SearchifyX
SearchifyX, predecessor to Searchify, is a fast Quizlet, Quizizz, and Brainly webscraper with various stealth features.
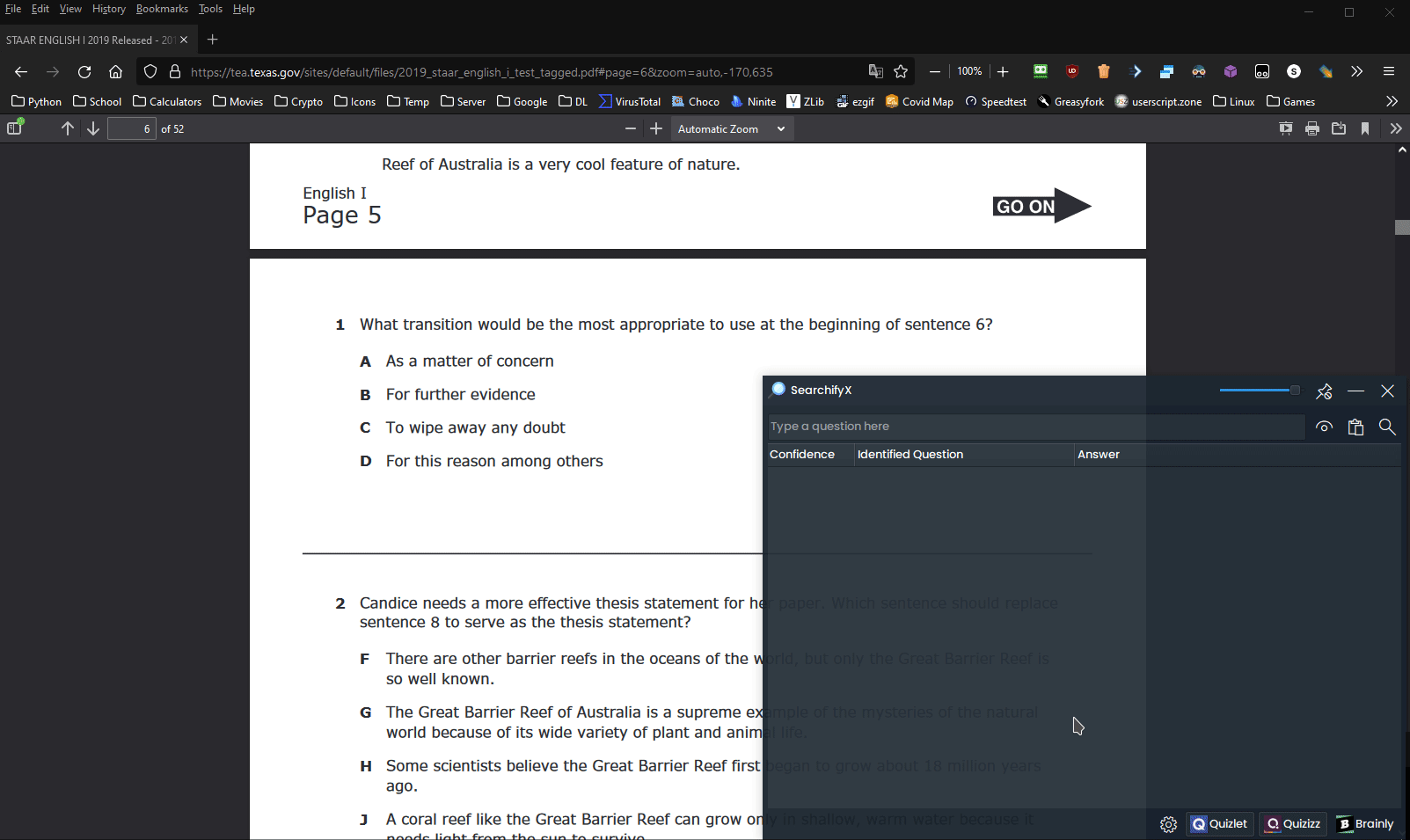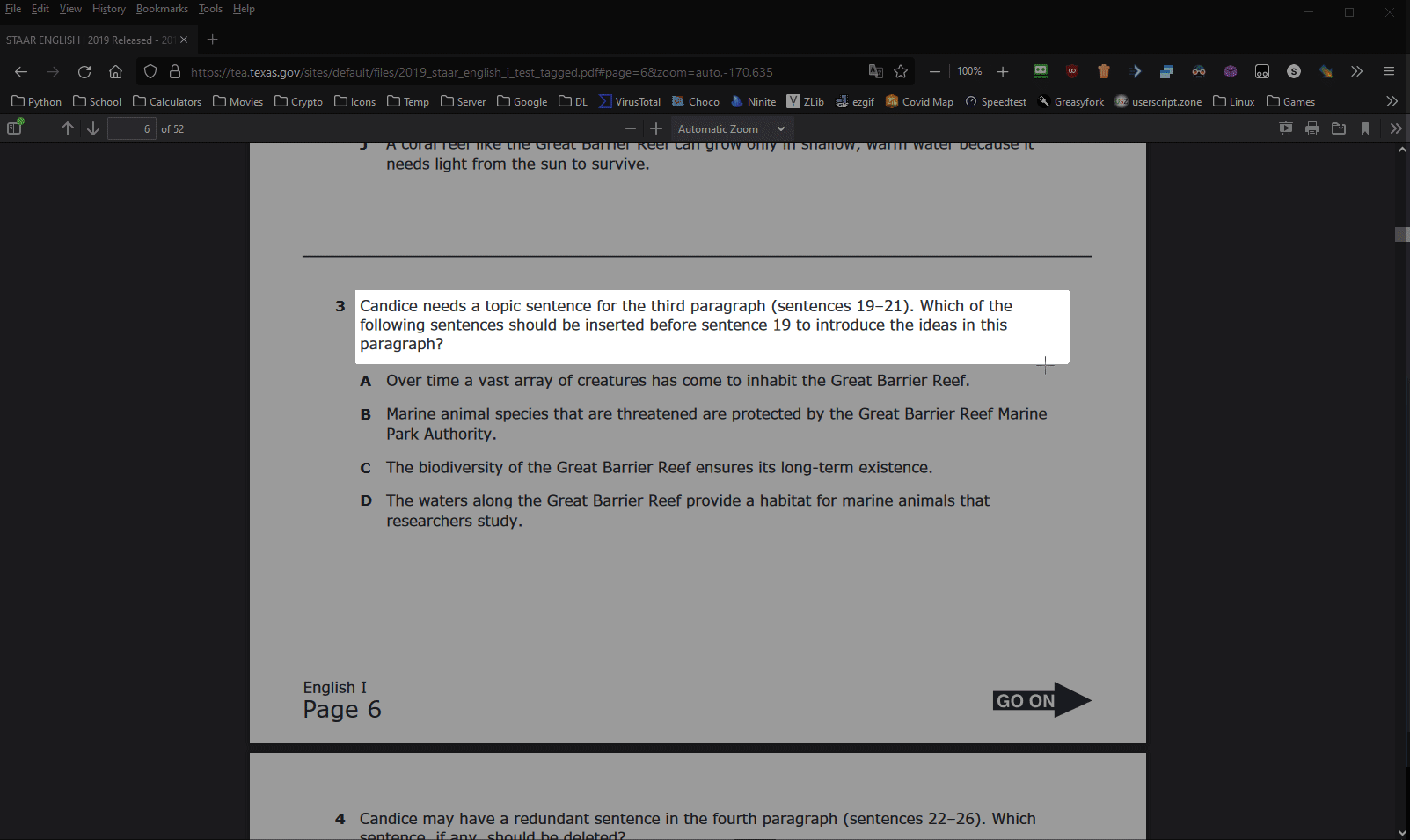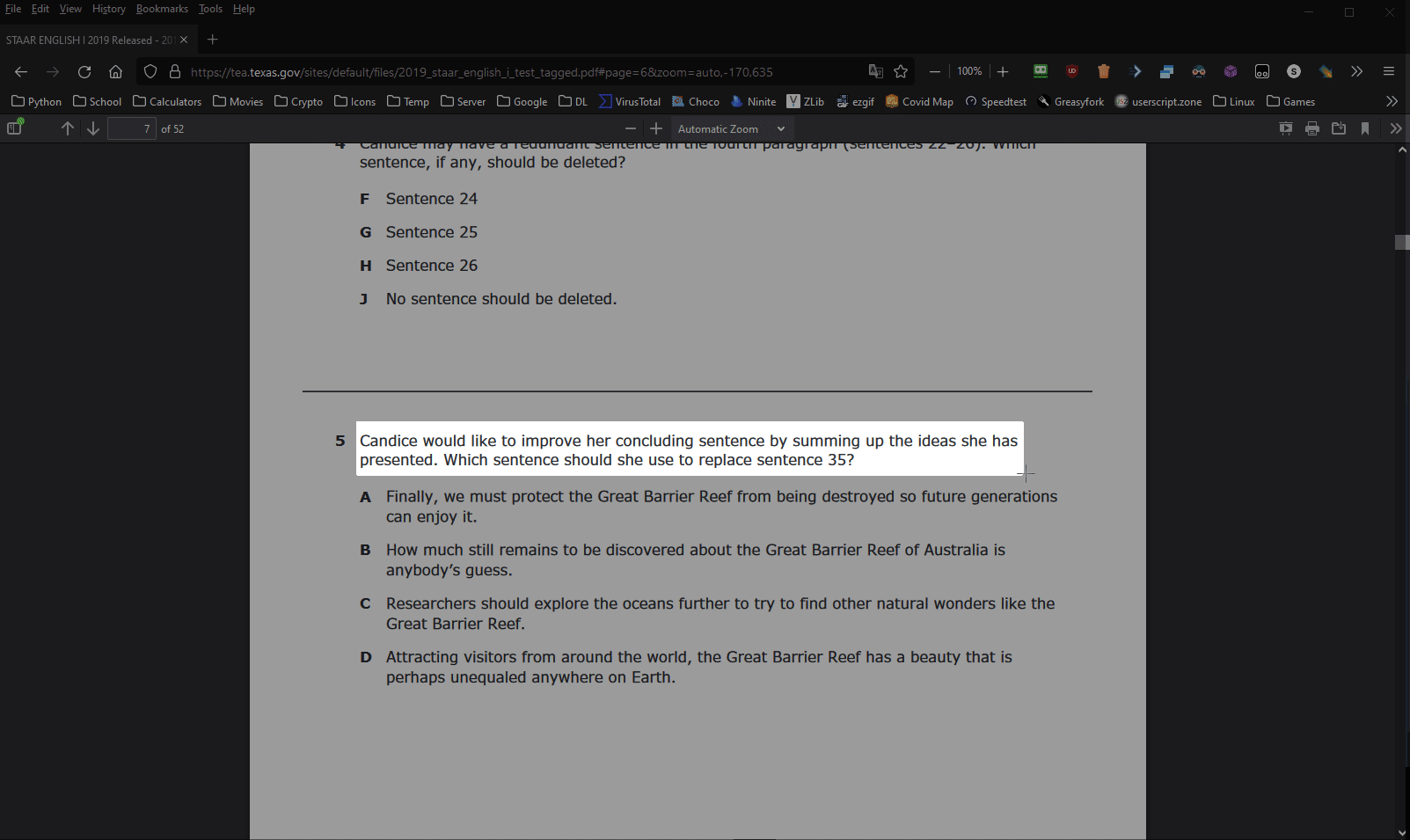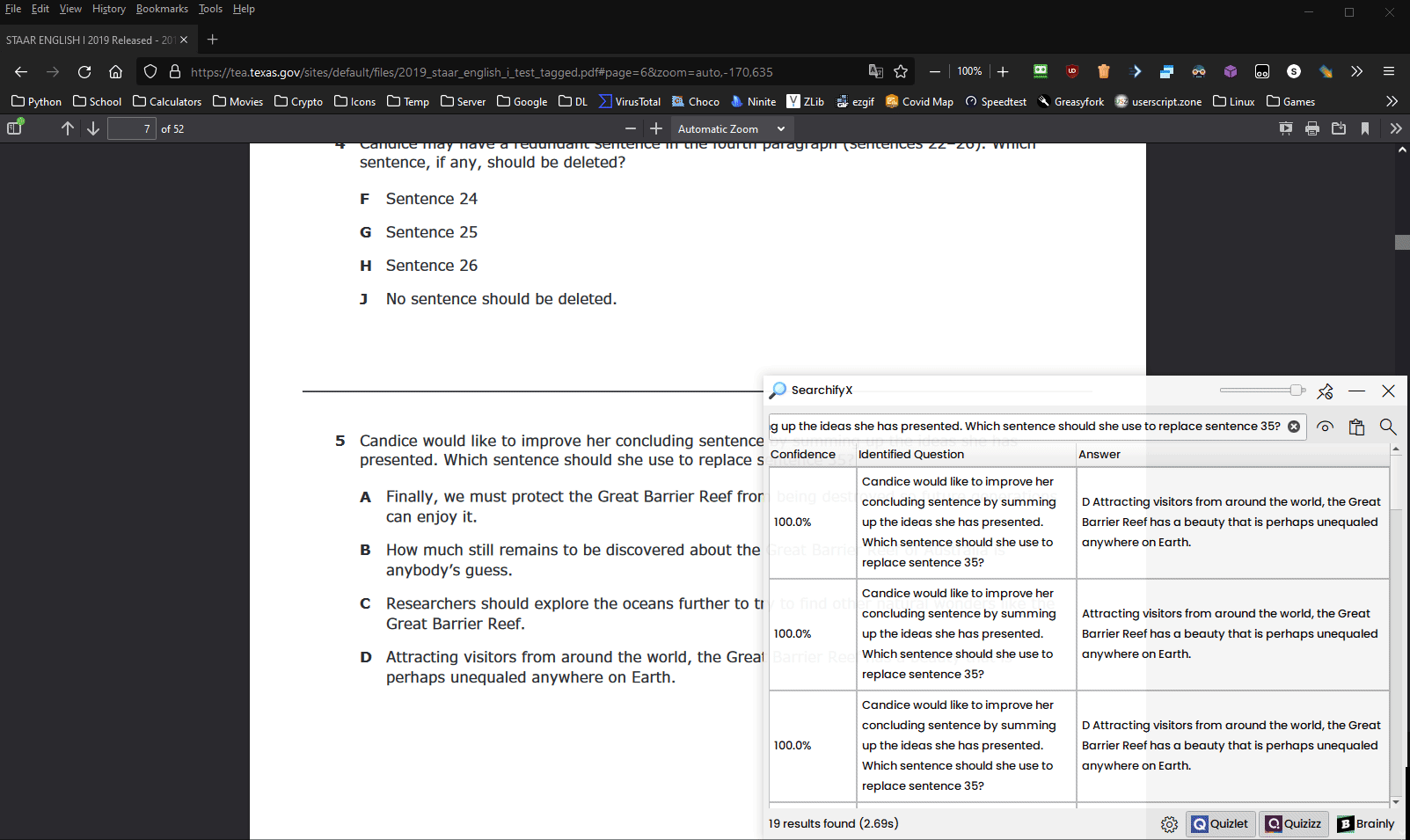
SearchifyX lets you easily query a quiz question through different answer websites (similar to Socratic on mobile), and sort them based on how similar they are to your query. It also includes a screen OCR scanner, hotkeys, and other features for stealthy use.
SearchifyX in action
Download
Binaries
Download Windows binaries here
Running from source code
Install the Python 3.8 dependencies:
python -m pip install requirements.txt
You also need to download tesseract-ocr and extract it to the root directory to use the OCR tool.
CLI usage
An alternative for Linux/Mac OS users is to use scraper.py as a CLI tool.
Usage:
scraper.py [-h] [--query QUERY] [--output OUTPUT] [--sites SITES]
Required arguments:
--query QUERY, -q QUERY
query to search for
Optional arguments:
-h, --help show this help message and exit
--output OUTPUT, -o OUTPUT
output file (optional)
--sites SITES, -s SITES
question sources quizlet,quizizz,brainly (comma seperated list)
What it does
-
Searches Bing for Quizlet, Quizizz, and Brainly results
-
Sort results by how similar the identified question is to the input question
Stealth options
-
Prevent window switching
-
Customizable global hotkeys
-
Hide/show window hotkey
-
OCR & search hotkey
-
Paste & search hotkey
-
Quickly change window opacity hotkey
-
-
Change window opacity (slider in title bar)
-
Option to not show in taskbar
Window switching safety lock
Many websites can detect when the window focus is lost. SearchifyX includes a window switching safety lock to prevent websites from knowing you are using a different window.
Note: The text search bar does not work when the Window switch safety lock is enabled. It is designed to be used with the OCR tool and Paste & Search tool.
Here is a demo website that turns black when the window is out of focus:

Improvements from Searchify
-
Completely rewritten from scratch
-
Added stealth features (listed above)
-
Added screen OCR scanner
-
Added global hotkeys
-
MAJOR changes to UI
-
MAJOR changes web scraper code (averages 1-2 seconds now; uses significantly less CPU)
-
Completely fixed the "Too many requests" error
-
Significantly more stable & returns better results
Interface
Dark theme

Light theme

Settings page

Disclaimer
The purpose of this program is to provide an example of asynchronous webscraping and data gathering in Python. I am not in any way attempting to promote cheating, and I am not responsible for any misuse of this tool. This tool was created strictly for educational purposes only.




 3.2k Dec 29, 2022
3.2k Dec 29, 2022
 2 Nov 16, 2021
2 Nov 16, 2021
 46 Nov 22, 2022
46 Nov 22, 2022
 1 Oct 23, 2021
1 Oct 23, 2021
 91 Dec 08, 2022
91 Dec 08, 2022
 2 Aug 03, 2022
2 Aug 03, 2022
 1 Jan 17, 2022
1 Jan 17, 2022
 499 Dec 09, 2022
499 Dec 09, 2022
 0 Dec 15, 2021
0 Dec 15, 2021
 3 Nov 24, 2022
3 Nov 24, 2022
 12 Oct 28, 2022
12 Oct 28, 2022
 4 Jul 26, 2022
4 Jul 26, 2022
 5 Nov 22, 2022
5 Nov 22, 2022
 3 Jul 08, 2022
3 Jul 08, 2022
 1 Jan 14, 2022
1 Jan 14, 2022
 1 Dec 19, 2021
1 Dec 19, 2021
 12 Oct 27, 2022
12 Oct 27, 2022
 0 May 15, 2022
0 May 15, 2022
 2.2k Jan 05, 2023
2.2k Jan 05, 2023
 1 Jan 25, 2022
1 Jan 25, 2022