Scrappp
A Very simple free proxy list scraper, made in python The tool scrape proxy from diffrent sites and api's.
Screenshots
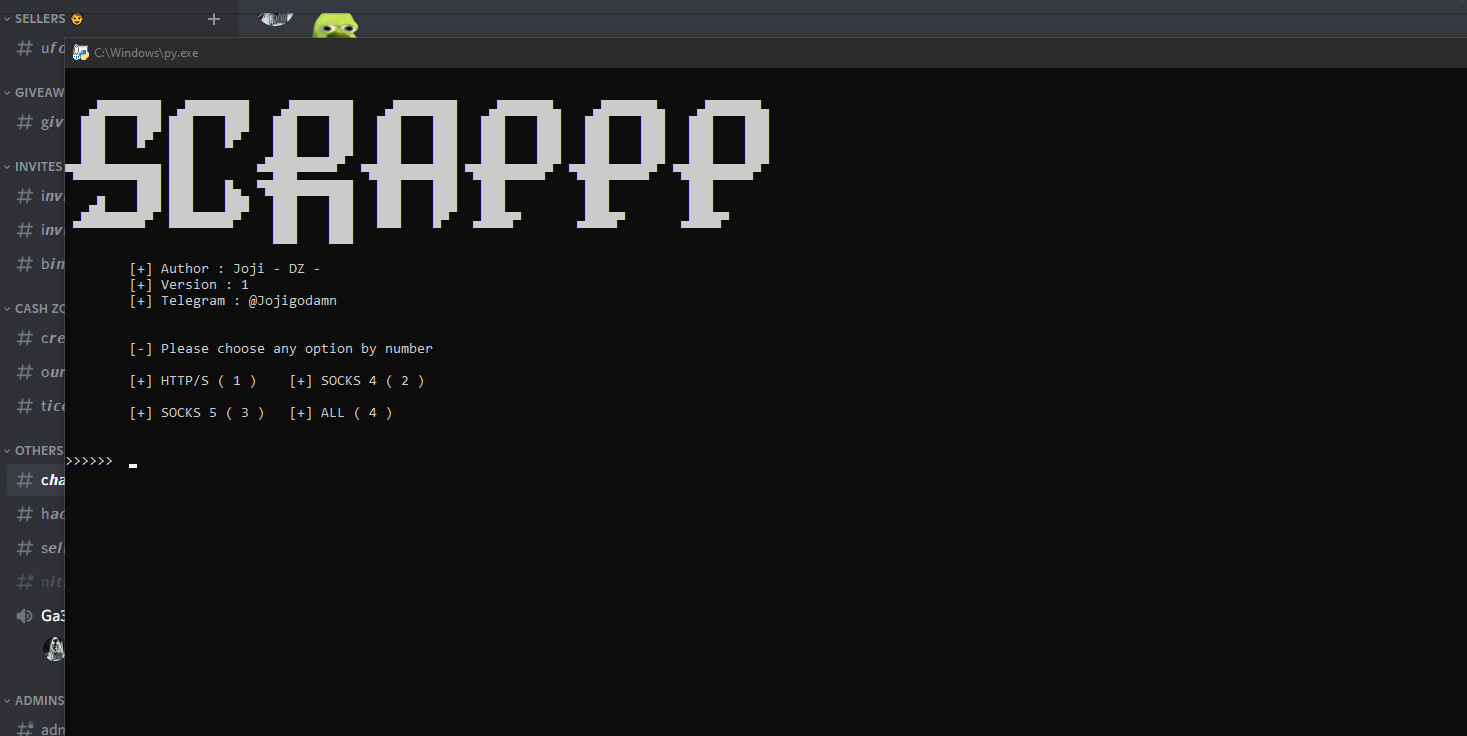

About the script
!!! READ THIS
the script sometimes crash i dont really know why but it STILL WORKING AND YOU CAN USE IT
Contacts
Telegram : @Jojigodamn
Discord : Joji#0082
 2 Nov 16, 2021
2 Nov 16, 2021
 2 Dec 13, 2021
2 Dec 13, 2021
 1 Nov 28, 2021
1 Nov 28, 2021
 1 Jan 6, 2022
1 Jan 6, 2022

 326 Dec 15, 2022
326 Dec 15, 2022
 7 Nov 27, 2022
7 Nov 27, 2022
 299 Dec 15, 2022
299 Dec 15, 2022

 4.8k Jan 4, 2023
4.8k Jan 4, 2023
 87 Jan 6, 2023
87 Jan 6, 2023


 2 Oct 27, 2022
2 Oct 27, 2022
 2k Jan 05, 2023
2k Jan 05, 2023
 457 Jan 05, 2023
457 Jan 05, 2023
 20 Jul 30, 2022
20 Jul 30, 2022
 5 Apr 12, 2022
5 Apr 12, 2022
 1 Jan 28, 2022
1 Jan 28, 2022
 4 Oct 25, 2022
4 Oct 25, 2022
 3 Dec 03, 2022
3 Dec 03, 2022
 15 Dec 06, 2022
15 Dec 06, 2022
 1.1k Jan 06, 2023
1.1k Jan 06, 2023
 1 Nov 29, 2021
1 Nov 29, 2021
 543 Jan 03, 2023
543 Jan 03, 2023
 3 Oct 14, 2022
3 Oct 14, 2022
 6 Aug 26, 2022
6 Aug 26, 2022
 3 Jul 01, 2022
3 Jul 01, 2022
 0 Sep 30, 2021
0 Sep 30, 2021
 5 Oct 29, 2021
5 Oct 29, 2021
 588 Dec 27, 2022
588 Dec 27, 2022
 4 Sep 21, 2022
4 Sep 21, 2022