :
Leaky ReLU In is constant , General Settings 0.01. This function is usually better than Relu The activation function works better , But the effect is not very stable , So in practice Leaky ReLu Not much is used .
PRelu( Parameterized modified linear element ) As a learnable parameter , It will be updated during training .
RReLU( Random correction of linear elements ) It's also Leaky ReLU A variation of . stay RReLU in , The slope of negative value is random in training , In later tests it became fixed .RReLU The highlight is , In the training session ,aji It's from a uniform distribution U(I,u) A random number from .
边栏推荐
- Cve-2021-26295 Apache OFBiz deserialization Remote Code Execution Vulnerability recurrence
- [leetcode database 1050] actors and directors who have cooperated at least three times (simple question)
- Database operation skills 7
- [search topics] flood coverage of search questions after reading the inevitable meeting
- The largest number of statistical absolute values --- assembly language
- Database operation skills 6
- Media at home and abroad publicize that we should strictly grasp the content
- node的js文件引入
- at、crontab
- Clean the label folder
猜你喜欢

pycharm 打开多个项目的两种小技巧
JS file import of node

Babbitt | metauniverse daily must read: does the future of metauniverse belong to large technology companies or to the decentralized Web3 world

Okaleido launched the fusion mining mode, which is the only way for Oka to verify the current output

2022茶艺师(中级)特种作业证考试题库模拟考试平台操作

Uploading pictures on Alibaba cloud OSS

NFT与数字藏品到底有何区别?

pl/sql之动态sql与异常

Form form

Horizontal comparison of the data of the top ten blue chip NFTs in the past half year
随机推荐
基于序的评价指标 (特别针对推荐系统和多标签学习)
【final关键字的使用】
(2006,Mysql Server has gone away)问题处理
Day 6 summary & database operation
Media at home and abroad publicize that we should strictly grasp the content
TypeScript版加密工具PasswordEncoder
网络安全漫山遍野的高大上名词之后的攻防策略本质
机器学习中的概率模型
Which of count (*), count (primary key ID), count (field) and count (1) in MySQL is more efficient? "Suggested collection"
Web概述和B/S架构
Pop up window in Win 11 opens with a new tab ---firefox
Recurrence of SQL injection vulnerability in the foreground of a 60 terminal security management system
Babbitt | metauniverse daily must read: does the future of metauniverse belong to large technology companies or to the decentralized Web3 world
How to quickly learn a programming language
220. Presence of repeating element III
(1) CTS tradefed test framework environment construction
Database operation topic 2
[recommended collection] MySQL 30000 word essence summary index (II) [easy to understand]
Cat安装和使用
数据库操作 题目一