Web Scrapping Popular Youtube Tech Channels with Selenium
Data Mining, Data Wrangling, and Exploratory Data Analysis

About the Data
Web scraping was performed on the Top 10 Tech Channels on Youtube using Selenium (an automated browser (driver) controlled using python, which is often used in web scraping and web testing). Web scrapped Youtube channels were were determined using a Top 10 Tech Youtubers list from blog.bit.ai.
All data was saved to multiple CSV files to aid in further analyze on a Google Colab notebook. Please see my for more more details.
Sample of Data Collected
The average number of videos per channel was around 200. In total, the data from 2000 videos was scrapped.
Word Cloud of Word Frequency in Video Titles
.png)
.gif)
.gif)
Take Aways
.png)
-
Video Comment numbers have very little correlation to any data that was obtained in this project.
-
The following seem to be seems to be highly correlated.
- Channel Views and Subscribers
- Interactions and Video Views
-
Video titles fall into 5 topic groups.
Kmeans and PCA used to create clusters for video titles
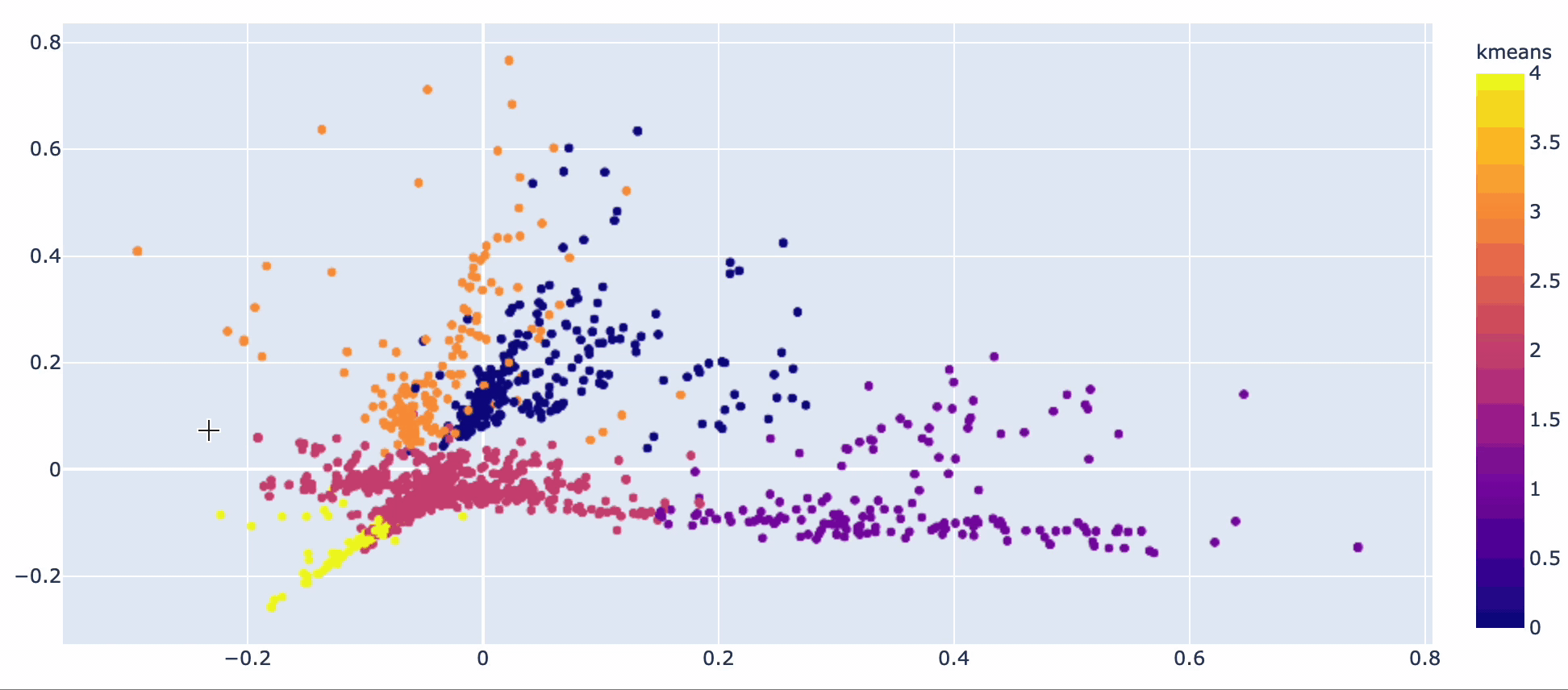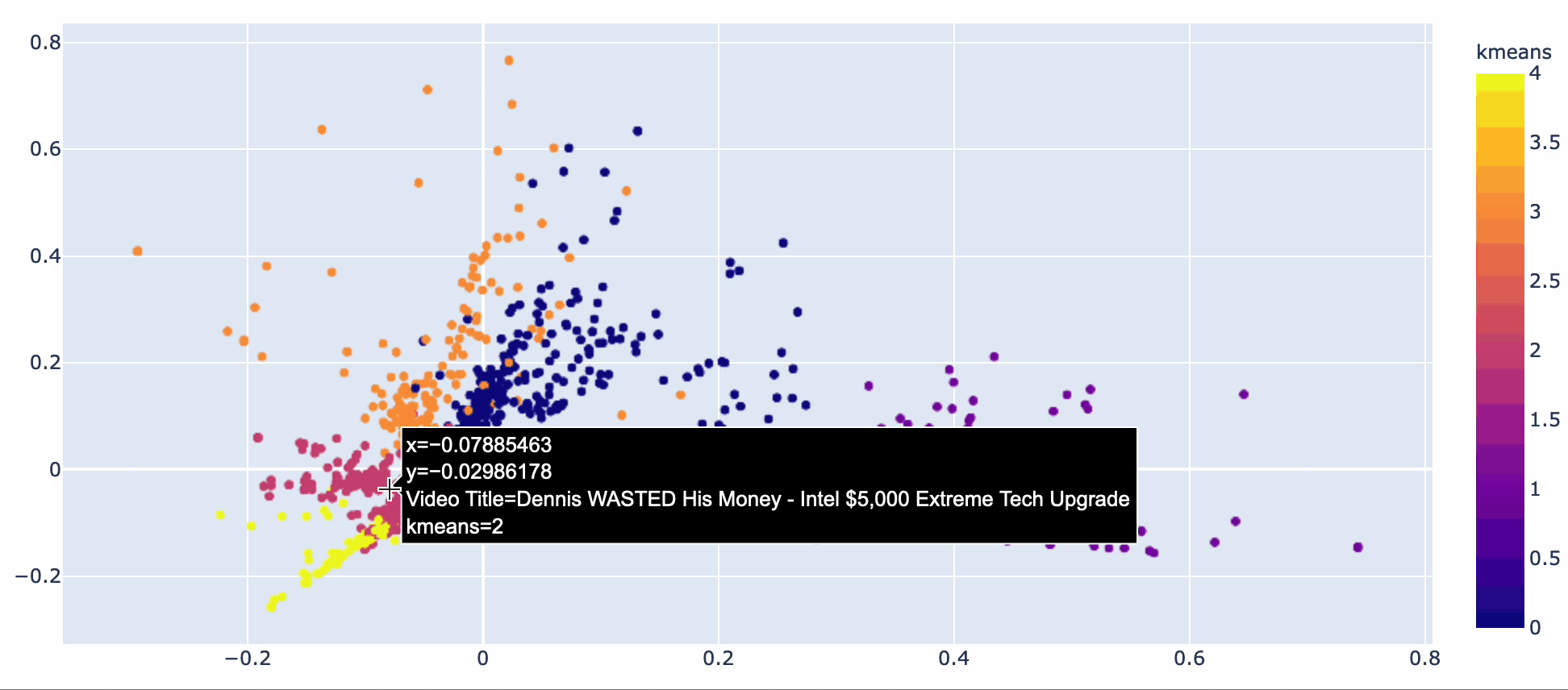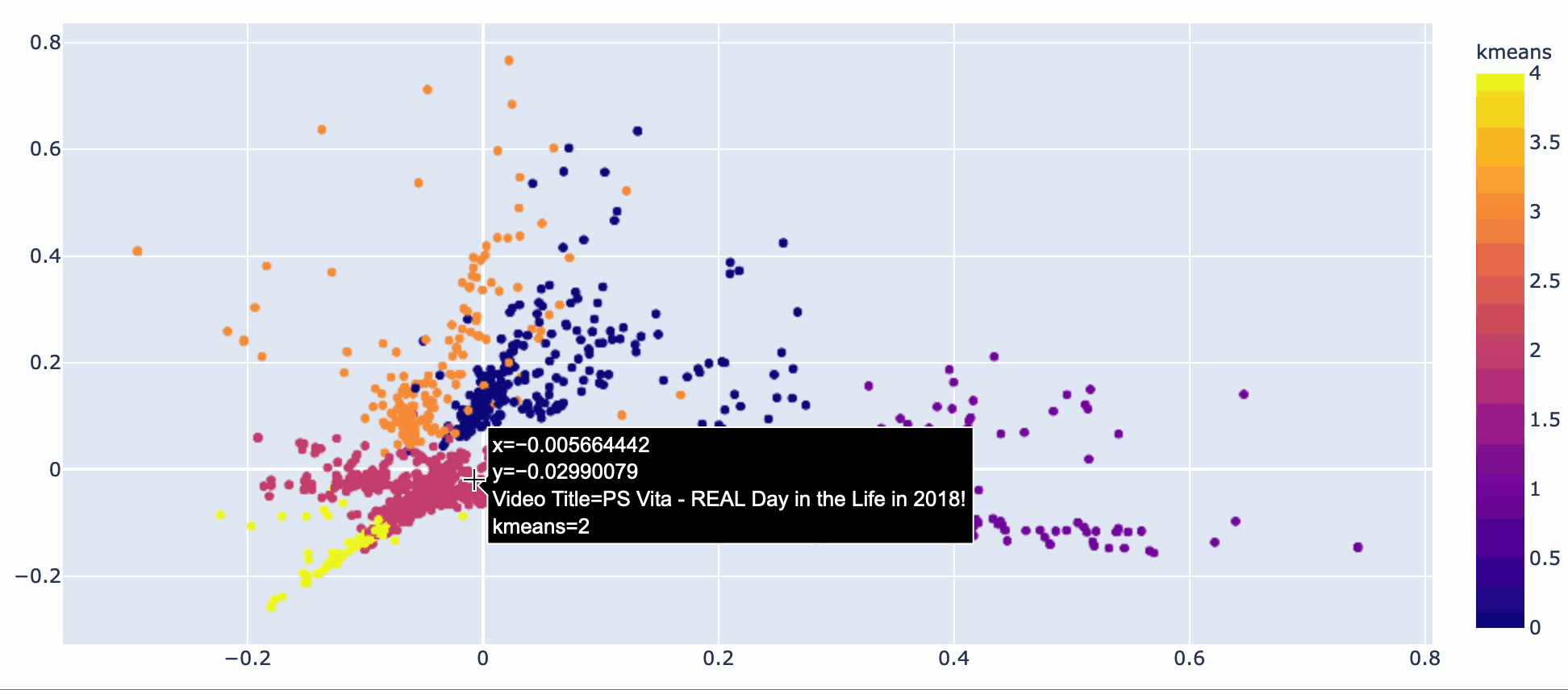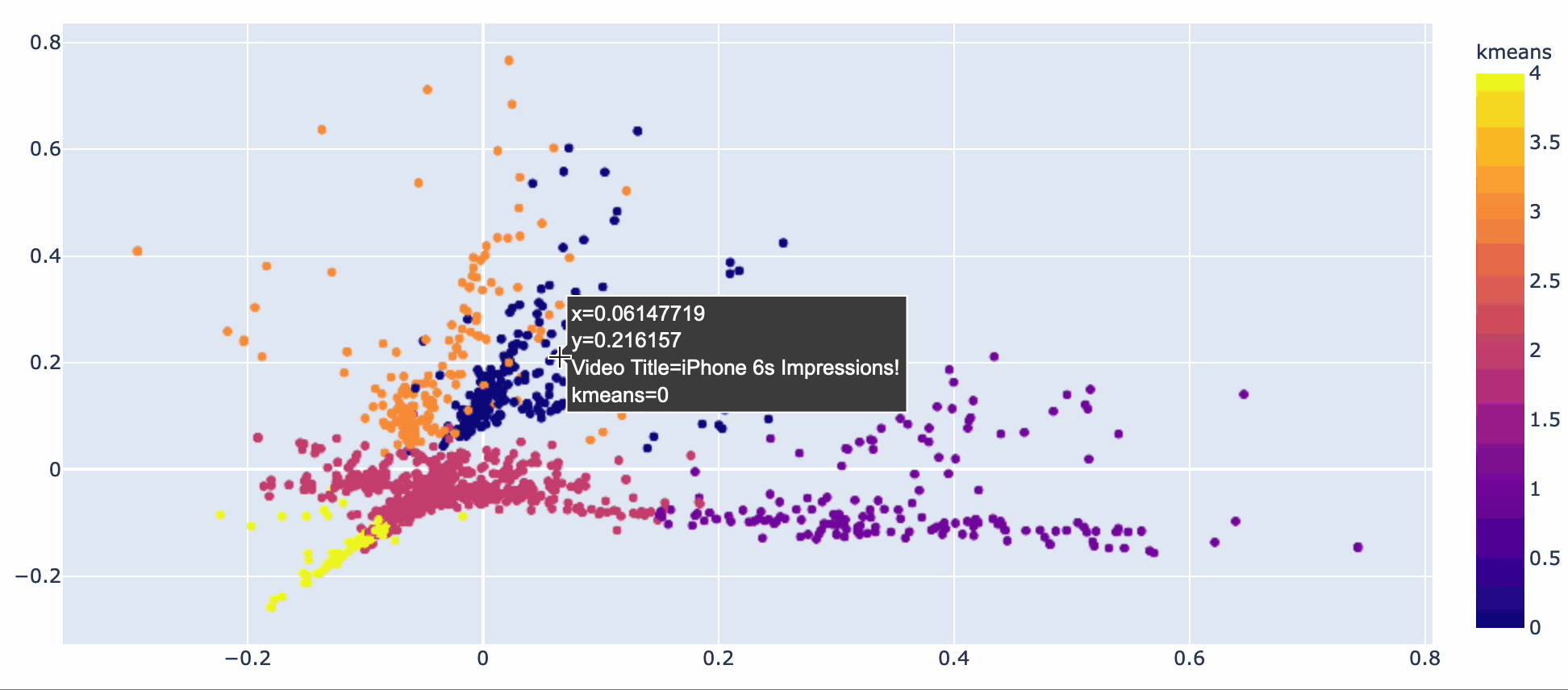
- Iphone (kmeans 0)
- Samsung (kmeans 1)
- Reviews (kmeans 2)
- Unboxing (kmeans 3)
- How-to (kmeans 4)
-
70% of the the most viewed videos are about phones.
.png)
-
Join Date (Date a Youtube Channel was created) does not seem to have any relationship to number of subscribers or overall cha
.png)

 3.7k Dec 27, 2022
3.7k Dec 27, 2022
 173 Dec 05, 2022
173 Dec 05, 2022
 23 Sep 15, 2022
23 Sep 15, 2022
 9 Apr 06, 2022
9 Apr 06, 2022
 2 Jul 22, 2022
2 Jul 22, 2022
 1 Oct 29, 2021
1 Oct 29, 2021
 1 Oct 24, 2021
1 Oct 24, 2021
 1.5k Jan 04, 2023
1.5k Jan 04, 2023
 5 Nov 29, 2021
5 Nov 29, 2021
 2 Apr 29, 2022
2 Apr 29, 2022
 44 Oct 18, 2022
44 Oct 18, 2022
 27 Dec 18, 2022
27 Dec 18, 2022
 4 Aug 30, 2022
4 Aug 30, 2022
 1 Nov 28, 2021
1 Nov 28, 2021
 18 May 05, 2022
18 May 05, 2022
 11 Nov 01, 2022
11 Nov 01, 2022
 2 Dec 15, 2022
2 Dec 15, 2022
 6 Nov 21, 2022
6 Nov 21, 2022
 1 Jan 14, 2022
1 Jan 14, 2022