当前位置:网站首页>Sgm: sequence generation model for multi label classification
Sgm: sequence generation model for multi label classification
2022-07-19 05:48:00 【Stewed seafood in a pot】
2018 Year's best nlp article , Say first conclusion , Some reference values can be shared :
summary :

SSG Model details and Implementation .
Model diagram :

Encoder
Make (X1,X2,X3,Xm) by m A sequence of words . Let's start with an embedded matrix (embedding matrix), hold Embedded into a dense embedded vector , |V| Is the size of the glossary , k Is the dimension of the embedded vector .
We use one bidirectional LSTM Read the text sequence from two directions x, And calculate the hidden state of each word :

We connect the hidden states in two directions to get the i The final hidden state of words ,

This makes the state have i Word centered sequence information .


there pack You can go to pytorch Search the official function on the official website
pack_padded_sequence
When the model predicts different labels , Not all words contribute the same . The attention mechanism will focus on different parts of the text sequence , Generate a context vector (context vector).
Special , Adopted in this paper Attention yes global attention, What is? global attention, Here I'll list :

It is written in the original , We can make a comparison :

The attention model uses the additive model .

Decoder
Here in the sequence generation model decode Some of them have been transformed , Not only the correlation between tags is considered , It also automatically obtains the key information of the input text (Attention Mechanism )
Decoder In the t The hidden state of time is calculated as follows :

among ,[g(yt−1); ct−1] It means g(yt−1) and ct−1. g(yt−1) The connection of , g(yt−1) Is the embedding of labels , The label here refers to yt-1 The label corresponding to the highest probability under the distribution .yt-1 Is in t- Always in the tag space L The probability distribution on the , The calculation is as follows
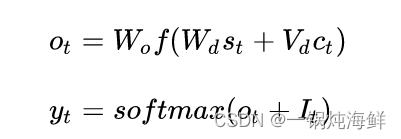
class rnn_decoder(nn.Module):
def __init__(self, config, embedding=None, use_attention=True):
super(rnn_decoder, self).__init__()
self.config = config
self.hidden_size = config.hidden_size
self.embedding = embedding if embedding is not None else nn.Embedding(config.tgt_vocab_size, config.emb_size)
input_size = 2 * config.emb_size if config.global_emb else config.emb_size
if config.cell == 'gru':
self.rnn = StackedGRU(input_size=input_size, hidden_size=config.hidden_size,
num_layers=config.dec_num_layers, dropout=config.dropout)
else:
self.rnn = StackedLSTM(input_size=input_size, hidden_size=config.hidden_size,
num_layers=config.dec_num_layers, dropout=config.dropout)
self.linear = nn.Linear(config.hidden_size, config.tgt_vocab_size)
if not use_attention or config.attention == 'None':
self.attention = None
elif config.attention == 'bahdanau':
self.attention = attention.bahdanau_attention(config.hidden_size, input_size)
elif config.attention == 'luong':
self.attention = attention.luong_attention(config.hidden_size, input_size, config.pool_size)
elif config.attention == 'luong_gate':
self.attention = attention.luong_gate_attention(config.hidden_size, input_size)
self.dropout = nn.Dropout(config.dropout)
if config.global_emb:
self.ge_proj1 = nn.Linear(config.emb_size, config.emb_size)
self.ge_proj2 = nn.Linear(config.emb_size, config.emb_size)
self.softmax = nn.Softmax(dim=1)
def forward(self, input, state, output=None, mask=None):
embs = self.embedding(input)
if self.config.global_emb:
if output is None:
output = embs.new_zeros(embs.size(0), self.config.tgt_vocab_size)
probs = self.softmax(output / self.config.tau) # label
# Multiply two tensor matrices , stay PyTorch Through torch.matmul Function implementation ;(embedding.weight)ei It means the moment i Output corresponding Embedding Of label
emb_avg = torch.matmul(probs, self.embedding.weight)
#H yes transform gate, Used to control the proportion of weighted average embedding
H = torch.sigmoid(self.ge_proj1(embs) + self.ge_proj2(emb_avg))
emb_glb = H * embs + (1 - H) * emb_avg #g(yt-1)=(1-H)*e+H*e
embs = torch.cat((embs, emb_glb), dim=-1)
output, state = self.rnn(embs, state)#embs be equal to ei state It looks like it is. Ct
if self.attention is not None:
if self.config.attention == 'luong_gate':
output, attn_weights = self.attention(output)
else:
output, attn_weights = self.attention(output, embs)
else:
attn_weights = None
output = self.compute_score(output)
if self.config.mask and mask: #mask softmax
# Connect the input tensor sequence along a new dimension , All tensors in the sequence should be of the same shape ;stack The result returned by the function will add a new dimension , and stack() Function specified dim Parameters , Is the new dimension ( Subscript ) Location .
mask = torch.stack(mask, dim=1).long()
output.scatter_(dim=1, index=mask, value=-1e7)
return output, state, attn_weightsGlobal Embedding


among H yes transform gate, Used to control the proportion of weighted average embedding . be-all For the weight matrix . By considering each label Probability , The model can reduce the loss of wrong prediction caused by previous time steps . This makes the model more accurate .
- problem : The output of multi label classification obviously cannot be repeated .
- resolvent : The author finally Softmax When outputting It Remove the exported labels .
yt = sof tmax(ot + It)
The expression of is as follows , If the tag has been output , be It For negative infinity ,

- problem : Seq2Seq At a certain moment in t The output of is right to the moment t+1 The output of has a great impact , That is to say, the moment Mistakes will be right for the moment All subsequent outputs have a serious impact .
- resolvent : In the multi label classification problem , We obviously don't want to have such a strong correlation between tags , So the author puts forward Global Embedding To solve this problem .
Besides , The author also uses some skills in the data preprocessing stage . such as , Considering that tags with more occurrences play a stronger role in tag correlation training , During training, the tags are sorted from high to low according to their occurrence times as the output sequence . The advantage of doing so is , Tags that appear more often can appear LSTM In front of , So as to better guide the output of the whole label .
Source of the paper :
SGM: Sequence Generation Model for Multi-label Classification
边栏推荐
- Use of shutter Intl
- 尝试解决YOLOv5推理rtsp有延迟的一些方法
- 7 kinds of visual MLP finishing (Part 1)
- 软件过程与管理复习(八)
- OpenCV读取中文路径下的图片,并对其格式转化不改变颜色
- Run yolov5 process record based on mindspire
- 8种视觉Transformer整理(上)
- Pointnet++代码详解(四):index_points函数
- Pointnet++代码详解(五):sample_and_group函数和samle_and_group_all函数
- Pointnet++代码详解(六):PointNetSetAbstraction层
猜你喜欢

Geo_ CNN (tensorflow version)

微信小程序中的WXML模板语法

微信小程序的常用组件

8种视觉Transformer整理(上)

VS 中 error C4996: ‘scanf‘: This function or variable may be unsafe. 的解决方法。
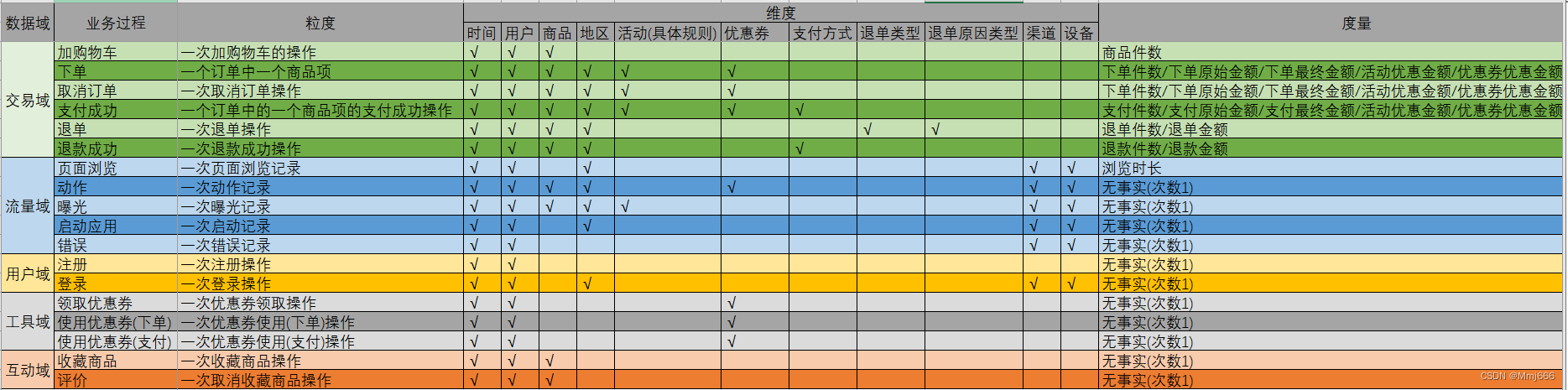
10. DWD layer construction of data warehouse construction
微信小程序之计算器

Pointnet++ code explanation (VII): pointnetsetabstractionmsg layer

基于bert的情感分类
Wxml template syntax in wechat applet
随机推荐
Kotlin scope function
9. Dim layer construction of data warehouse construction
5. Business analysis of data acquisition channel construction
8. ODS layer construction of data warehouse
Opencv reads the image under the Chinese path and converts its format without changing the color
Write a timed self-test
Geo_CNN(Tensorflow版本)
2021-05-21
Selective Kernel Networks方法简单整理
Pointnet++代码详解(七):PointNetSetAbstractionMsg层
微信小程序的常用組件
C language implementation of iteration and binary search
使用OpenCV、ONNXRuntime部署YOLOV7目标检测——记录贴
Comparative learning loss function (rince/relic/relicv2)
微信小程序的页面导航
The OCR tag of the pad is converted to TXT format
Deep clustering correlation (three articles)
Parsing bad JSON data using gson
自监督学习概述
Class file format understanding