New to Streaming Scraper
An in-progress web scraping project built with Python, R, and SQL.
The scraped data are movie and TV show information. The goal of the project is to show new to streaming titles that arrive on Netflix monthly with additional details, such as critic and audience ratings.
Current stage: Preparing how to present data with R Markdown.
Testing at: https://charlesdungy.github.io/new-to-streaming-scraper/
Future stage: Complete documentation, comments.
Description
Data are retrieved from two different data sources: What's on Netflix (WON) and Rotten Tomatoes (RT). RT data are cleaned and transformed with Python, while WON data are cleaned and transformed with R.
All data are piped into a MySQL database, then retrieved for presentation in R.
Here is a high-level look at the pipeline:
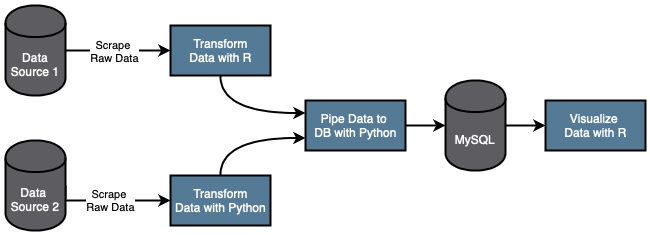
Data Source 1 is WON data. Data Source 2 is RT data.
Main Packages/Tools
Python
R
SQL
Current Directory Tree

License
MIT

 1.8k Mar 18, 2022
1.8k Mar 18, 2022
 12.3k Jan 07, 2023
12.3k Jan 07, 2023
 8 Aug 07, 2022
8 Aug 07, 2022
 3 Sep 09, 2022
3 Sep 09, 2022
 19 Sep 11, 2022
19 Sep 11, 2022
 7 Sep 30, 2022
7 Sep 30, 2022
 2 Nov 22, 2021
2 Nov 22, 2021
 12 Oct 22, 2022
12 Oct 22, 2022
 2 Nov 26, 2021
2 Nov 26, 2021
 35 Aug 29, 2022
35 Aug 29, 2022
 5 Oct 27, 2022
5 Oct 27, 2022
 570 Dec 19, 2022
570 Dec 19, 2022
 56 Nov 27, 2022
56 Nov 27, 2022
 2 Feb 22, 2022
2 Feb 22, 2022
 9.3k Jan 02, 2023
9.3k Jan 02, 2023
 4 Nov 09, 2021
4 Nov 09, 2021
 1 Aug 23, 2022
1 Aug 23, 2022
 1 Jan 16, 2022
1 Jan 16, 2022
 16 Oct 08, 2022
16 Oct 08, 2022
 1 Jan 12, 2022
1 Jan 12, 2022