KR-FinBert & KR-FinBert-SC
Much progress has been made in the NLP (Natural Language Processing) field, with numerous studies showing that domain adaptation using small-scale corpus and fine-tuning with labeled data is effective for overall performance improvement. we proposed KR-FinBert for the financial domain by further pre-training it on a financial corpus and fine-tuning it for sentiment analysis. As many studies have shown, the performance improvement through adaptation and conducting the downstream task was also clear in this experiment.
Data
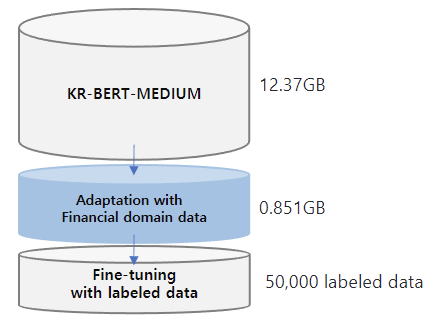
The training data for this model is expanded from those of KR-BERT-MEDIUM, texts from Korean Wikipedia, general news articles, legal texts crawled from the National Law Information Center and Korean Comments dataset. For the transfer learning, corporate related economic news articles from 72 media sources such as the Financial Times, The Korean Economy Daily, etc and analyst reports from 16 securities companies such as Kiwoom Securities, Samsung Securities, etc are added. Included in the dataset is 440,067 news titles with their content and 11,237 analyst reports. The total data size is about 13.22GB. For mlm training, we split the data line by line and the total no. of lines is 6,379,315. KR-FinBert is trained for 5.5M steps with the maxlen of 512, training batch size of 32, and learning rate of 5e-5, taking 67.48 hours to train the model using NVIDIA TITAN XP.
Models
Requirements
- transformers v 4.0.0
- Pytorch_lightning v1.3.0
MLM model
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("snunlp/KR-FinBert")
model = AutoModelForMaskedLM.from_pretrained("snunlp/KR-FinBert")
python3 run_mlm.py \
--model_name_or_path snunlp/KR-Medium \
--train_file newsdata_line.txt \
--do_train \
--output_dir ./test-mlm \
--line_by_line True \
--max_seq_length 512

 4 Sep 28, 2022
4 Sep 28, 2022
 237 Jan 02, 2023
237 Jan 02, 2023
 1 May 14, 2022
1 May 14, 2022
 315 Dec 21, 2022
315 Dec 21, 2022
 1 Dec 13, 2021
1 Dec 13, 2021
 466 Dec 06, 2022
466 Dec 06, 2022
 99 Jan 06, 2023
99 Jan 06, 2023
 1 Apr 03, 2022
1 Apr 03, 2022
 3 Jul 24, 2022
3 Jul 24, 2022
 69 Jan 03, 2023
69 Jan 03, 2023
 2 Jan 10, 2022
2 Jan 10, 2022
 64 May 08, 2022
64 May 08, 2022
 5 Jul 16, 2021
5 Jul 16, 2021
 72 Dec 30, 2022
72 Dec 30, 2022
 7 Sep 22, 2022
7 Sep 22, 2022
 3 Jan 03, 2023
3 Jan 03, 2023
 2 Jan 04, 2023
2 Jan 04, 2023
 285 Jan 02, 2023
285 Jan 02, 2023
 3 Oct 06, 2022
3 Oct 06, 2022