当前位置:网站首页>基于序的评价指标 (特别针对推荐系统和多标签学习)
基于序的评价指标 (特别针对推荐系统和多标签学习)
2022-07-26 08:54:00 【闵帆】
摘要: 一些学习器为推荐系统或多标签学习输出的是实型预测. 如, 预测第 i i i 个用户对第 j j j 个项目的评分为 4.2 4.2 4.2, 或者预测第 i i i 的样本的第 j j j 个标签为正标签的概率为 0.46 0.46 0.46. 应如何评价预测的有效性? 本文描述几种基于序的评价指标 (Ranking-based evaluation measures) 的动机及物理意义.
1. 非基于序的评价指标
本节描述几种非基于序的评价指标, 并指出其缺陷.
1.1 Mean absolute error (MAE)
令实际评分为 r i j r_{ij} rij, 预测评分为 r ^ i j \hat{r}_{ij} r^ij, 评分未知 (需要预测的) 用户-项目集合为 Ω \Omega Ω, 则
M A E = ∑ ( i , j ) ∈ Ω ∣ r i j − r ^ i j ∣ / ∣ Ω ∣ (1) MAE = \sum_{(i, j) \in \Omega} \vert r_{ij} - \hat{r}_{ij}\vert / |\Omega|\tag{1} MAE=(i,j)∈Ω∑∣rij−r^ij∣/∣Ω∣(1)
它表示预测评分与实际评分的绝对差距.
优点: 简单直接.
缺陷: 假设为每个用户固定地推荐 10 10 10 个项目. 容易举出这样的反例: 把用户最喜欢的 10 10 10 个项目排在最前面 (推荐效果完美), 但误差却很大, 如: 真实评分为 5, 但预测评分却只有 3.6–3.9 (其它的项目预测评分均小于 3.6). 甚至可以举出这样的反例: MAE 不差, 但推荐的列表却很不好 (把用户最喜欢, 评分为 5 的项目预测为 4.4 分; 但用户次喜欢, 评分为 4 的项目预测为 4.5 分).
1.2 Root squre mean error (RSME)
与 MAE 同理.
1.3 Accuracy
这里以多标签 (相当于二分类的扩展) 为例进行说明.
令实际标签为 y i j ∈ { 0 , 1 } y_{ij} \in \{0, 1\} yij∈{ 0,1}, 预测标签为 y ^ i j \hat{y}_{ij} y^ij, 测试数据条数为 n n n, 标签个数为 q q q, 则准确率
A c c = n q − ∑ i , j ∣ y i j − y ^ i j ∣ n q Acc = \frac{nq - \sum_{i, j} |y_{ij} - \hat{y}_{ij}|}{nq} Acc=nqnq−∑i,j∣yij−y^ij∣
优点: 简单直接, 计算预测正确的比例.
缺点 1: 由于初始预测值为初数值 (如前例的 0.42), 需要一个阈值将其转换为布值 0 / 1 0/1 0/1. 如果简单粗暴地使用阈值 0.5, 效果并不好.
缺点 2: 由于类别不均衡, 负标签 (标签实际取值为 1 1 1) 比正标签 (标签实际取值为 0 0 0) 要多很多. 在一些极限多标签数据集中, 负标签占比在 99% 以上, 这时只需要判断所有标签为负就可以或者很高的 Accuray, 但显然没有任何实际意义.
1.4 F1
F1-score 主要应对 Accuracy 的缺点 2. 参见 误分类代价与类不均衡数据, 以及 F-measure 与代价敏感评价指标.
2. 基于序的评价指标
本节描述几种基于序的评价指标.
2.1 Peak-F1
将所有的样本-标签对按照预测值 (一个纯小数) 逆序排列. 第 k k k 次认为前 k k k 个 样本-标签对为正. 以此画出 F1 曲线, 最终取该曲线中最大值, 称之为 Peak-F1.
优点: 应对 1.3 节中 Accuracy 的缺点 1, 不需要进行阈值的选择 (小孩子才做选择).
缺点: 只记录了高光时刻, 有可能前面排的质量很高, 但后面质量不好. 勉强算一个缺点吧.
2.2 ROC curve 与 AUC
将所有的样本-标签对按照预测值 (一个纯小数) 逆序排列. 从二维坐标 (0, 0) 出发, 第 1 个是正的, 就向上走 1 步, 否则向右走 1 步. 向上走 1 步的距离为 1 / P 1/P 1/P, 向右走 1 步的距离为 1 / N 1/N 1/N, 其中 P P P ( N N N) 为实际正 (负) 标签的总个数. 这样获得的曲线称为 ROC, 参见 Receiver operating characteristic curve.
AUC (Area Under Curve) 就是该曲线下面的面积, 通常为一个纯小数 (AUC = 1 就太过分了).
优点 1: 同 Peak-F1.
特点 1: 从总体上进行度量. 如果关心总体表现, 它是本指标相对于 Peak-F1 的优点. 如果只关心前几个 (推荐系统), 它可能成为缺点.
2.3 nDCG
偷懒了, 参见 https://zhuanlan.zhihu.com/p/371432647.
2.4 [email protected], [email protected], [email protected]
继续偷懒, 参见 http://manikvarma.org/downloads/XC/XMLRepository.html.
边栏推荐
- Database operation skills 6
- day06 作业--技能题6
- Pop up window in Win 11 opens with a new tab ---firefox
- 深度学习常用激活函数总结
- Okaleido上线聚变Mining模式,OKA通证当下产出的唯一方式
- Learn more about the difference between B-tree and b+tree
- Super potential public chain dfinity -- the best time for DFI developers to enter
- keepalived双机热备
- 力扣题DFS
- day06 作业--增删改查
猜你喜欢
ES6 modular import and export) (realize page nesting)

Nuxt - 项目打包部署及上线到服务器流程(SSR 服务端渲染)

数据库操作 题目二

深度学习常用激活函数总结

Okaleido上线聚变Mining模式,OKA通证当下产出的唯一方式

NPM add source and switch source

Study notes of automatic control principle --- stability analysis of control system
正则表达式:判断是否符合USD格式
谷粒学院的全部学习源码
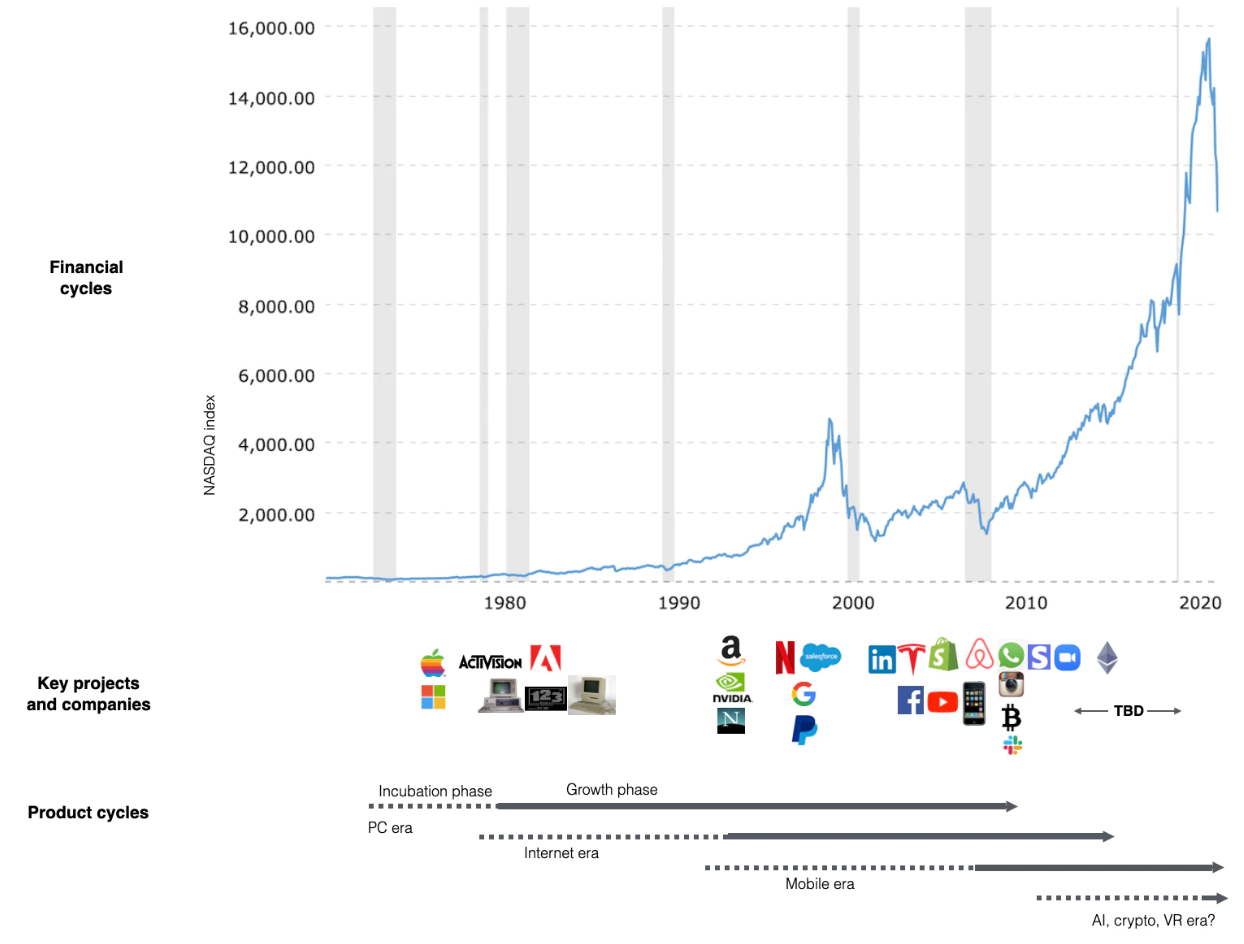
2000年的教训。web3是否=第三次工业革命?
随机推荐
How to quickly learn a programming language
Pytoch learning - from tensor to LR
Arbitrum launched the anytrust chain to meet the diverse needs of ecological projects
Which of count (*), count (primary key ID), count (field) and count (1) in MySQL is more efficient? "Suggested collection"
220. Presence of repeating element III
数据库操作 题目一
[recommended collection] summary of MySQL 30000 word essence - partitions, tables, databases and master-slave replication (V)
pl/sql之集合-2
Store a group of positive and negative numbers respectively, and count the number of 0 -- assembly language implementation
Replication of SQL injection vulnerability in the foreground of Pan micro e-cology8
Database operation topic 2
[encryption weekly] has the encryption market recovered? The cold winter still hasn't thawed out. Take stock of the major events that occurred in the encryption market last week
Day06 homework - skill question 6
机器学习中的概率模型
Kotlin properties and fields
Media at home and abroad publicize that we should strictly grasp the content
十大蓝筹NFT近半年数据横向对比
【数据库 】GBase 8a MPP Cluster V95 安装和卸载
JDBC database connection pool (Druid Technology)
Cve-2021-3156 duplicate of sudo heap overflow privilege raising vulnerability