当前位置:网站首页>Cat安装和使用
Cat安装和使用
2022-07-26 08:55:00 【还是转转】
在前面的博客中介绍过apm系统选型和elastic APM,本文将继续介绍cat。
CAT(Central Application Tracking)是原大众点评基于eBay的CAL改进而来的分布式服务链路监控平台。CAT自2004年开源以来,在携程、陆金所、平安银行、拼多多、OPPO、猎聘网、找钢网等100多家公司、企业的生产环境中落地应用。
以2016年的一组数据为例:
美团点评,2016年,3000+应用服务,7000+服务器,100+TB/天,单机峰值QPS 16w
携程,2016年,4500+应用服务,10000+服务器,140TB/天,单机峰值QPS 10w。
目前,CAT(作为服务端项目基础组件,提供了 Java, C/C++, Node.js, Python, Go 等多语言客户端,已经在美团点评的基础架构中间件框架(MVC框架,RPC框架,数据库框架,缓存框架等,消息队列,配置系统等)深度集成,为美团点评各业务线提供系统丰富的性能指标、健康状况、实时告警等。
在前面的blog中介绍过分布式跟踪系统和Elastic APM的安装使用,本文将继续介绍Cat的安装使用。
服务端部署
Cat的部署文档在github上写的比较详细了,传送门:https://github.com/dianping/cat/wiki/readme_server。
下面将按照博主实际部署过程来说明。
环境:tomcat8,mysql,jdk8,cat源码(https://github.com/dianping/cat)。
(1)创建cat初始目录
Cat初始目录不可更改(官方部署文档说可以定义CAT_HOME为自定义目录,但在faq文档中又说不支持修改该目录,如果想修改,需要自行阅读源码解决),linux环境下创建目录并修改权限:
mkdir /data
chmod -R 777 /data
mkdir -p /data/appdatas/cat
如果是windows环境,例如cat服务运行在e盘的tomcat中,则需要对e:/data/appdatas/cat和e:/data/applogs/cat有读写权限。
(2)部署tomcat
在tomcat的bin目录下新建setenv.sh脚本,添加环境变量:
export CAT_HOME=/data/appdatas/cat/
CATALINA_OPTS="$CATALINA_OPTS -server -DCAT_HOME=$CAT_HOME -Djava.awt.headless=true -Xms25G -Xmx25G -XX:PermSize=256m -XX:MaxPermSize=256m -XX:NewSize=10144m -XX:MaxNewSize=10144m -XX:SurvivorRatio=10 -XX:+UseParNewGC -XX:ParallelGCThreads=4 -XX:MaxTenuringThreshold=13 -XX:+UseConcMarkSweepGC -XX:+DisableExplicitGC -XX:+UseCMSInitiatingOccupancyOnly -XX:+ScavengeBeforeFullGC -XX:+UseCMSCompactAtFullCollection -XX:+CMSParallelRemarkEnabled -XX:CMSFullGCsBeforeCompaction=9 -XX:CMSInitiatingOccupancyFraction=60 -XX:+CMSClassUnloadingEnabled -XX:SoftRefLRUPolicyMSPerMB=0 -XX:-ReduceInitialCardMarks -XX:+CMSPermGenSweepingEnabled -XX:CMSInitiatingPermOccupancyFraction=70 -XX:+ExplicitGCInvokesConcurrent -Djava.nio.channels.spi.SelectorProvider=sun.nio.ch.EPollSelectorProvider -Djava.util.logging.manager=org.apache.juli.ClassLoaderLogManager -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCApplicationConcurrentTime -XX:+PrintHeapAtGC -Xloggc:/data/applogs/heap_trace.txt -XX:-HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/data/applogs/HeapDumpOnOutOfMemoryError -Djava.util.Arrays.useLegacyMergeSort=true"
Tomcat启动的时候会自动加载该脚本的环境变量,请注意:这里的堆大小和新生代大小请自行调整,开发环境下堆大小为2G即可。
修改tomcat的conf目录下的server.xml,防止中文乱码:
<Connector port="8080" protocol="HTTP/1.1"
URIEncoding="utf-8" connectionTimeout="20000"
redirectPort="8443" /> <!-- 增加 URIEncoding="utf-8" -->
(3)配置客户端指向的cat server地址
在/data/appdatas/cat目录下创建client.xml文件,假设cat服务器地址为10.1.1.1,10.1.1.2,10.1.1.3,则配置为:
<?xml version="1.0" encoding="utf-8"?>
<config mode="client">
<servers>
<server ip="10.1.1.1" port="2280" http-port="8080"/>
<server ip="10.1.1.2" port="2280" http-port="8080"/>
<server ip="10.1.1.3" port="2280" http-port="8080"/>
</servers>
</config>
(4)安装数据库并配置
创建数据库cat(库名不能改),从cat源码的script目录下获取数据库脚本文件:CatApplication.sql,执行脚本文件生成cat需要的表。
配置/data/appdatas/cat/datasources.xml文件:
<?xml version="1.0" encoding="utf-8"?>
<data-sources>
<data-source id="cat">
<maximum-pool-size>3</maximum-pool-size>
<connection-timeout>1s</connection-timeout>
<idle-timeout>10m</idle-timeout>
<statement-cache-size>1000</statement-cache-size>
<properties>
<driver>com.mysql.jdbc.Driver</driver>
<url><![CDATA[jdbc:mysql://127.0.0.1:3306/cat]]></url> <!-- 请替换为真实数据库URL及Port -->
<user>root</user> <!-- 请替换为真实数据库用户名 -->
<password>root</password> <!-- 请替换为真实数据库密码 -->
<connectionProperties><![CDATA[useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&socketTimeout=120000]]></connectionProperties>
</properties>
</data-source>
</data-sources>
如果是集群模式,则每台cat服务器上都需要部署此文件。
(5)war打包和部署
有两种方式,一种是通过源码自行构建,执行mvn clean install -DskipTests,在cat_home下生成war报,改名为cat.war。
另一种是下载官方打包(对应jdk8):http://unidal.org/nexus/service/local/repositories/releases/content/com/dianping/cat/cat-home/3.0.0/cat-home-3.0.0.war
也需要重命名为cat.war。
将war包放到tomcat的webapps目录下,启动tomcat。
如果是本地开发环境,在IDE中可以使用tomcat插件启动cat-home模块,application context设置为/cat。
(6)系统配置
访问http://localhost:8080/cat/s/config?op=projects,进入全局系统配置菜单。
服务端配置
如果是集群环境,则配置sample如下:
<?xml version="1.0" encoding="utf-8"?>
<server-config>
<server id="default">
<properties>
<property name="local-mode" value="false"/>
<property name="job-machine" value="false"/>
<property name="send-machine" value="false"/>
<property name="alarm-machine" value="false"/>
<property name="hdfs-enabled" value="false"/>
<property name="remote-servers" value="10.1.1.1:8080,10.1.1.2:8080,10.1.1.3:8080"/>
</properties>
<storage local-base-dir="/data/appdatas/cat/bucket/" max-hdfs-storage-time="15" local-report-storage-time="7" local-logivew-storage-time="7">
<hdfs id="logview" max-size="128M" server-uri="hdfs://10.1.77.86/" base-dir="user/cat/logview"/>
<hdfs id="dump" max-size="128M" server-uri="hdfs://10.1.77.86/" base-dir="user/cat/dump"/>
<hdfs id="remote" max-size="128M" server-uri="hdfs://10.1.77.86/" base-dir="user/cat/remote"/>
</storage>
<consumer>
<long-config default-url-threshold="1000" default-sql-threshold="100" default-service-threshold="50">
<domain name="cat" url-threshold="500" sql-threshold="500"/>
<domain name="OpenPlatformWeb" url-threshold="100" sql-threshold="500"/>
</long-config>
</consumer>
</server>
<server id="10.1.1.1">
<properties>
<property name="job-machine" value="true"/>
<property name="alarm-machine" value="true"/>
<property name="send-machine" value="true"/>
</properties>
</server>
</server-config>
其中, id="default"是默认的配置信息,server id=“10.1.1.1” 如下的配置是表示10.1.1.1这台服务器的节点配置覆盖default的配置信息,比如下面的job-machine,alarm-machine,send-machine为true。
Cat节点职责
- 控制台:提供给业务人员进行数据查看【默认所有的cat节点都可以作为控制台,不可配置】
- 消费机:实时接收业务数据,实时处理,提供实时分析报表【默认所有的cat节点都可以作为消费机,不可配置】
- 告警端: 启动告警线程,进行规则匹配,发送告警(目前仅支持单点部署)【可以配置】
- 任务机:做一些离线的任务,合并天、周、月等报表 【可以配置】
如果是本地单机环境,配置应该是这样的:
<?xml version="1.0" encoding="utf-8"?>
<server-config>
<server id="default">
<properties>
<property name="local-mode" value="false"/>
<property name="job-machine" value="false"/>
<property name="send-machine" value="false"/>
<property name="alarm-machine" value="false"/>
<property name="hdfs-enabled" value="false"/>
<property name="remote-servers" value="127.0.0.1:8080"/>
</properties>
<storage local-base-dir="/data/appdatas/cat/bucket/" max-hdfs-storage-time="15" local-report-storage-time="2" local-logivew-storage-time="1" har-mode="true" upload-thread="5">
<hdfs id="dump" max-size="128M" server-uri="hdfs://127.0.0.1/" base-dir="/user/cat/dump"/>
<harfs id="dump" max-size="128M" server-uri="har://127.0.0.1/" base-dir="/user/cat/dump"/>
<properties>
<property name="hadoop.security.authentication" value="false"/>
<property name="dfs.namenode.kerberos.principal" value="hadoop/[email protected]"/>
<property name="dfs.cat.kerberos.principal" value="[email protected]"/>
<property name="dfs.cat.keytab.file" value="/data/appdatas/cat/cat.keytab"/>
<property name="java.security.krb5.realm" value="value1"/>
<property name="java.security.krb5.kdc" value="value2"/>
</properties>
</storage>
<consumer>
<long-config default-url-threshold="1000" default-sql-threshold="100" default-service-threshold="50">
<domain name="cat" url-threshold="500" sql-threshold="500"/>
<domain name="OpenPlatformWeb" url-threshold="100" sql-threshold="500"/>
</long-config>
</consumer>
</server>
<server id="127.0.0.1">
<properties>
<property name="job-machine" value="true"/>
<property name="send-machine" value="true"/>
<property name="alarm-machine" value="true"/>
</properties>
</server>
</server-config>
客户端路由
集群环境下客户端路由配置如下:
<?xml version="1.0" encoding="utf-8"?>
<router-config backup-server="10.1.1.1" backup-server-port="2280">
<default-server id="10.1.1.1" weight="1.0" port="2280" enable="false"/>
<default-server id="10.1.1.2" weight="1.0" port="2280" enable="true"/>
<default-server id="10.1.1.3" weight="1.0" port="2280" enable="true"/>
<network-policy id="default" title="default" block="false" server-group="default_group">
</network-policy>
<server-group id="default_group" title="default-group">
<group-server id="10.1.1.2"/>
<group-server id="10.1.1.3"/>
</server-group>
<domain id="cat">
<group id="default">
<server id="10.1.1.2" port="2280" weight="1.0"/>
<server id="10.1.1.3" port="2280" weight="1.0"/>
</group>
</domain>
</router-config>
本地单机环境下配置如下:
<?xml version="1.0" encoding="utf-8"?>
<router-config backup-server="127.0.0.1" backup-server-port="2280">
<default-server id="127.0.0.1" weight="1.0" port="2280" enable="true"/>
<network-policy id="default" title="默认" block="false" server-group="default_group">
</network-policy>
<server-group id="default_group" title="default-group">
<group-server id="127.0.0.1"/>
</server-group>
<domain id="cat">
<group id="default">
<server id="127.0.0.1" port="2280" weight="1.0"/>
</group>
</domain>
</router-config>
服务端和客户端路由配置只需配置一次即可,会保存在数据库中,启动其他节点的时候会自动从数据库读取。
Cat使用
部署好cat服务端后,只需要在业务系统中引入客户端的库,在代码中埋点上报数据。
这里以python代码为例:引入cat-sdk(3.1.2)包,测试代码:
import cat
import time
cat.init('appkey', sampling=True, debug=True)
while True:
with cat.Transaction("foo", "bar") as t:
try:
t.add_data("a=1")
cat.log_event("hook", "before")
# do something
except Exception as e:
cat.log_exception(e)
finally:
cat.metric("api-count").count()
cat.metric("api-duration").duration(100)
cat.log_event("hook", "after")
time.sleep(2000)
在cat控制台配置项目名称:

运行代码之后,通过应用名称appkey查看上报的数据:

假设通过/test/hello这个url来访问一个接口:
class HelloWorldHandler(tornado.web.RequestHandler):
def get(self):
with cat.Transaction(self.request.path, "test") as t:
# 调用其他系统
cat.log_event("call service1", "before")
self.func1()
cat.log_event("call service1", "after")
time.sleep(3)
cat.log_event("call service2", "before")
self.func2()
cat.log_event("call service2", "after")
cat.log_event("get data from db", "before")
self.func3()
cat.log_event("get data from db", "after")
self.write("Hello, world")
def func1(self):
time.sleep(1)
def func2(self):
time.sleep(2)
def func3(self):
time.sleep(1)
在该接口处理过程中,调用了其他服务,访问了本地数据库。通过cat埋点可以将调用事件上报。
Event如下:
Transaction如下:
点击Transaction或者event的logview,可以看到调用链:
python里的cat也可以通过装饰器的方式来使用,但是此种情况下无法获取事务对象。
上面的例子中Transaction页面看起来很正常,显示了每个api接口的调用次数和请求耗时。
但实际上这样是不对的,因为Transaction的两个参数中,第一个参数应该是类型,第二个参数是类型对应的值。
在Problem页面会根据类型和设置的参数筛选出有问题的埋点数据:
- Long-url,表示Transaction打点URL类型的慢请求
- Long-sql,表示Transaction打点SQL类型的慢请求
- Long-service,表示Transaction打点Service或者PigeonService类型的慢请求
- Long-cache,表示Transaction打点Cache.开头的慢请求
- Long-call,表示Transaction打点Call或者PigeonCall类型的慢请求
如果不按照类型打点,就无法在Problem页面查看有问题的请求。因此将事务的打点改成:
with cat.Transaction("URL", self.request.path) as t:
problem页面如下:

下文将继续介绍Zipkin的安装使用。
参考资料
[1]. https://github.com/dianping/cat/wiki/readme_server
[2].https://github.com/dianping/cat/wiki/cat_faq
[3].https://tech.meituan.com/2018/11/01/cat-in-depth-java-application-monitoring.html
边栏推荐
- Database operation skills 6
- Uploading pictures on Alibaba cloud OSS
- ext3文件系统的一个目录下,无法创建子文件夹,但可以创建文件
- Form form
- NFT与数字藏品到底有何区别?
- NPM add source and switch source
- Flask project learning (I) -- sayhello
- sklearn 机器学习基础(线性回归、欠拟合、过拟合、岭回归、模型加载保存)
- Cve-2021-21975 VMware SSRF vulnerability recurrence
- 基于序的评价指标 (特别针对推荐系统和多标签学习)
猜你喜欢
The idea shortcut key ALT realizes the whole column operation
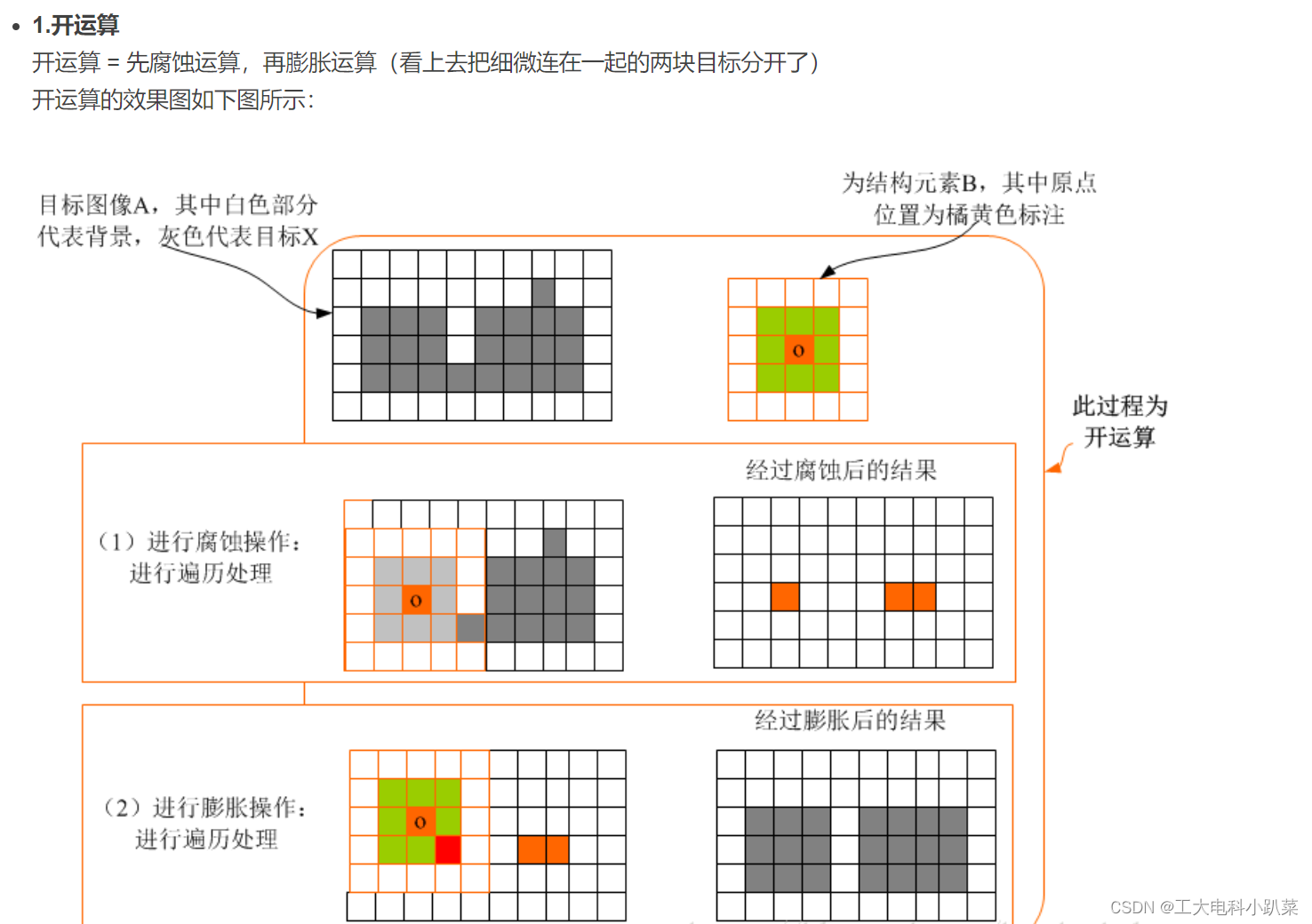
合工大苍穹战队视觉组培训Day6——传统视觉,图像处理
Probability model in machine learning

巴比特 | 元宇宙每日必读:元宇宙的未来是属于大型科技公司,还是属于分散的Web3世界?...

Matlab 绘制阴影误差图

One click deployment of lamp and LNMP scripts is worth having

数据库操作 题目一
Day06 homework -- skill question 1
数据库操作 技能6

Node-v download and application, ES6 module import and export
随机推荐
Babbitt | metauniverse daily must read: does the future of metauniverse belong to large technology companies or to the decentralized Web3 world
Center an element horizontally and vertically
【final关键字的使用】
Replication of SQL injection vulnerability in the foreground of Pan micro e-cology8
day06 作业--增删改查
day06 作业--技能题2
十大蓝筹NFT近半年数据横向对比
2000年的教训。web3是否=第三次工业革命?
day06 作业--技能题6
day06 作业--技能题1
What are the differences in the performance of different usages such as count (*), count (primary key ID), count (field) and count (1)? That's more efficient
SSH,NFS,FTP
[leetcode database 1050] actors and directors who have cooperated at least three times (simple question)
PAT 甲级 A1076 Forwards on Weibo
PAT 甲级 A1034 Head of a Gang
[recommended collection] MySQL 30000 word essence summary - query and transaction (III)
sklearn 机器学习基础(线性回归、欠拟合、过拟合、岭回归、模型加载保存)
基于序的评价指标 (特别针对推荐系统和多标签学习)
Mutual transformation of array structure and tree structure
合工大苍穹战队视觉组培训Day6——传统视觉,图像处理