当前位置:网站首页>Does volatile rely on the MESI protocol to solve the visibility problem? (next)
Does volatile rely on the MESI protocol to solve the visibility problem? (next)
2022-07-26 09:14:00 【new hilbert()】
volatile by MESI Protocols address visibility issues ?( On )
Processor resolution MESI The protocol brings the problem of write request blocking :
(1) introduce store buffer
Turn synchronous waiting into asynchronous , Separate write operations into a store buffer, The data read in this way is completely composed of cache obtain . and store buffer Only responsible for writing data . CPU You can first write the data to Store Buffer, And then go on with other things . Wait until you get another CPU Sending a Cache Line(Read Response), And then the data is transferred from Store Buffer Move to Cache Line. The structure is as follows :
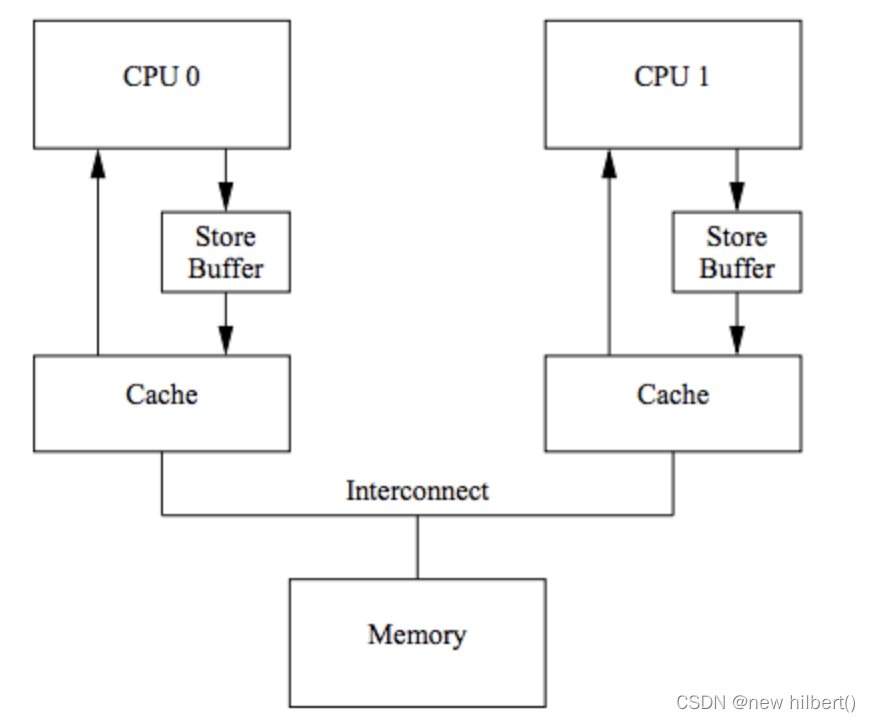
Then add the Store Buffer after , Will introduce another problem :cache The data is inaccurate , because store buffer The data hasn't been synchronized to cache,store buffer Only responsible for writing , Access from cache Take it out
a = 2;
b = a + 1 ;
In the initial state , hypothesis a,b Values are 0, also a There is CPU1 Of Cache Line in (Shared state ), The following sequence of operations may occur :
- CPU0 To write A, issue Read Invalidate news , And will a=1 write in Store Buffer
- CPU1 received Read Invalid, return Read Response( contain a=0 Of Cache Line) and Invalid Ack
- CPU0 received Read Response, to update Cache Line(a=0)
- CPU0 Start execution b = a + 1, from Cache Line Load in a, obtain a=0 , And then at this point b The value of is 1, As we predicted b =2+1 It's a violation .
- CPU0 Received all the invalid ack, take Store Buffer Medium a=1 Applied to the Cache Line
Cause : The same CPU Existence is right a Two copies of , One in Cache, One in Store Buffer, The former is used to read , The latter is used to write , Thus, in the case of single thread CPU Execution sequence and program sequence (Program Order) atypism ( Looks like it was executed first b=a+1, Re execution a=1).
Science Popularization :
as-if-serial semantics : No matter how rearranged ( Compiler and processor to improve parallelism ),( Single thread ) The execution result of the program cannot be changed , Operations with data dependencies are not reordered , compiler ,runtime And processors must comply with as-if-serial semantics .
- really · Reorder : compiler , The underlying hardware cpu etc. ( Instruction level ), Out of “ Optimize ” Purpose , Reorder instructions according to certain rules .
- false · Reorder : because store buffer Cache synchronization cache
The question of order , It looks like the instructions have been reordered . But semantically, it is not allowed to be reordered , Because there is a correlation .
Store Forwarding technology :
CPU Can be directly from Store Buffer Load data in , That is, support will CPU Deposit in Store Buffer Data transfer (forwarding) For subsequent loading operations , Without going through Cache.( To solve the same cpu Inside cache and store buffer The values are inconsistent )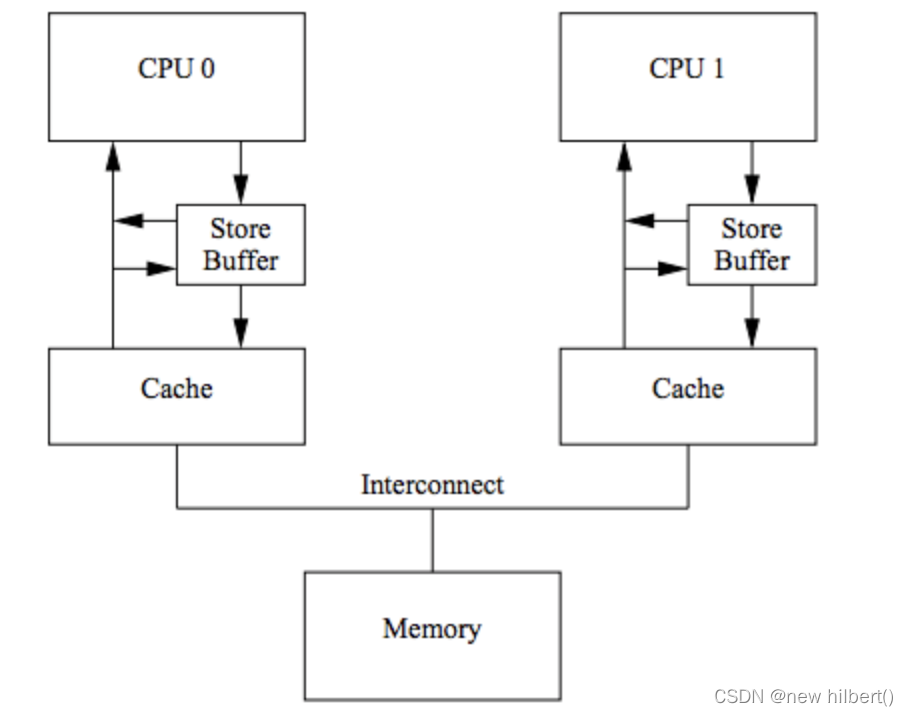
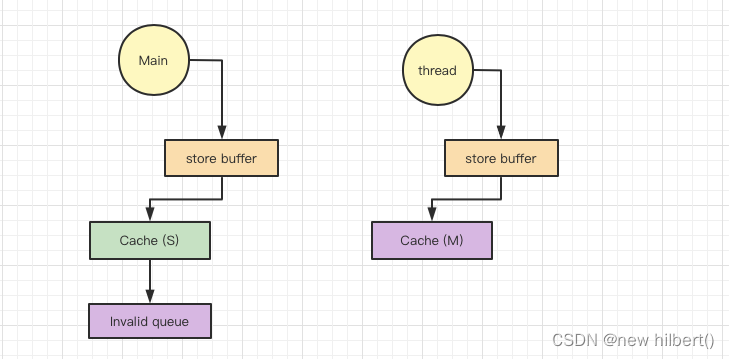
(2)Invalid Queue: The response will be synchronized Invalid ack Become asynchronous
Invalid Ack The main reason for the time-consuming is CPU First put the corresponding Cache Line Set as Invalid And then back Invalid Ack, A very busy CPU May cause other CPU Waiting for it to come back Invalid Ack.
The solution is to change synchronization into asynchrony : CPU There's no need to deal with Cache Line Then go back to Invalid Ack, Instead, you can put Invalid Put the message on a request queue Invalid Queue, And then back to Invalid Ack.CPU It can be processed later Invalid Queue The messages in the , Greatly reduce Invalid Ack response time .
At this time CPU Cache Structure diagram is as follows :
- For all received Invalidate request ,Invalidate Acknowlege The message must be sent immediately Invalidate
- Not really executing , But in a special queue , Only when it's convenient to do .
added lnvalid queue after , Will introduce another problem :cache The data is inaccurate , because lnvalid queue The data hasn't been synchronized to cache, from cache The data read out is still inaccurate .
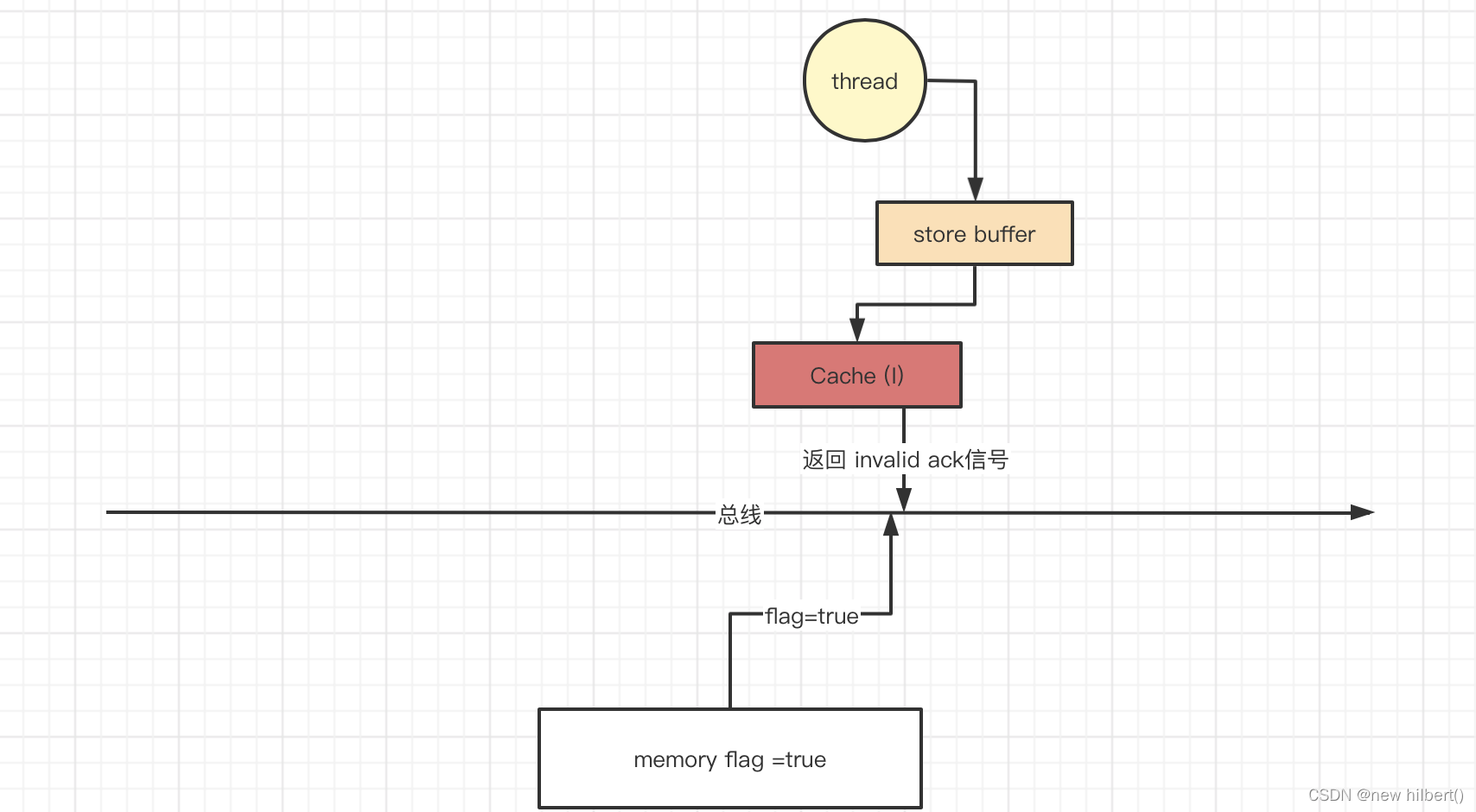
Back to our initial question , In the improved cpu Cache model , Why? thread I can't see flag Modification of variables ?
Because of the delay ,store buffer Asynchronous waiting other cpu Of valid ack, Only then cache become exclusive And change it to modify.
- main Thread issue invalid The signal , wait for thread Signal response invalid ack The signal ,thread received invalid
The signal , hold cache Set to Invalid. Then return Invalid ack The signal
- But actually we main The program hasn't waited invalid ack It's over , It has not been modified to memory Value ,thread because cache Invalid Only from memory Get old value
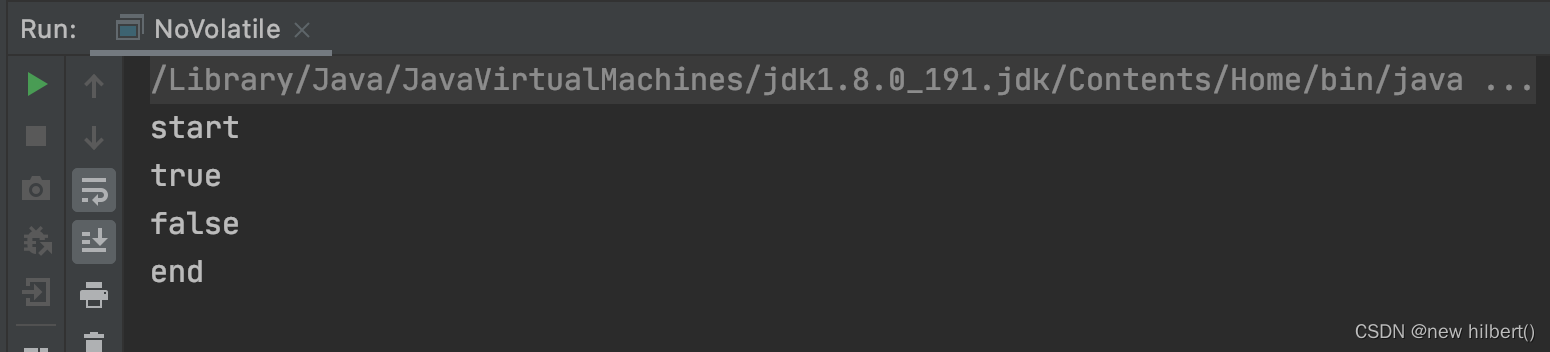
public class NoVolatile {
private boolean flag = true;
public void test() {
System.out.println("start");
while (flag) {
}
System.out.println("end");
}
public static void main(String[] args) {
NoVolatile noVolatile = new NoVolatile();
new Thread(noVolatile::test).start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
noVolatile.flag = false;
}
}
// Execution results :
start
So how can I see it thread Thread does not pass validate You can get the value in the case of ? take main Put it longer , You can get this effect .
public class NoVolatile {
private boolean flag = true;
public void test() {
System.out.println("start");
System.out.println(flag);
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
}
System.out.println(flag);
System.out.println("end");
}
public static void main(String[] args) {
NoVolatile noVolatile = new NoVolatile();
new Thread(noVolatile::test).start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
noVolatile.flag = false;
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
}
}
}
In order to solve the problem of processor waiting ( Write request blocking ) problem , Write buffer and invalid queue are introduced , It also leads to reordering and visibility problems
Existing problems :
a、 visibility :
- Like a processor 1 Write to your own write buffer , processor 2 Go to... Through the bus read The data read is still old data ;
- Like a processor 1 Accepted a Of invalid news , The message was written to Invalid queue , But it didn't deal with . Will cause the processor to 1 Read a The news of , Will read a value that should not be valid
b、 Orderliness :
- store load rearrangement : processor 1 The write operation of is written to the write buffer to the processor 2 invisible , processor 2 After reading a piece of data, I feel load before store After ;
- store store rearrangement : processor 1 The first write operation found data is s state , Write to write buffer ; The second write operation is m The status can be modified directly , That is, the order of the two write operations is reversed ;
The essential question :cp1 store buffer To cp2 cache There is a large delay problem ,Invalid queue There is a delay problem when data is not synchronized in time , Delays cannot be tolerated in the case of cross thread dependencies .
Solution : For the above memory inconsistency , It's hard to optimize from the hardware level , because CPU It is impossible to know which values are associated , So hardware engineers provide something called memory barrier . The barrier is set by prohibiting rearrangement , Become a synchronization effect , This will solve the problem , Visibility and rearrangement issues .
Write barriers :
Write barriers Store Memory Barrier(a.k.a. ST, SMB, smp_wmb) It's a message that tells the processor before executing the next instruction , All applications are already in storage cache (store buffer) Stored instructions in .
cpu Provides a write barrier (write memory barrier) Instructions ,Linux The operating system encapsulates the write barrier instruction into smp_wmb() function ,cpu perform smp_mb() The idea is , Will first put the current store buffer Swipe the data in to cache after , Then execute the... After the barrier “ Write operation ”, There are two ways to realize this idea : One is to simply brush store buffer, But if it's remote cache line No return , You need to wait , Second, the current store buffer Marking entries in , Then put the... Behind the barrier “ Write operation ” Also wrote store buffer in ,cpu Keep doing other things , When all the marked items are brushed to cache line, Then brush the following items .
Reading barrier :
Reading barrier Load Memory Barrier (a.k.a. LD, RMB, smp_rmb) It's a message that tells the processor before performing any loading , First apply all that are already in the invalidation queue Invalid queue Instructions for failed operations in .
You can make... Through the reading barrier CPU Mark current Invalid Queue All entries in , All subsequent loading operations must wait Invalid Queue Execute after the processing of the items marked in
because cpu Maybe just focus on , Write or read . majority CPU The architecture divides memory barriers into read barriers (Read Memory Barrier) And writing barriers (WriteMemory Barrier)
- Reading barrier lfence : Any read operation before the read barrier will be completed before the read operation after the read barrier
- Write barriers sfence : Any write operation before the write barrier will be completed before the write operation after the write barrier
- Full screen barrier mfence : It also includes the functions of read barrier and write barrier
Memory barrier can solve the problems of rearrangement and visibility . that volatile How did it work out ? Where to implement the memory barrier ?
volatile static int a = 0;
//javap After decompilation, we get ACC_VOLATILE keyword
static volatile int a;
descriptor: I
flags: ACC_STATIC, ACC_VOLATILE
stay accessFlags.hpp In file
//ACC_VOLATILE keyword
bool is_volatile () const {
return (_flags & JVM_ACC_VOLATILE ) != 0; }
stay bytecodeInterpreter.cpp In file
- Volatile Write operation source code
if (cache->is_volatile()) {
if (tos_type == itos) {
obj->release_int_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == atos) {
VERIFY_OOP(STACK_OBJECT(-1));
obj->release_obj_field_put(field_offset, STACK_OBJECT(-1));
OrderAccess::release_store(&BYTE_MAP_BASE[(uintptr_t)obj >> CardTableModRefBS::card_shift], 0);
} else if (tos_type == btos) {
obj->release_byte_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == ltos) {
obj->release_long_field_put(field_offset, STACK_LONG(-1));
} else if (tos_type == ctos) {
obj->release_char_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == stos) {
obj->release_short_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == ftos) {
obj->release_float_field_put(field_offset, STACK_FLOAT(-1));
} else {
obj->release_double_field_put(field_offset, STACK_DOUBLE(-1));
}
OrderAccess::storeload();
}
Two key actions :
- call release_int_field_put function , Perform the assignment action
- perform OrderAccess::storeload()
inline void oopDesc::release_int_field_put(int offset, jint contents) {
OrderAccess::release_store(int_field_addr(offset), contents);
}
inline void OrderAccess::release_store(volatile jint* p, jint v) {
*p = v;
}
- Volatile Read operations
if (cache->is_volatile()) {
if (tos_type == atos) {
VERIFY_OOP(obj->obj_field_acquire(field_offset));
SET_STACK_OBJECT(obj->obj_field_acquire(field_offset), -1);
} else if (tos_type == itos) {
SET_STACK_INT(obj->int_field_acquire(field_offset), -1);
} else if (tos_type == ltos) {
SET_STACK_LONG(obj->long_field_acquire(field_offset), 0);
MORE_STACK(1);
} else if (tos_type == btos) {
SET_STACK_INT(obj->byte_field_acquire(field_offset), -1);
} else if (tos_type == ctos) {
SET_STACK_INT(obj->char_field_acquire(field_offset), -1);
} else if (tos_type == stos) {
SET_STACK_INT(obj->short_field_acquire(field_offset), -1);
} else if (tos_type == ftos) {
SET_STACK_FLOAT(obj->float_field_acquire(field_offset), -1);
} else {
SET_STACK_DOUBLE(obj->double_field_acquire(field_offset), 0);
MORE_STACK(1);
}
}
Key action :
JVM The defined memory barriers have these :

inline void OrderAccess::loadload() {
acquire(); }
inline void OrderAccess::storestore() {
release(); }
inline void OrderAccess::loadstore() {
acquire(); }
inline void OrderAccess::storeload() {
fence(); }
inline void OrderAccess::acquire() {
volatile intptr_t local_dummy;
#ifdef AMD64
__asm__ volatile ("movq 0(%%rsp), %0" : "=r" (local_dummy) : : "memory");
#else
__asm__ volatile ("movl 0(%%esp),%0" : "=r" (local_dummy) : : "memory");
#endif // AMD64
}
inline void OrderAccess::release() {
// Avoid hitting the same cache-line from
// different threads.
volatile jint local_dummy = 0;
}
inline void OrderAccess::fence() {
// Judge whether it is multi-core
if (os::is_MP()) {
// always use locked addl since mfence is sometimes expensive
#ifdef AMD64
__asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory");
#else
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
#endif
}
}
GCC Embedded assembly language
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
__asm__ ( Assembly statement template : Output part : Input part : Destruction description part )
Destroy descriptor : Used to inform the compiler which registers or memory we use , A string that consists of a comma , Each string describes a situation , Usually register name ;, In addition, there is memory “memory” and “cc”. We call it as :“%eax”、“%ebx”、“%ecx” Etc. are register destruction descriptors ; call “memory” Is a memory descriptor , It means to modify memory;“cc” Indicates that the assembler code has modified the flag register ’
memory: Destroy descriptor , tell GCC Memory has been modified ,GCC Will ensure that before this inline assembly , If the contents of a memory are loaded into a register , So after this inline assembly , If you need to use the contents of this memory ; Just before this instruction , Insert the necessary instructions to write the variable value in the register back to main memory first , When the instruction is read later, it will also directly go to this memory to re read , Instead of using a copy stored in a register .(CPP It will be optimized after being converted into assembly language )
volatile yes C++ One of the keywords of : Encountered the variable declared by this keyword , The compiler no longer optimizes the code that accesses the variable , It can provide stable access to special addresses .
Declaration syntax :int volatile vInt;
When required to use volatile When declaring the value of a variable , The system always rereads data from its memory , Even if its previous instruction just read data from there . And the read data is immediately saved
stay x86 In the processor , Will ignore the first three , Only care about storeload( Read write barrier )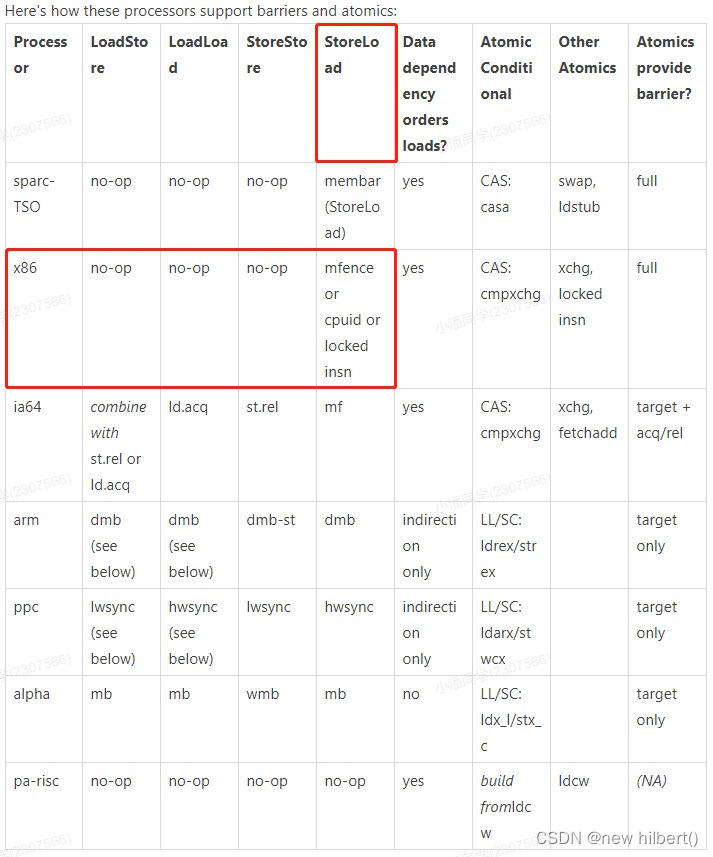
about storeload( Read write barrier ), What I came to was mfence Method ,os::is_MP() Used to determine whether it is a multi-core architecture ,#ifdef AMD64 Used to determine if it is 64 Bit processor , Then a sentence code will be added :lock; addl $0,0(%%rsp), This is the use of lock To achieve the effect of memory barrier
What then? Lock Keywords can achieve the effect of memory barrier ?
Lock Prefix ,Lock It's not a memory barrier , But it can do something like a memory barrier .Lock Would be right CPU Bus and cache locking , It can be understood as CPU An instruction level lock . It can be followed by ADD, ADC, AND, BTC, BTR, BTS, CMPXCHG, CMPXCH8B, DEC, INC, NEG, NOT, OR, SBB, SUB, XOR, XADD, and XCHG Such as instruction
- Bus lock
LOCK# Signal is the bus lock we often talk about , Processor usage LOCK# The signal reaches the lock bus , To solve the atomic problem , When a processor outputs to the bus LOCK# Signal time , Requests from other processors will be blocked , At this point, the processor monopolizes the shared memory
The bus lock is too wide , Lead to CPU Utilization has fallen sharply , Because use LOCK# It's a CPU Communication with memory is locked , This makes the lock period , Other processors cannot manipulate the data of their memory address , So the cost of bus lock is relatively large
- Buffer lock ( Lock cache lines , other CPU Can't cache line change )
If the memory area accessed is already cached in the processor's cache line ,P6 The system and subsequent series of processors will not declare LOCK# The signal , It will be right CPU To lock the cache rows in the cache , During locking , Other CPU This data cannot be cached at the same time , After the modification , The atomicity of modification is guaranteed by cache consistency protocol , This operation is called “ Buffer lock ”
- When to use the bus lock (LOCK#)
When the operation data cannot be cached inside the processor , Or when the operation's data spans multiple cache rows , You can also use a bus lock
Because from P6 Series processors only have cache locks at the beginning , So cache locking is not supported for earlier processors , You can also use a bus lock
- LOCK# Function summary
- Lock bus , Other CPU Read and write requests to memory are blocked , Until the lock is released , Because locking the bus costs a lot , Later processors used lock cache instead of lock bus , When the cache lock cannot be used, the bus lock will be degraded
- lock During the write operation, the modified data will be written back to the main memory , At the same time, cache consistency protocol is used to make other CPU The associated cache line is invalid
- Bus lock 、 Cache locks guarantee atomicity , Cache consistency protocol can ensure visibility
X86 Version of Storeload Is used for volatile Write operations for , So how to do it volatile The value after writing , It was observed that ?
if (cache->is_volatile()) {
if (tos_type == itos) {
obj->release_int_field_put(field_offset, STACK_INT(-1));
}
......
OrderAccess::storeload();
}
inline void OrderAccess::storeload() {
fence(); }
inline void OrderAccess::fence() {
// Judge whether it is multi-core
if (os::is_MP()) {
// always use locked addl since mfence is sometimes expensive
#ifdef AMD64
__asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory");
#else
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
#endif
}
}
addl $0,0(%%esp): Indicates that the value will be 0 Add to esp In the register , The register points to the memory unit at the top of the stack . Add a 0,esp The value of the register remains unchanged . It doesn't mean much in itself .
memory: Destroy descriptor , tell GCC Memory has been modified ,GCC Will ensure that before this inline assembly , If the contents of a memory are loaded into a register , So after this inline assembly , If you need to use the contents of this memory ; Just before this instruction , Insert the necessary instructions to write the variable value in the register back to main memory first , When the instruction is read later, it will also directly go to this memory to re read , Instead of using a copy stored in a register .( Will force a brush back to memory , And read the value of memory )

The steps to ensure visibility are as follows :
- release_int_field_put modify cache, bring cache become modified state
- lock# keyword Lock the bus
- memory Keywords make the modified Cache I have to brush it back memory, Just occupied the bus , So I brushed it back first
- memory Keywords make other cpu Of Cache Invalid From again memory obtain , But the bus is locked , Can only wait to deposit , To get
volatile Is atomicity guaranteed ?
public class AtomicVolatile {
public static volatile int a = 0;
public static void main(String[] args) throws Exception {
Thread t1 = new Thread(() -> {
for (int i = 0; i < 10000; i++) {
a++;
}
System.out.println("t1 performed ");
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 10000; i++) {
a++;
}
System.out.println("t2 performed ");
});
t1.start();t2.start();
t1.join(); t2.join();;
System.out.println("a Value :" + a);
}
}
// Execution results
t2 performed
t1 performed
a Value :13585
Why? volatile Modified variables have no guarantee of atomicity ? The result of the final addition is not 20000
Atomicity : One or more operations , Either all of them are executed and the execution process will not be interrupted by any factors , Or they don't do it
JVM 8 It's an atomic operation :
- read( Read ): For main memory , It transfers the variable value from main memory to the working memory of the thread
- load( load ): Working memory , It is the read The value of the operation is placed in a copy of the variable in working memory ;
- use( Use ): Working memory , It passes values from working memory to the execution engine
- assign( assignment ): Working memory , It assigns values from the execution engine to variables in working memory
- store( Storage ): Working memory , It transfers a variable from working memory to main memory
- write( write in ): For main memory , It is the store Transfer values to variables in main memory .
- unlock( Unlock ): For main memory , It releases a locked variable , The released variables can only be locked by other threads
- lock( lock ): For main memory , It marks a variable as a thread exclusive state ;
I++ Actually It's three movements
- obtain I Value
- take I The value of the to +1 obtain x
- take x Assigned to I
because I++ This statement can be broken down into 3 An action to perform ,I++ It's a non atomic action , There is no guarantee that we can complete . So there are the following situations 
Use synchronized Keywords to guarantee atomicity
public class AtomicVolatile {
public static volatile Integer a = 0;
public static Integer b = 0;
public static void main(String[] args) throws Exception {
Thread t1 = new Thread(() -> {
// Don't take it. a To be a lock object ,Integer Greater than 127 It's a new object , Step on the pit , Remember
synchronized (b) {
for (int i = 0; i < 10000; i++) {
a++;
}
}
System.out.println("t1 performed a:" + a);
});
Thread t2 = new Thread(() -> {
synchronized (b) {
for (int i = 0; i < 10000; i++) {
a++;
}
}
System.out.println("t2 performed a:" + a);
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("a Value :" + a);
}
}
// Execution results
t1 performed a:20000
t2 performed a:20000
a Value :20000

summary :
volatile It can ensure visibility and sequencing ( The way through the memory barrier )
volatile There is no guarantee of atomicity
Extracurricular development
Why? Multithreading creation new You need to add... When you create an instance Volatile keyword ?
public class SingletonFactory {
private volatile static SingletonFactory myInstance;
public static SingletonFactory getMyInstance() {
if (myInstance == null) {
synchronized (SingletonFactory.class) {
if (myInstance == null) {
myInstance = new SingletonFactory();
}
}
}
return myInstance;
}
public static void main(String[] args) {
SingletonFactory.getMyInstance();
}
}
synchronized Thread visibility has been guaranteed , Why do we still need volatile To modify SingletonFactory myInstance Well ?
myInstance = new SingletonFactory(); Decompile to get Initializing an object is divided into three steps
- new Allocate a piece of memory space ( When the class is loaded, it is determined how much space needs to be allocated )
- invokespecial Object initialization ( Construction method )
- astore_2 myInstance Reference to the memory address of the object
In the case of a single thread , Not necessarily according to 123 In sequence , May be 132, Because there is CPU Reorder the instructions of
In the case of multithreading , Threads 1 Execution time , If an instruction reordering occurs ,1,3 After the execution ,myInstance The object pointed to is not empty , The thread 2 Execution time , It's right up to if (myInstance == null), Then it won't be for At present this Object initialization variable SingletonFactory myInstance 了 , Does not meet the expectations of the program
add volatile after , Disable instruction reordering , There won't be any of the above problems
边栏推荐
猜你喜欢

Babbitt | metauniverse daily must read: does the future of metauniverse belong to large technology companies or to the decentralized Web3 world
![[eslint] Failed to load parser ‘@typescript-eslint/parser‘ declared in ‘package. json » eslint-confi](/img/39/135d29dae23b55497728233f31aa6a.png)
[eslint] Failed to load parser ‘@typescript-eslint/parser‘ declared in ‘package. json » eslint-confi

redis原理和使用-基本特性

原根与NTT 五千字详解

Study notes of automatic control principle -- correction and synthesis of automatic control system

CF1481C Fence Painting

redis原理和使用-安装和分布式配置

2022年上海市安全员C证考试试题及模拟考试

Advanced mathematics | Takeshi's "classic series" daily question train of thought and summary of error prone points

CSDN Top1 "how does a Virgo procedural ape" become a blogger with millions of fans through writing?
随机推荐
Processing of inconsistent week values obtained by PHP and MySQL
Sending and receiving of C serialport
Nuxt - Project packaging deployment and online to server process (SSR server rendering)
Announcement | FISCO bcos v3.0-rc4 is released, and the new Max version can support massive transactions on the chain
深度学习常用激活函数总结
Form form
JS closure: binding of functions to their lexical environment
Study notes of automatic control principle -- correction and synthesis of automatic control system
Innovus卡住,提示X Error:
2B和2C
Zipkin安装和使用
Object type collections are de duplicated according to the value of an attribute
网络安全漫山遍野的高大上名词之后的攻防策略本质
Elastic APM安装和使用
Advanced mathematics | Takeshi's "classic series" daily question train of thought and summary of error prone points
对标注文件夹进行清洗
Day06 homework - skill question 7
How to quickly learn a programming language
(1) CTS tradefed test framework environment construction
Center an element horizontally and vertically