当前位置:网站首页>Pytoch learning - from tensor to LR
Pytoch learning - from tensor to LR
2022-07-26 08:51:00 【Miracle Fan】
Pytorch Study — from Tensor To LR
1. Generate simple Tensor
x=torch.empty(1)
y=torch.rand(2,3)
x,y
(tensor([0.]),
tensor([[0.0721, 0.6318, 0.4175],
[0.3821, 0.0745, 0.0769]]))
x=torch.ones(2,4,dtype=torch.float16)
print(x)
print(x.dtype)
print(x.size())
tensor([[1., 1., 1., 1.],
[1., 1., 1., 1.]], dtype=torch.float16)
torch.float16
torch.Size([2, 4])
2. Addition, subtraction, multiplication and division of tensors
x+y = torch.add(x,y)
x-y = torch.sub(x,y)
x*y = torch.mul(x,y)
x/y = torch.div(x,y)
y.add_(x) take x Add to y And update the y Value
x=torch.rand(2,2)
y=torch.rand(2,2)
print(x,y)
y.add_(x)# take x add y And cover y Value
print(y)
tensor([[0.7928, 0.1424],
[0.5847, 0.9996]]) tensor([[0.1585, 0.1488],
[0.8360, 0.0950]])
tensor([[0.9513, 0.2912],
[1.4207, 1.0946]])
3. Tensor slices 、 Indexes
x=torch.rand(5,3)
print(x)
print(x[:,:1])# The first parameter represents the line , The second parameter is the column
print(x[1,1].item())# Get the tensor actual value
tensor([[0.4997, 0.6359, 0.7303],
[0.2803, 0.6739, 0.0794],
[0.5455, 0.0975, 0.9395],
[0.0389, 0.0743, 0.8702],
[0.6613, 0.6809, 0.1929]])
tensor([[0.4997],
[0.2803],
[0.5455],
[0.0389],
[0.6613]])
0.673908531665802
4. Data type conversion
4.1 Tensor ⇔ \Leftrightarrow ⇔Numpy
tensor.numpy()
torch.from_numpy()
a=torch.ones(5)
print(a)
b=a.numpy()
print(type(b))
tensor([1., 1., 1., 1., 1.])
<class 'numpy.ndarray'>
a=np.ones(5)
print(a)
b=torch.from_numpy(a)
print(b)
[1. 1. 1. 1. 1.]
tensor([1., 1., 1., 1., 1.], dtype=torch.float64)
4.2 Migrate data to cuda
if torch.cuda.is_available():
device = torch.device("cuda")
x=torch.ones(5,device=device)
y=torch.ones(5)
y=y.to(device)
z=x+y
z=z.to("cpu")
5. Gradient calculation
5.1 autograd
x=torch.randn(3,requires_grad=True)
print(x)
tensor([0.9217, 0.3146, 0.0978], requires_grad=True)
y=x+2
print(y)
z=y*y*2
# z=z.mean()
print(z)
tensor([2.9217, 2.3146, 2.0978], grad_fn=<AddBackward0>)
tensor([17.0728, 10.7144, 8.8019], grad_fn=<MulBackward0>)
z.backward() #dz/dx
print(x.grad)
tensor([3.8956, 3.0861, 2.7971])
v=torch.tensor([0.1,1.0,0.001],dtype=torch.float32)
# If z Not scalar , Need a parameter
z.backward(v) #dz/dx
print(x.grad)
tensor([ 5.0643, 12.3444, 2.8055])
x=torch.tensor(1.0)
y=torch.tensor(2.0)
w= torch.tensor(1.0,requires_grad=True)
# Forward transfer and calculate the mean square error
y_hat=w*x
loss=(y_hat-y)**2
print(loss)
loss.backward()# dl / dw = 2*y_hat*x
print(w.grad)
tensor(1., grad_fn=<PowBackward0>)
tensor(-2.)
5.2 Cancel gradient
#1. x.requires_grad_(False)
#2. y=x.detach()
#3. with torch.no_grad():
# with torch.no_grad():
# y=x+2
# print(y)
y=x.detach()
print(y)
print(x)
tensor([ 0.6006, -1.0621, 0.5496])
tensor([ 0.6006, -1.0621, 0.5496], requires_grad=True)
5.3 Gradient accumulation
weights = torch.ones(4,requires_grad=True)
for epoch in range(3):
model_output=(weights*5).sum()
model_output.backward()
print(weights.grad)
# Gradient accumulation , In the next iteration or optimization , You need to clear the gradient
tensor([5., 5., 5., 5.])
tensor([10., 10., 10., 10.])
tensor([15., 15., 15., 15.])
weights.grad.zero_()
tensor([5., 5., 5., 5.])
tensor([5., 5., 5., 5.])
tensor([5., 5., 5., 5.])
6. Linear regression
6.1 Use numpy Realization
X = np.array([1, 2, 3, 4], dtype=np.float32)
Y = np.array([2, 4, 6, 8], dtype=np.float32)
w = 0.0
# Build a model
def forward(x):
return w * x
# The error function is set to MSE
def loss(y, y_pred):
return ((y_pred - y)**2).mean()
# MSE = 1/N * (w*x - y)**2
# dl/dw = 1/N * 2x(w*x - y)
def gradient(x, y, y_pred):
return np.dot(2*x, y_pred - y).mean()
print(f' Pre training predictions f(5) = {
forward(5):.3f}')
# Training
lr = 0.01
n_iters = 20
for epoch in range(n_iters):
# predict = forward pass
y_pred = forward(X)
l = loss(Y, y_pred)
dw = gradient(X, Y, y_pred)
w -= lr * dw
if epoch % 2 == 0:
print(f'epoch {
epoch+1}: w = {
w:.3f}, loss = {
l:.8f}')
print(f' Predicted value after training f(5) = {
forward(5):.3f}')
Prediction before training: f(5) = 0.000
epoch 1: w = 1.200, loss = 30.00000000
epoch 3: w = 1.872, loss = 0.76800019
epoch 5: w = 1.980, loss = 0.01966083
epoch 7: w = 1.997, loss = 0.00050331
epoch 9: w = 1.999, loss = 0.00001288
epoch 11: w = 2.000, loss = 0.00000033
epoch 13: w = 2.000, loss = 0.00000001
epoch 15: w = 2.000, loss = 0.00000000
epoch 17: w = 2.000, loss = 0.00000000
epoch 19: w = 2.000, loss = 0.00000000
Prediction after training: f(5) = 10.000
6.2 Use Pytorch Realization
X = torch.tensor([1, 2, 3, 4], dtype=torch.float32)
Y = torch.tensor([2, 4, 6, 8], dtype=torch.float32)
w = torch.tensor(0.0, dtype=torch.float32, requires_grad=True)
# model output
def forward(x):
return w * x
# loss = MSE
def loss(y, y_pred):
return ((y_pred - y)**2).mean()
print(f'Prediction before training: f(5) = {
forward(5).item():.3f}')
# Training
learning_rate = 0.01
n_iters = 100
for epoch in range(n_iters):
# predict = forward pass
y_pred = forward(X)
# loss
l = loss(Y, y_pred)
# calculate gradients = backward pass
l.backward()
# update weights
#w.data = w.data - learning_rate * w.grad
with torch.no_grad():
w -= learning_rate * w.grad
# Clear the gradient after updating the parameters
w.grad.zero_()
if epoch % 10 == 0:
print(f'epoch {
epoch+1}: w = {
w.item():.3f}, loss = {
l.item():.8f}')
print(f'Prediction after training: f(5) = {
forward(5).item():.3f}')
Prediction before training: f(5) = 0.000
epoch 1: w = 0.300, loss = 30.00000000
epoch 11: w = 1.665, loss = 1.16278565
epoch 21: w = 1.934, loss = 0.04506890
epoch 31: w = 1.987, loss = 0.00174685
epoch 41: w = 1.997, loss = 0.00006770
epoch 51: w = 1.999, loss = 0.00000262
epoch 61: w = 2.000, loss = 0.00000010
epoch 71: w = 2.000, loss = 0.00000000
epoch 81: w = 2.000, loss = 0.00000000
epoch 91: w = 2.000, loss = 0.00000000
Prediction after training: f(5) = 10.000
边栏推荐
- Mysql8 one master one slave +mycat2 read write separation
- Kotlin属性与字段
- What are the differences in the performance of different usages such as count (*), count (primary key ID), count (field) and count (1)? That's more efficient
- MySQL 8.0 OCP 1z0-908 certification examination question bank 1
- [database] gbase 8A MPP cluster v95 installation and uninstall
- day06 作业---技能题7
- Deploy prometheus+grafana monitoring platform
- Super potential public chain dfinity -- the best time for DFI developers to enter
- [abstract base class inheritance, DOM, event - learning summary]
- Xshell batch send command to multiple sessions
猜你喜欢

Mysql8 one master one slave +mycat2 read write separation
基于C#实现的文件管理文件系统
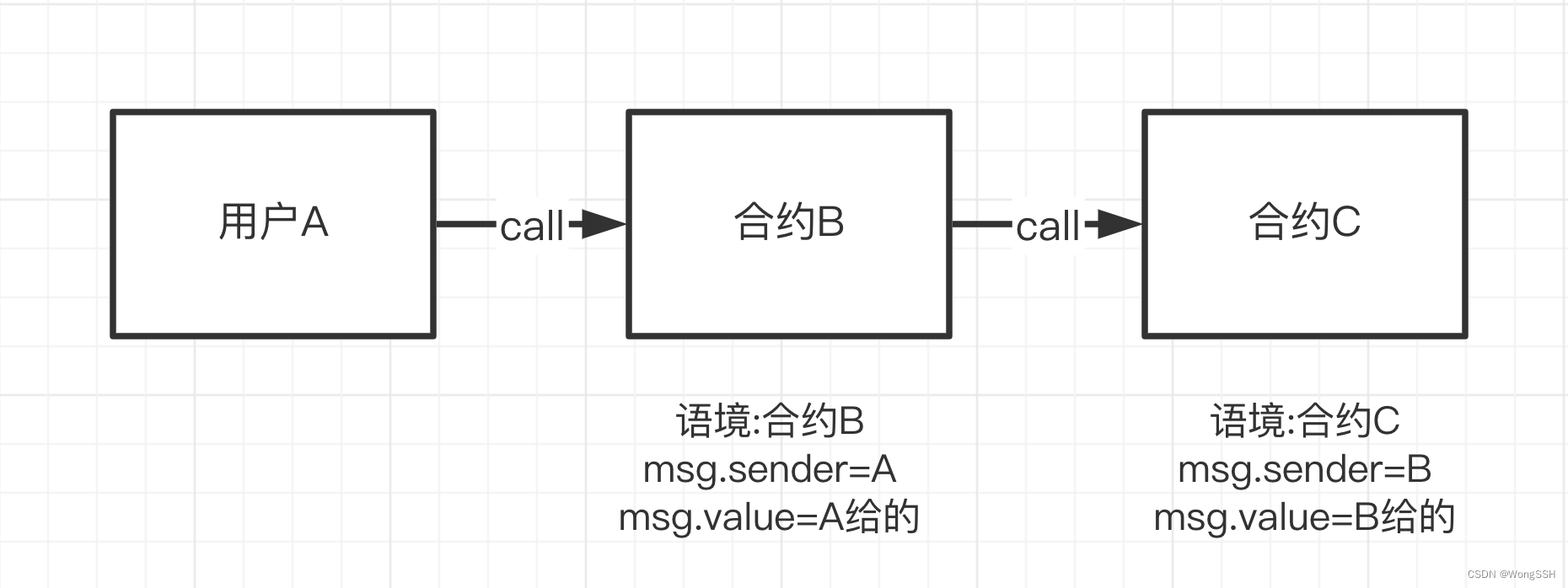
Foundry教程:使用多种方式编写可升级的智能合约(上)

Arbitrum launched the anytrust chain to meet the diverse needs of ecological projects

【搜索专题】看完必会的搜索问题之洪水覆盖
有限元学习知识点备案

C Entry series (31) -- operator overloading
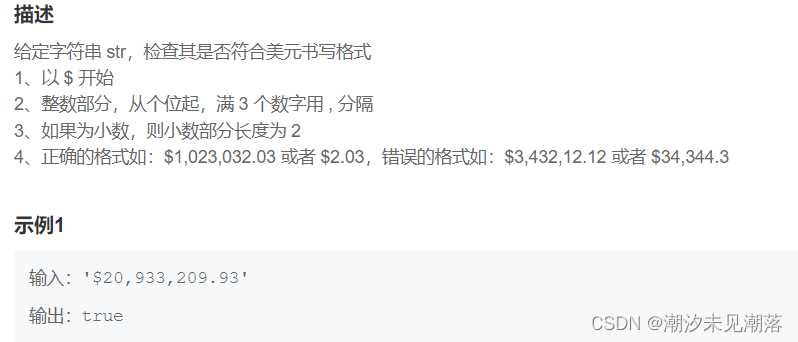
正则表达式:判断是否符合USD格式

IC's first global hacking bonus is up to US $6million, helping developers venture into web 3!

03 exception handling, state keeping, request hook -- 04 large project structure and blueprint
随机推荐
Oracle 19C OCP 1z0-082 certification examination question bank (42-50)
Kotlin属性与字段
The data read by Flink Oracle CDC is always null. Do you know
Mysql database connection / query index and other common syntax
【FreeSwitch开发实践】使用SIP客户端Yate连接FreeSwitch进行VoIP通话
Arbitrum Nova release! Create a low-cost and high-speed dedicated chain in the game social field
Set of pl/sql
六、品达通用权限系统__pd-tools-log
1、 Redis data structure
One click deployment of lamp and LNMP scripts is worth having
Media at home and abroad publicize that we should strictly grasp the content
Cadence(十)走线技巧与注意事项
Oracle 19C OCP 1z0-082 certification examination question bank (19-23)
Kotlin properties and fields
After MySQL 8 OCP (1z0-908), hand in your homework
C#入门系列(三十一) -- 运算符重载
MySQL 8.0 OCP 1z0-908 certification examination question bank 1
Foundry教程:使用多种方式编写可升级的智能合约(上)
idea快捷键 alt实现整列操作
node-v下载与应用、ES6模块导入与导出