pytorch-optimizer

Documentation
https://pytorch-optimizers.readthedocs.io/en/latest/
Usage
Install
$ pip3 install pytorch-optimizer
Simple Usage
from pytorch_optimizer import Ranger21 ... model = YourModel() optimizer = Ranger21(model.parameters()) ... for input, output in data: optimizer.zero_grad() loss = loss_function(output, model(input)) loss.backward() optimizer.step()
Supported Optimizers
| Optimizer | Description | Official Code | Paper |
|---|---|---|---|
| AdaBelief | Adapting Stepsizes by the Belief in Observed Gradients | github | https://arxiv.org/abs/2010.07468 |
| AdaBound | Adaptive Gradient Methods with Dynamic Bound of Learning Rate | github | https://openreview.net/forum?id=Bkg3g2R9FX |
| AdaHessian | An Adaptive Second Order Optimizer for Machine Learning | github | https://arxiv.org/abs/2006.00719 |
| AdamP | Slowing Down the Slowdown for Momentum Optimizers on Scale-invariant Weights | github | https://arxiv.org/abs/2006.08217 |
| diffGrad | An Optimization Method for Convolutional Neural Networks | github | https://arxiv.org/abs/1909.11015v3 |
| MADGRAD | A Momentumized, Adaptive, Dual Averaged Gradient Method for Stochastic | github | https://arxiv.org/abs/2101.11075 |
| RAdam | On the Variance of the Adaptive Learning Rate and Beyond | github | https://arxiv.org/abs/1908.03265 |
| Ranger | a synergistic optimizer combining RAdam and LookAhead, and now GC in one optimizer | github | https://bit.ly/3zyspC3 |
| Ranger21 | a synergistic deep learning optimizer | github | https://arxiv.org/abs/2106.13731 |
Useful Resources
Several optimization ideas to regularize & stabilize the training. Most of the ideas are applied in Ranger21 optimizer.
Also, most of the captures are taken from Ranger21 paper.
Adaptive Gradient Clipping
NFNet (Normalized-Free Network) paper.
AGC (Adaptive Gradient Clipping) clips gradients based on the unit-wise ratio of gradient norms to parameter norms.
Gradient Centralization
 |
Gradient Centralization (GC) operates directly on gradients by centralizing the gradient to have zero mean.
Softplus Transformation
By running the final variance denom through the softplus function, it lifts extremely tiny values to keep them viable.
- paper : arXiv
Gradient Normalization
Norm Loss
 |
- paper : arXiv
Positive-Negative Momentum
 |
Linear learning rate warmup
 |
- paper : arXiv
Stable weight decay
 |
Explore-exploit learning rate schedule
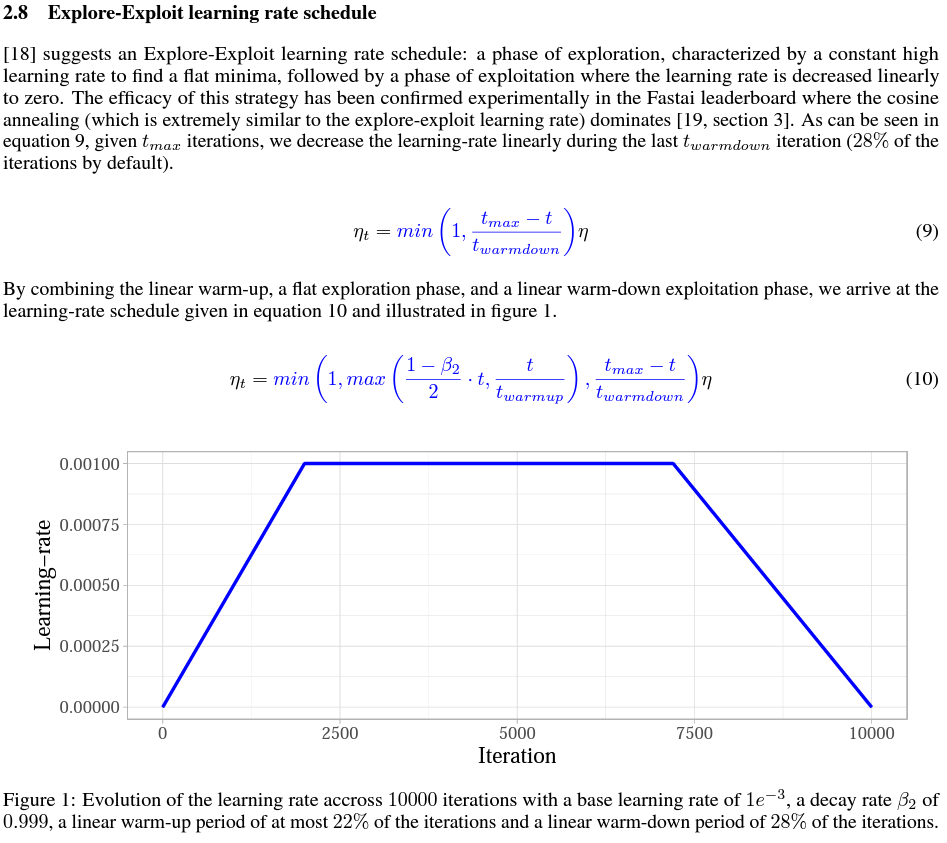 |
Lookahead
k steps forward, 1 step back. Lookahead consisting of keeping an exponential moving average of the weights that is
k_{lookahead} steps (5 by default).
Chebyshev learning rate schedule
Acceleration via Fractal Learning Rate Schedules
- paper : arXiv
(Adaptive) Sharpness-Aware Minimization
On the Convergence of Adam and Beyond
- paper : paper
Citations
AdamP
@inproceedings{heo2021adamp,
title={AdamP: Slowing Down the Slowdown for Momentum Optimizers on Scale-invariant Weights},
author={Heo, Byeongho and Chun, Sanghyuk and Oh, Seong Joon and Han, Dongyoon and Yun, Sangdoo and Kim, Gyuwan and Uh, Youngjung and Ha, Jung-Woo},
year={2021},
booktitle={International Conference on Learning Representations (ICLR)},
}
Adaptive Gradient Clipping (AGC)
@article{brock2021high,
author={Andrew Brock and Soham De and Samuel L. Smith and Karen Simonyan},
title={High-Performance Large-Scale Image Recognition Without Normalization},
journal={arXiv preprint arXiv:2102.06171},
year={2021}
}
Chebyshev LR Schedules
@article{agarwal2021acceleration,
title={Acceleration via Fractal Learning Rate Schedules},
author={Agarwal, Naman and Goel, Surbhi and Zhang, Cyril},
journal={arXiv preprint arXiv:2103.01338},
year={2021}
}
Gradient Centralization (GC)
@inproceedings{yong2020gradient,
title={Gradient centralization: A new optimization technique for deep neural networks},
author={Yong, Hongwei and Huang, Jianqiang and Hua, Xiansheng and Zhang, Lei},
booktitle={European Conference on Computer Vision},
pages={635--652},
year={2020},
organization={Springer}
}
Lookahead
@article{zhang2019lookahead,
title={Lookahead optimizer: k steps forward, 1 step back},
author={Zhang, Michael R and Lucas, James and Hinton, Geoffrey and Ba, Jimmy},
journal={arXiv preprint arXiv:1907.08610},
year={2019}
}
RAdam
@inproceedings{liu2019radam,
author = {Liu, Liyuan and Jiang, Haoming and He, Pengcheng and Chen, Weizhu and Liu, Xiaodong and Gao, Jianfeng and Han, Jiawei},
booktitle = {Proceedings of the Eighth International Conference on Learning Representations (ICLR 2020)},
month = {April},
title = {On the Variance of the Adaptive Learning Rate and Beyond},
year = {2020}
}
Norm Loss
@inproceedings{georgiou2021norm,
title={Norm Loss: An efficient yet effective regularization method for deep neural networks},
author={Georgiou, Theodoros and Schmitt, Sebastian and B{\"a}ck, Thomas and Chen, Wei and Lew, Michael},
booktitle={2020 25th International Conference on Pattern Recognition (ICPR)},
pages={8812--8818},
year={2021},
organization={IEEE}
}
Positive-Negative Momentum
@article{xie2021positive,
title={Positive-Negative Momentum: Manipulating Stochastic Gradient Noise to Improve Generalization},
author={Xie, Zeke and Yuan, Li and Zhu, Zhanxing and Sugiyama, Masashi},
journal={arXiv preprint arXiv:2103.17182},
year={2021}
}
Explore-Exploit learning rate schedule
@article{iyer2020wide,
title={Wide-minima Density Hypothesis and the Explore-Exploit Learning Rate Schedule},
author={Iyer, Nikhil and Thejas, V and Kwatra, Nipun and Ramjee, Ramachandran and Sivathanu, Muthian},
journal={arXiv preprint arXiv:2003.03977},
year={2020}
}
Linear learning-rate warm-up
@article{ma2019adequacy,
title={On the adequacy of untuned warmup for adaptive optimization},
author={Ma, Jerry and Yarats, Denis},
journal={arXiv preprint arXiv:1910.04209},
volume={7},
year={2019}
}
Stable weight decay
@article{xie2020stable,
title={Stable weight decay regularization},
author={Xie, Zeke and Sato, Issei and Sugiyama, Masashi},
journal={arXiv preprint arXiv:2011.11152},
year={2020}
}
Softplus transformation
@article{tong2019calibrating,
title={Calibrating the adaptive learning rate to improve convergence of adam},
author={Tong, Qianqian and Liang, Guannan and Bi, Jinbo},
journal={arXiv preprint arXiv:1908.00700},
year={2019}
}
MADGRAD
@article{defazio2021adaptivity,
title={Adaptivity without compromise: a momentumized, adaptive, dual averaged gradient method for stochastic optimization},
author={Defazio, Aaron and Jelassi, Samy},
journal={arXiv preprint arXiv:2101.11075},
year={2021}
}
AdaHessian
@article{yao2020adahessian,
title={ADAHESSIAN: An adaptive second order optimizer for machine learning},
author={Yao, Zhewei and Gholami, Amir and Shen, Sheng and Mustafa, Mustafa and Keutzer, Kurt and Mahoney, Michael W},
journal={arXiv preprint arXiv:2006.00719},
year={2020}
}
AdaBound
@inproceedings{Luo2019AdaBound,
author = {Luo, Liangchen and Xiong, Yuanhao and Liu, Yan and Sun, Xu},
title = {Adaptive Gradient Methods with Dynamic Bound of Learning Rate},
booktitle = {Proceedings of the 7th International Conference on Learning Representations},
month = {May},
year = {2019},
address = {New Orleans, Louisiana}
}
AdaBelief
@article{zhuang2020adabelief,
title={Adabelief optimizer: Adapting stepsizes by the belief in observed gradients},
author={Zhuang, Juntang and Tang, Tommy and Ding, Yifan and Tatikonda, Sekhar and Dvornek, Nicha and Papademetris, Xenophon and Duncan, James S},
journal={arXiv preprint arXiv:2010.07468},
year={2020}
}
Sharpness-Aware Minimization
@article{foret2020sharpness,
title={Sharpness-aware minimization for efficiently improving generalization},
author={Foret, Pierre and Kleiner, Ariel and Mobahi, Hossein and Neyshabur, Behnam},
journal={arXiv preprint arXiv:2010.01412},
year={2020}
}
Adaptive Sharpness-Aware Minimization
@article{kwon2021asam,
title={ASAM: Adaptive Sharpness-Aware Minimization for Scale-Invariant Learning of Deep Neural Networks},
author={Kwon, Jungmin and Kim, Jeongseop and Park, Hyunseo and Choi, In Kwon},
journal={arXiv preprint arXiv:2102.11600},
year={2021}
}
diffGrad
@article{dubey2019diffgrad,
title={diffgrad: An optimization method for convolutional neural networks},
author={Dubey, Shiv Ram and Chakraborty, Soumendu and Roy, Swalpa Kumar and Mukherjee, Snehasis and Singh, Satish Kumar and Chaudhuri, Bidyut Baran},
journal={IEEE transactions on neural networks and learning systems},
volume={31},
number={11},
pages={4500--4511},
year={2019},
publisher={IEEE}
}
On the Convergence of Adam and Beyond
@article{reddi2019convergence,
title={On the convergence of adam and beyond},
author={Reddi, Sashank J and Kale, Satyen and Kumar, Sanjiv},
journal={arXiv preprint arXiv:1904.09237},
year={2019}
}
Author
Hyeongchan Kim / @kozistr


![[Feature] support torch.hub.load](https://avatars.githubusercontent.com/u/37621276?v=4)
![[Test] Increase the test coverage](https://avatars.githubusercontent.com/u/15344796?v=4)
![[Build] Bump setuptools from 65.5.0 to 65.5.1](https://avatars.githubusercontent.com/in/29110?v=4)


 1.5k Jan 07, 2023
1.5k Jan 07, 2023
 4.1k Jan 03, 2023
4.1k Jan 03, 2023
 382 Dec 06, 2022
382 Dec 06, 2022
 405 Nov 27, 2022
405 Nov 27, 2022
 1.7k Jan 06, 2023
1.7k Jan 06, 2023
 15 Dec 24, 2022
15 Dec 24, 2022
 96 Nov 28, 2022
96 Nov 28, 2022
 704 Dec 14, 2022
704 Dec 14, 2022
 234 Dec 07, 2022
234 Dec 07, 2022
 164 Jan 05, 2023
164 Jan 05, 2023
 55 Dec 01, 2022
55 Dec 01, 2022
 1.2k Jan 04, 2023
1.2k Jan 04, 2023
 6 Jan 08, 2022
6 Jan 08, 2022
 433 Dec 27, 2022
433 Dec 27, 2022
 56 Sep 13, 2022
56 Sep 13, 2022
 2.1k Jan 01, 2023
2.1k Jan 01, 2023
 5k Jan 02, 2023
5k Jan 02, 2023
 1.6k Dec 28, 2022
1.6k Dec 28, 2022
 1.3k Jan 05, 2023
1.3k Jan 05, 2023