原神圣遗物半自动爬虫
说明
直接抓取原神界面中的圣遗物数据
目前只适配了背包页面的抓取
准确率:97.5%(普通通用接口,对 40 件随机圣遗物识别,统计完全正确的数量为 39)
准确率:100%(4k 屏幕,普通通用接口,对 110 件圣遗物识别,统计完全正确的数量为 110)
不排除还有小错误的情况,如果发现有错误请提交 issue 反馈!
使用教程
打包好的exe文件在右侧release获取
1.修改 config.ini
配置文件说明
[api]
access_token:百度 ocr access_token
Q:如何获取 access_token?
A:网上有很多方法,百度官方的在:百度官方教程
自 v1.1.0 版本开始 release 中附带获取 access_token 的程序,源码在 GetToken 文件夹
accurate_url/general_url:api 地址,一般不用更改
use:使用高精度还是普通接口(accurate_url/general_url)
[grasp_setting]
window_title:要抓取的窗口名,主要方便 PS 端/手机模拟器使用
left,top,right,bottom:面板在窗口中的位置(按照比例出现,如 left=0.67 表示 left 线段占总窗口的 67%)(典型的 16:9 分辨率使用预置选项即可)

2. 打开原神,进入背包圣遗物界面
3. 在原神中按Alt+Enter进入窗口模式
窗口模式说明
原神默认是以独占全屏的形式出现的,要置顶本窗口必须使其窗口化。
要返回独占全屏同样是按Alt+Enter
4. 运行程序(此时可以隐藏原神窗口)
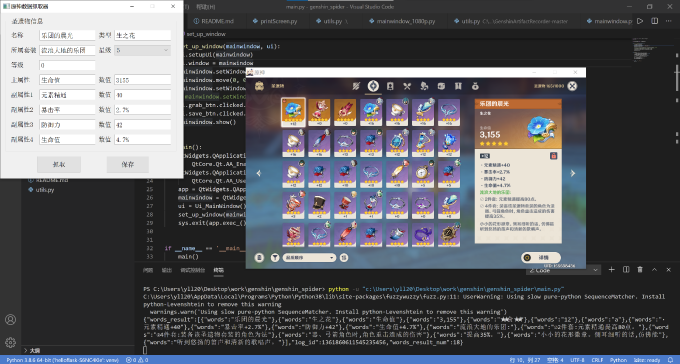
5. 点击抓取按钮抓取当前显示的圣遗物,点击保存按钮保存
输出
- 以 json 格式保存到剪贴板
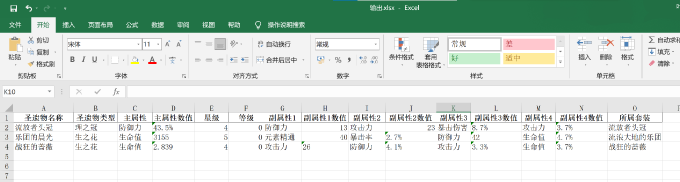
- 以 excel 形式保存到当前目录的 out.xls
示例图片
进入窗口模式:
抓取:
输出表格:

LOG
- 重构、整理代码(2021/2/17)
- 常见不合理错误纠正(2021/2/18)
- 去除部分依赖以减小打包体积(已替换 pandas 依赖为 xlrd 和 xlutils,打包体积减半为 38MB)(2021/2/18)
- 将配置项分离为文件
- 重构、整理代码
- 优化抓取速度和反馈(doing)
- 其他界面抓取
- 武器等抓取
常见问题
- 抓取到启动器怎么回事?
抓取窗口是判断窗口标题为原神实现的,推荐不使用启动器启动,如果确实抓出来了把抓出的启动器窗口关闭即可。关闭后应该不会再次抓取。 - 有封号风险吗?
抓取的原理是对窗口截图识别,没有对原神本身进行任何修改和干扰,理论上不会产生风险。这都要封号我就不玩了 - 为什么半自动?不能全自动?
先把半自动做好。 - 关于百度文字识别?
可以在通用普通接口的情况下取得除等级外很好的效果,也可以使用高精度接口(每日 500 次免费)获得更好的效果。 - 显示效果相关问题?
作者优先在 4k 环境下开发,但是只要游戏界面比例是典型的 16:9 都可以正常抓取,只是显示效果可能有细微的差距。

 4 Dec 03, 2022
4 Dec 03, 2022
 1 Dec 07, 2021
1 Dec 07, 2021
 7 Oct 23, 2022
7 Oct 23, 2022
 1 Jan 10, 2022
1 Jan 10, 2022
 5 Oct 17, 2022
5 Oct 17, 2022
 32 Oct 10, 2022
32 Oct 10, 2022
 2k Dec 28, 2022
2k Dec 28, 2022
 2 Mar 18, 2022
2 Mar 18, 2022
 1.6k Jan 01, 2023
1.6k Jan 01, 2023
 0 Jul 04, 2021
0 Jul 04, 2021
 1 Jan 24, 2022
1 Jan 24, 2022
 0 Sep 30, 2021
0 Sep 30, 2021
 2 Jul 22, 2022
2 Jul 22, 2022
 4 Jul 26, 2022
4 Jul 26, 2022
 3 Jul 05, 2021
3 Jul 05, 2021
 4.8k Jan 04, 2023
4.8k Jan 04, 2023
 10 Jul 03, 2022
10 Jul 03, 2022
 3 Dec 07, 2021
3 Dec 07, 2021
 1 Nov 05, 2021
1 Nov 05, 2021
 1 Jul 04, 2022
1 Jul 04, 2022