
opendrift
![]()
OpenDrift is a software for modeling the trajectories and fate of objects or substances drifting in the ocean, or even in the atmosphere.
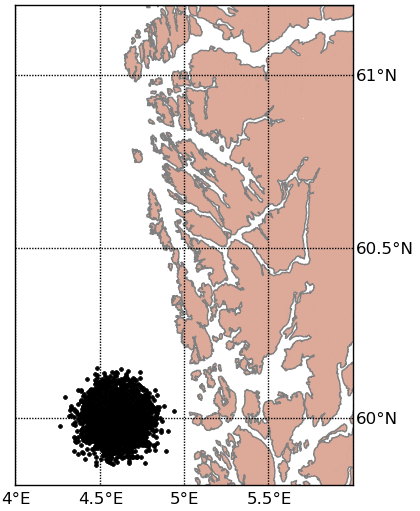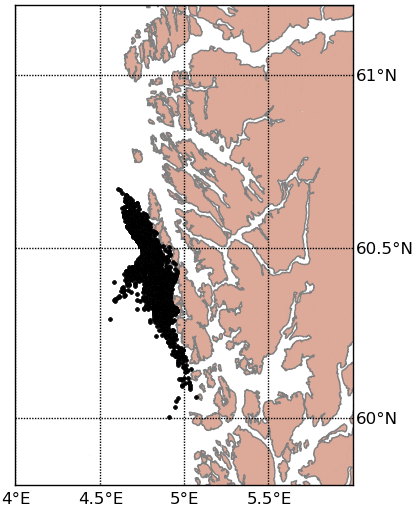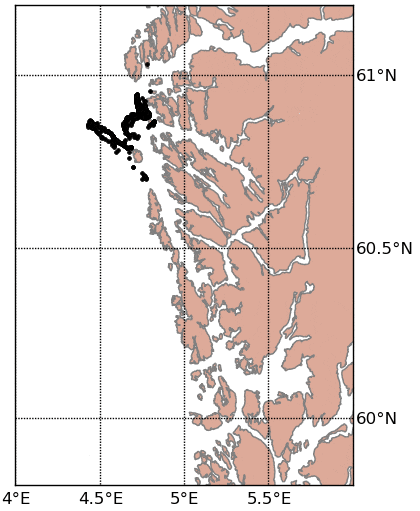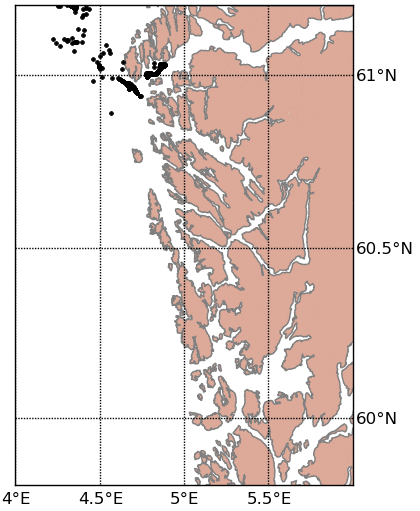
Documentation and installation instructions can be found here.
Development
We have a slack-organization open for anyone to join.

 21 Aug 30, 2022
21 Aug 30, 2022
 42 Sep 12, 2022
42 Sep 12, 2022
 1 Oct 20, 2021
1 Oct 20, 2021
 8 Oct 18, 2022
8 Oct 18, 2022
 14 Jan 03, 2023
14 Jan 03, 2023
 5 Jan 03, 2023
5 Jan 03, 2023
 14 Aug 30, 2022
14 Aug 30, 2022
 23 Dec 08, 2022
23 Dec 08, 2022
 1 Jan 27, 2022
1 Jan 27, 2022
 110 Jan 06, 2023
110 Jan 06, 2023
 1 Jan 23, 2022
1 Jan 23, 2022
 13 Dec 15, 2022
13 Dec 15, 2022
 210 Jan 02, 2023
210 Jan 02, 2023
 5 Sep 06, 2021
5 Sep 06, 2021
 3.6k Jan 09, 2023
3.6k Jan 09, 2023
 10 May 10, 2022
10 May 10, 2022
 6 Aug 10, 2021
6 Aug 10, 2021
 411 Dec 27, 2022
411 Dec 27, 2022
 1 Dec 09, 2021
1 Dec 09, 2021
 1 Oct 31, 2021
1 Oct 31, 2021