SummerTime - Text Summarization Toolkit for Non-experts
![]()

A library to help users choose appropriate summarization tools based on their specific tasks or needs. Includes models, evaluation metrics, and datasets.
The library architecture is as follows:
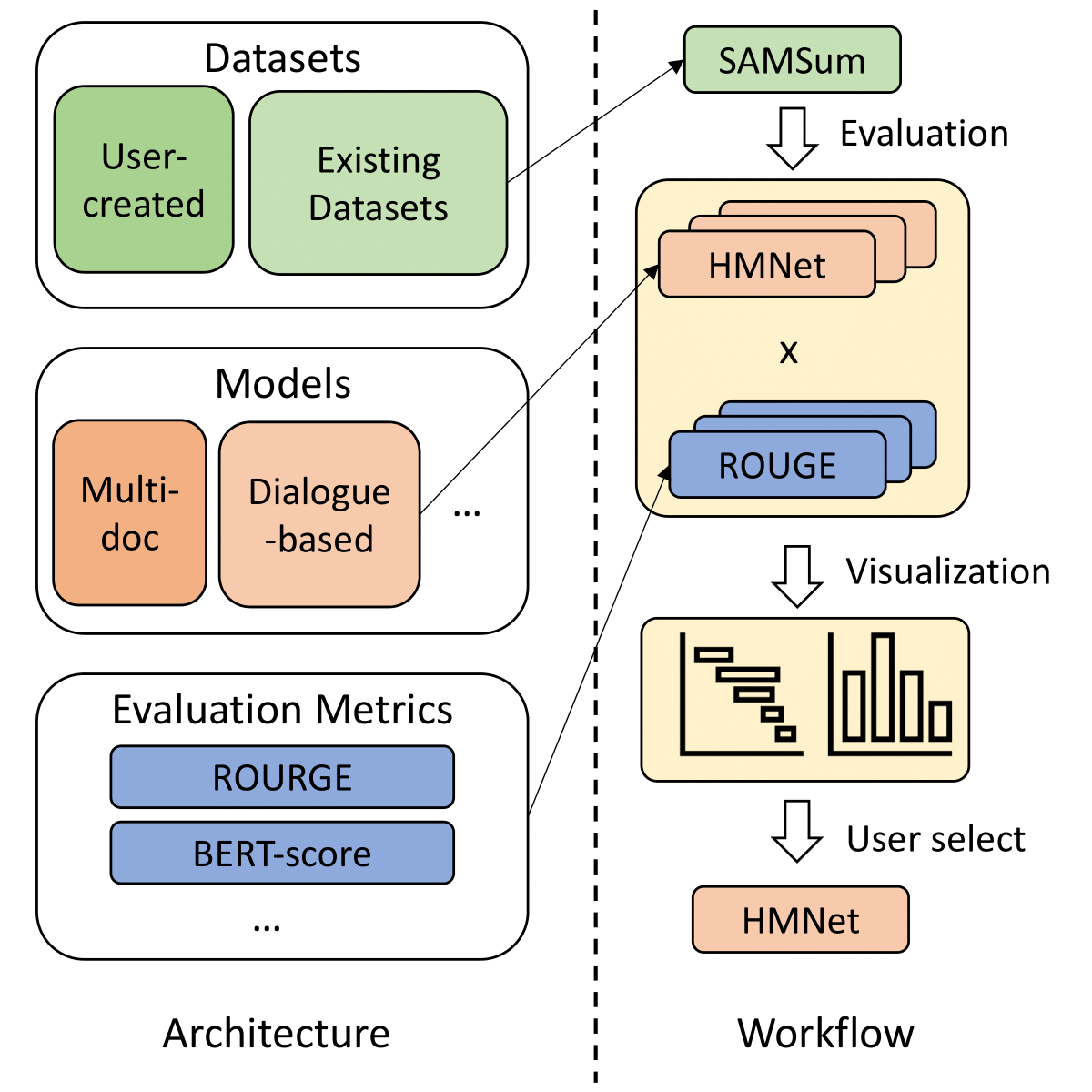
NOTE: SummerTime is in active development, any helpful comments are highly encouraged, please open an issue or reach out to any of the team members.
Installation and setup
Create and activate a new conda environment:
!conda create -n summertime python=3.7
!conda activate summertime
pip dependencies for local demo:
!pip install -r requirements.txt
Setup ROUGE
!export ROUGE_HOME=/usr/local/lib/python3.7/dist-packages/summ_eval/ROUGE-1.5.5/
!pip install -U git+https://github.com/bheinzerling/pyrouge.git
Quick Start
Imports model, initializes default model, and summarizes sample documents.
import model as st_model
model = st_model.summarizer()
documents = [
""" PG&E stated it scheduled the blackouts in response to forecasts for high winds amid dry conditions.
The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were scheduled to be affected
by the shutoffs which were expected to last through at least midday tomorrow."""
]
model.summarize(documents)
# ["California's largest electricity provider has turned off power to hundreds of thousands of customers."]
Also, please run our colab notebook for a more hands-on demo and more examples.
Models
Supported Models
SummerTime supports different models (e.g., TextRank, BART, Longformer) as well as model wrappers for more complex summariztion tasks (e.g., JointModel for multi-doc summarzation, BM25 retrieval for query-based summarization).
| Models | Single-doc | Multi-doc | Dialogue-based | Query-based |
|---|---|---|---|---|
| BartModel |
|
|||
| BM25SummModel |
|
|||
| HMNetModel |
|
|||
| LexRankModel |
|
|||
| LongformerModel |
|
|||
| MultiDocJointModel |
|
|||
| MultiDocSeparateModel |
|
|||
| PegasusModel |
|
|||
| TextRankModel |
|
|||
| TFIDFSummModel |
|
To see all supported models, run:
from model import SUPPORTED_SUMM_MODELS
print(SUPPORTED_SUMM_MODELS)
Import and initialization:
import model as st_model
# To use a default model
default_model = st_model.summarizer()
# Or a specific model
bart_model = st_model.BartModel()
pegasus_model = st_model.PegasusModel()
lexrank_model = st_model.LexRankModel()
textrank_model = st_model.TextRankModel()
Users can easily access documentation to assist with model selection
sample_model.show_capability()
pegasus_model.show_capability()
textrank_model.show_capability()
To use a model for summarization, simply run:
documents = [
""" PG&E stated it scheduled the blackouts in response to forecasts for high winds amid dry conditions.
The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were scheduled to be affected
by the shutoffs which were expected to last through at least midday tomorrow."""
]
sample_model.summarize(documents)
# or
pegasus_model.summarize(documents)
All models can be initialized with the following optional options:
def __init__(self,
trained_domain: str=None,
max_input_length: int=None,
max_output_length: int=None,
):
All models will implement the following methods:
def summarize(self,
corpus: Union[List[str], List[List[str]]],
queries: List[str]=None) -> List[str]:
def show_capability(cls) -> None:
Datasets
Datasets supported
SummerTime supports different summarization datasets across different domains (e.g., CNNDM dataset - news article corpus, Samsum - dialogue corpus, QM-Sum - query-based dialogue corpus, MultiNews - multi-document corpus, ML-sum - multi-lingual corpus, PubMedQa - Medical domain, Arxiv - Science papers domain, among others.
| Dataset | Domain | # Examples | Src. length | Tgt. length | Query | Multi-doc | Dialogue | Multi-lingual |
|---|---|---|---|---|---|---|---|---|
| ArXiv | Scientific articles | 215k | 4.9k | 220 | ||||
| CNN/DM(3.0.0) | News | 300k | 781 | 56 | ||||
| MlsumDataset | Multi-lingual News | 1.5M+ | 632 | 34 |
|
German, Spanish, French, Russian, Turkish | ||
| Multi-News | News | 56k | 2.1k | 263.8 |
|
|||
| SAMSum | Open-domain | 16k | 94 | 20 |
|
|||
| Pubmedqa | Medical | 272k | 244 | 32 |
|
|||
| QMSum | Meetings | 1k | 9.0k | 69.6 |
|
|
||
| ScisummNet | Scientific articles | 1k | 4.7k | 150 | ||||
| SummScreen | TV shows | 26.9k | 6.6k | 337.4 |
|
|||
| XSum | News | 226k | 431 | 23.3 |
To see all supported datasets, run:
import dataset
print(dataset.list_all_dataset())
Dataset Initialization
import dataset
cnn_dataset = dataset.CnndmDataset()
# or
xsum_dataset = dataset.XsumDataset()
# ..etc
Dataset Object
All datasets are implementations of the SummDataset class. Their data splits can be accessed as follows:
dataset = dataset.CnndmDataset()
train_data = dataset.train_set
dev_data = dataset.dev_set
test_data = dataset.test_set
To see the details of the datasets, run:
dataset = dataset.CnndmDataset()
dataset.show_description()
Data instance
The data in all datasets is contained in a SummInstance class object, which has the following properties:
data_instance.source = source # either `List[str]` or `str`, depending on the dataset itself, string joining may needed to fit into specific models.
data_instance.summary = summary # a string summary that serves as ground truth
data_instance.query = query # Optional, applies when a string query is present
print(data_instance) # to print the data instance in its entirety
Loading and using data instances
Data is loaded using a generator to save on space and time
To get a single instance
data_instance = next(cnn_dataset.train_set)
print(data_instance)
To get a slice of the dataset
import itertools
# Get a slice from the train set generator - first 5 instances
train_set = itertools.islice(cnn_dataset.train_set, 5)
corpus = [instance.source for instance in train_set]
print(corpus)
Using the datasets with the models - Examples
import itertools
import dataset
import model
cnn_dataset = dataset.CnndmDataset()
# Get a slice of the train set - first 5 instances
train_set = itertools.islice(cnn_dataset.train_set, 5)
corpus = [instance.source for instance in train_set]
# Example 1 - traditional non-neural model
# LexRank model
lexrank = model.LexRankModel(corpus)
print(lexrank.show_capability())
lexrank_summary = lexrank.summarize(corpus)
print(lexrank_summary)
# Example 2 - A spaCy pipeline for TextRank (another non-neueral extractive summarization model)
# TextRank model
textrank = model.TextRankModel()
print(textrank.show_capability())
textrank_summary = textrank.summarize(corpus)
print(textrank_summary)
# Example 3 - A neural model to handle large texts
# LongFormer Model
longformer = model.LongFormerModel()
longformer.show_capability()
longformer_summary = longformer.summarize(corpus)
print(longformer_summary)
Evaluation
SummerTime supports different evaluation metrics including: BertScore, Bleu, Meteor, Rouge, RougeWe
To print all supported metrics:
from evaluation import SUPPORTED_EVALUATION_METRICS
print(SUPPORTED_EVALUATION_METRICS)
Import and initialization:
import evaluation as st_eval
bert_eval = st_eval.bertscore()
bleu_eval = st_eval.bleu_eval()
meteor_eval = st_eval.bleu_eval()
rouge_eval = st_eval.rouge()
rougewe_eval = st_eval.rougewe()
Evaluation Class
All evaluation metrics can be initialized with the following optional arguments:
def __init__(self, metric_name):
All evaluation metric objects implement the following methods:
def evaluate(self, model, data):
def get_dict(self, keys):
Using evaluation metrics
Get sample summary data
from evaluation.base_metric import SummMetric
from evaluation import Rouge, RougeWe, BertScore
import itertools
# Evaluates model on subset of cnn_dailymail
# Get a slice of the train set - first 5 instances
train_set = itertools.islice(cnn_dataset.train_set, 5)
corpus = [instance for instance in train_set]
print(corpus)
articles = [instance.source for instance in corpus]
summaries = sample_model.summarize(articles)
targets = [instance.summary for instance in corpus]
Evaluate the data on different metrics
from evaluation import BertScore, Rouge, RougeWe,
# Calculate BertScore
bert_metric = BertScore()
bert_score = bert_metric.evaluate(summaries, targets)
print(bert_score)
# Calculate Rouge
rouge_metric = Rouge()
rouge_score = rouge_metric.evaluate(summaries, targets)
print(rouge_score)
# Calculate RougeWe
rougewe_metric = RougeWe()
rougwe_score = rougewe_metric.evaluate(summaries, targets)
print(rougewe_score)
To contribute
Pull requests
Create a pull request and name it [your_gh_username]/[your_branch_name]. If needed, resolve your own branch's merge conflicts with main. Do not push directly to main.
Code formatting
If you haven't already, install black and flake8:
pip install black
pip install flake8
Before pushing commits or merging branches, run the following commands from the project root. Note that black will write to files, and that you should add and commit changes made by black before pushing:
black .
flake8 .
Or if you would like to lint specific files:
black path/to/specific/file.py
flake8 path/to/specific/file.py
Ensure that black does not reformat any files and that flake8 does not print any errors. If you would like to override or ignore any of the preferences or practices enforced by black or flake8, please leave a comment in your PR for any lines of code that generate warning or error logs. Do not directly edit config files such as setup.cfg.
See the black docs and flake8 docs for documentation on installation, ignoring files/lines, and advanced usage. In addition, the following may be useful:
black [file.py] --diffto preview changes as diffs instead of directly making changesblack [file.py] --checkto preview changes with status codes instead of directly making changesgit diff -u | flake8 --diffto only run flake8 on working branch changes
Note that our CI test suite will include invoking black --check . and flake8 --count . on all non-unittest and non-setup Python files, and zero error-level output is required for all tests to pass.
Tests
Our continuous integration system is provided through Github actions. When any pull request is created or updated or whenever main is updated, the repository's unit tests will be run as build jobs on tangra for that pull request. Build jobs will either pass or fail within a few minutes, and build statuses and logs are visible under Actions. Please ensure that the most recent commit in pull requests passes all checks (i.e. all steps in all jobs run to completion) before merging, or request a review. To skip a build on any particular commit, append [skip ci] to the commit message. Note that PRs with the substring /no-ci/ anywhere in the branch name will not be included in CI.
Citation
This repository is built by the LILY Lab at Yale University, led by Prof. Dragomir Radev. The main contributors are Ansong Ni, Zhangir Azerbayev, Troy Feng, Murori Mutuma and Yusen Zhang (Penn State).
If you use SummerTime in your work, consider citing:
@article{ni2021summertime,
title={SummerTime: Text Summarization Toolkit for Non-experts},
author={Ansong Ni and Zhangir Azerbayev and Mutethia Mutuma and Troy Feng and Yusen Zhang and Tao Yu and Ahmed Hassan Awadallah and Dragomir Radev},
journal={arXiv preprint arXiv:2108.12738},
year={2021}
}
For comments and question, please open an issue.










 4.5k Jan 03, 2023
4.5k Jan 03, 2023
 431 Dec 19, 2022
431 Dec 19, 2022
 197 Dec 25, 2022
197 Dec 25, 2022
 1.5k Dec 26, 2022
1.5k Dec 26, 2022
 1.4k Dec 30, 2022
1.4k Dec 30, 2022
 829 Jan 07, 2023
829 Jan 07, 2023
 37 Dec 14, 2022
37 Dec 14, 2022
 363 Dec 30, 2022
363 Dec 30, 2022
 255 Dec 27, 2022
255 Dec 27, 2022
 1 Feb 07, 2022
1 Feb 07, 2022
 7 Apr 08, 2022
7 Apr 08, 2022
 7.1k Jan 01, 2023
7.1k Jan 01, 2023
 39 Aug 03, 2021
39 Aug 03, 2021
 1 Jan 11, 2022
1 Jan 11, 2022
 1 Jun 14, 2022
1 Jun 14, 2022
 21 Aug 12, 2022
21 Aug 12, 2022
 2 Dec 02, 2021
2 Dec 02, 2021
 1 Feb 08, 2022
1 Feb 08, 2022
 409 Jan 06, 2023
409 Jan 06, 2023
 47 Dec 20, 2022
47 Dec 20, 2022