当前位置:网站首页>Spark入门到精通-番外篇(Standaone集群的运维和简单操作)
Spark入门到精通-番外篇(Standaone集群的运维和简单操作)
2022-07-17 05:24:00 【顶尖高手养成计划】
安装包下载

spark集群的master和work单独启动
要单独启动那么必须先启动master,然后在启动work
tar -zxvf spark-3.0.0-bin-hadoop2.7.tgz配置环境变量
sudo vi /etc/profile.d/my_en.sh#SPARK_HOME
export SPARK_HOME=/home/atguigu/spark-3.0.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/binsource /etc/profile.d/my_en.sh先在一台机器上面启动master
cd sbin./start-master.sh启动脚本可选参数
-h HOST,--host HOST 在哪台机器上启动,默认都是本机
-p PORT,--port PORT 在机器上启动后,使用哪个端口对外提供服务,master默认是7077,worker默认是随机的
--webui-port PORT web ui的端口,master默认是8080,worker默认是8081
-c CORES,--cores CORES 仅限于worker,总共能让spark application使用多少个cpu core,.默认是当前机器上所有的cpu core
-m MEM,--memory MEM 仅限于worker,总共能让spark application使用多少内存,是100M或者1G这样的格式
-d DIR,--work-dir DIR 仅限于worker,工作目录,默认是SPARK_HOME/work目录
--properties-file FILE master和worker加载配置文件的地址,默认是SPARK_HOME/conf/spark-default.conf启动以后查看日志的地方(根据自己的机器来)就是在logs目录里面
/home/atguigu/spark-3.0.0-bin-hadoop2.7/logs/spark-atguigu-org.apache.spark.deploy.master.Master-1-hadoop102.out
根据日志知道返回http:hadoop102:8081进入web界面

如果想关闭则使用
./stop-master.sh
然后启动加入master的slave
./start-slave.sh spark://hadoop102:7077
可以看到加入成功
如果先退出master
./stop-slave.sh对于work机器限定内存
./start-slave.sh spark://hadoop102:7077 --memory 500M
可以看到设置成功
集群配置
| hadoop102 | hadoop103 | hadoop104 |
| master,work | work | work |
| historyserver |
环境准备
前提有java环境
然后集群的机器都配置了spark的环境变量
配置环境变量
sudo vi /etc/profile.d/my_en.sh#SPARK_HOME
export SPARK_HOME=/home/atguigu/spark-3.0.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/binsource /etc/profile.d/my_en.sh开始配置和安装
进入配置目录, 并复制一份新的配置文件spark-env.sh, 以供在此基础之上进行修改
cd /home/atguigu/spark-3.0.0-bin-hadoop2.7/conf
cp spark-env.sh.template spark-env.sh
vi spark-env.shexport JAVA_HOME=/opt/module/jdk/jdk1.8.0_161
# 指定 Spark Master 地址
export SPARK_MASTER_HOST=hadoop102
export SPARK_MASTER_PORT=7077修改配置文件 slaves, 以指定从节点为止, 从在使用 sbin/start-all.sh 启动集群的时候, 可以一键启动整个集群所有的 Worker
cd /home/atguigu/spark-3.0.0-bin-hadoop2.7/conf
cp slaves.template slaves
vi slaveshadoop102
hadoop103
hadoop104配置 HistoryServer
默认情况下, Spark 程序运行完毕后, 就无法再查看运行记录的 Web UI 了, 通过 HistoryServer 可以提供一个服务, 通过读取日志文件, 使得我们可以在程序运行结束后, 依然能够查看运行过程
复制 spark-defaults.conf, 以供修改
cd /home/atguigu/spark-3.0.0-bin-hadoop2.7/conf
cp spark-defaults.conf.template spark-defaults.conf
vi spark-defaults.confspark.eventLog.enabled true
spark.eventLog.dir hdfs://node01:8020/spark_log
#spark.eventLog.dir (先在每一台机器上面创建对应的目录) /home/atguigu/spark-3.0.0-bin-hadoop2.7/historywork
spark.eventLog.compress true将以下内容复制到`spark-env.sh`的末尾, 配置 HistoryServer 启动参数, 使得 HistoryServer 在启动的时候读取 HDFS 中写入的 Spark 日志
# 指定 Spark History 运行参数
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://node01:8020/spark_log"
#下面是不使用hdfs
#export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=/home/atguigu/spark-3.0.0-bin-hadoop2.7/historywork"为 Spark 创建 HDFS 中的日志目录(保存到本地就不用)
hdfs dfs -mkdir -p /spark_log将 Spark 安装包分发给集群中其它机器
然后
启动 Spark Master 和 Slaves, 以及 HistoryServer
sbin/start-all.sh
sbin/start-history-server.sh结果

执行测试
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
/home/atguigu/spark-3.0.0-bin-hadoop2.7/examples/jars/spark-examples_2.12-3.0.0.jar \
100集群提交作业
pom.xml
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.0.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.1.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<id>shade-my-jar</id>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<!--
zip -d learn_spark.jar META-INF/*.RSA META-INF/*.DSA META-INF/*.SF
-->
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<!-- 修改成自己的启动类-->
<mainClass>com.zhang.one.JavaWordCount</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<!--<arg>-make:transitive</arg>-->
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>测试的程序
object ScalaJoin {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("ScalaJoin")
.setMaster("local")
val stuInfo: Array[(Int, String)] = Array(
(1, "zhangsan"),
(2, "lisi"),
(3, "wanwu")
)
val soreInfo= Array(
(1,90),
(1,80),
(2,90),
(3,90)
)
val sc = new SparkContext(conf)
val stuRDD: RDD[(Int, String)] = sc.parallelize(stuInfo)
val scoreRDD: RDD[(Int, Int)] = sc.parallelize(soreInfo)
stuRDD.join(scoreRDD)
.foreach(println)
sc.stop()
}
}然后打包
client模式提交(这个是默认的提交模式它和cluster的区别就是driver启动的位置不同)
bin/spark-submit \
--class com.zhang.one.scala.ScalaJoin \
--master spark://hadoop102:7077 \
--deploy-mode client \
--executor-memory 1G \
--total-executor-cores 2 \
/home/atguigu/spark-3.0.0-bin-hadoop2.7/original-sparkstart-1.0-SNAPSHOT.jarcluster提交
bin/spark-submit \
--class com.zhang.one.scala.ScalaJoin \
--master spark://hadoop102:7077 \
--deploy-mode cluster \
--executor-memory 1G \
--total-executor-cores 2 \
/home/atguigu/spark-3.0.0-bin-hadoop2.7/original-sparkstart-1.0-SNAPSHOT.jar集群提交的 时候有时候会出现(这是由于集群环境下Driver是随机的在一台机器上面启动,如果启动的时候不在有jar包的机器上面那么就会说找不到文件,我们可以把它分发到集群的所有work机器就不会出现了,yarn模式就没有这个问题)
java.nio.file.NoSuchFileException: /home/atguigu/spark-3.0.0-bin-hadoop2.7/original-sparkstart-1.0-SNAPSHOT.jar
at sun.nio.fs.UnixException.translateToIOException(UnixException.java:86)
at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:102)
at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:107)
at sun.nio.fs.UnixCopyFile.copy(UnixCopyFile.java:526)
at sun.nio.fs.UnixFileSystemProvider.copy(UnixFileSystemProvider.java:253)
at java.nio.file.Files.copy(Files.java:1274)
at org.apache.spark.util.Utils$.copyRecursive(Utils.scala:690)
at org.apache.spark.util.Utils$.copyFile(Utils.scala:661)
at org.apache.spark.util.Utils$.doFetchFile(Utils.scala:735)
at org.apache.spark.util.Utils$.fetchFile(Utils.scala:535)
at org.apache.spark.deploy.worker.DriverRunner.downloadUserJar(DriverRunner.scala:166)
at org.apache.spark.deploy.worker.DriverRunner.prepareAndRunDriver(DriverRunner.scala:177)
at org.apache.spark.deploy.worker.DriverRunner$$anon$2.run(DriverRunner.scala:96)
22/07/10 11:34:23 INFO ShutdownHookManager: Shutdown hook called
22/07/10 11:34:23 INFO ShutdownHookManager: Deleting directory /tmp/spark-b30b0542-0048-4784-989a-626bdb582bd8边栏推荐
- M simulation of UWB MIMO radar target detection based on MATLAB, considering time reversal
- Redis details
- Download, configuration and basic use of C language compiler
- MySql
- 爬虫基础—代理的基本原理
- urllib库的使用
- nodejs
- web安全(xss及csrf)
- What role does 5g era server play in this?
- Install SQL developer for Galaxy Kirin desktop operating system v10sp1 (x86)
猜你喜欢

【操作细则】如何实现TSN系统级测试?

一文带你了解SOA接口测试

2021-10-25 浏览器兼容遇到的问题
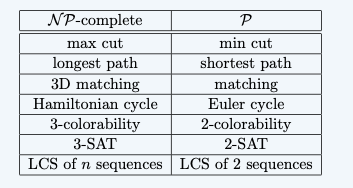
Review of 4246 Algorithms for Data Science
Paper reading: deep residual learning in spiking neural networks

Matlab implementation code of image denoising method based on Hidden Markov tree model in wavelet domain

TypeScript(一)

Review of 4705 NLP

Hypothesis testing

Data analysis and visualization -- the shoes with the highest sales volume on jd.com
随机推荐
My world 1.12.2 Magic Baby (Fairy treasure dream) service opening tutorial
Matlab simulation of cognitive femtocell performance in m3gpp LTE communication network
web安全(xss及csrf)
网络知识-04 网络层-IPv4协议
shader入门之基础光照知识
Review of 4121 Computer System for Data Science
Coursera deep learning notes
爬虫基础—多线程和多进程的基本原理
express
Sword finger offer question brushing record - offer 07 Rebuild binary tree
Speed feedback single closed loop DC speed regulation system based on Simulink
Redis(二) - Jedis
Typescript (TS loader, tsconfig.json and lodash)
Network knowledge-05 transport layer UDP
JS does not use async/await to solve the problem of data asynchrony / synchronization
爬虫基础—爬虫的基本原理
M FPGA implementation of chaotic digital secure communication system based on Lorenz chaotic self synchronization, Verilog programming implementation, with MATLAB chaotic program
How to open the service of legendary mobile games? How much investment is needed? What do you need?
Product Case Interviews
MySQL正则表达式^和$用法