当前位置:网站首页>Coursera deep learning notes
Coursera deep learning notes
2022-07-19 07:24:00 【Alex Tech Bolg】
Contents
Setting up your Machine Learning Application
Train/Dev/Test sets
- Train and dev set don’t need to be 70% - 30%. (Dev set just needs to be big enough for us to evaluate. )
- Make sure dev and test set come from same distribution. (Deep learning model needs to be fed lots of data to train, so sometime we need web crawler to get more data, which comes from different distribution. This rule of thumb can make that the progress in machine learning algorithm will be faster. )
- If you don’t need an unbiased estimate of performance, it’s fine to only have train and dev set.
Bias / Variance
- optimal (Bayes) error
- Compare the error on train and dev set with the optimal (Bayes) error to diagnose whether the model has high bias or high variance or both or neither.
Basic Recipe for Machine Learning
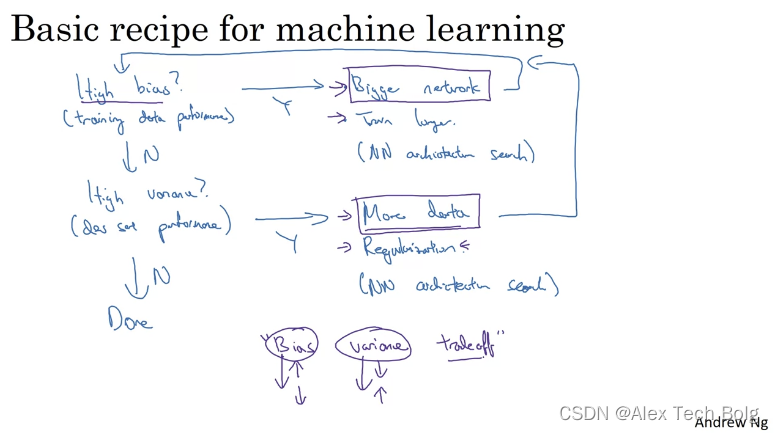
Regularizing your Neural Network
Regularization
- L2 regularization (Frobenius norm) - also called weight decay
- L1 regularization

Why Regularization Reduces Overfitting?
- The first intuitive explanation : hold λ \lambda λ Set it to a very large value , A lot of parameters w become 0, In this way, the model changes from a complex neural network to a simpler neural network , Extreme cases may become linear models .
- Second interpretation : With tanh For example , increase λ \lambda λ,w Reduce ,z Will be limited to a smaller range , This section covers tanh On , It happens to be approximately linear
Dropout Regularization
implement dropout (inverted dropout)

- Inverted dropout In order not to change E(Z), In this way, when forecasting , There will be no more scaling The problem of
- In every time iteration, It's different notes By dropout Set to 0
Making predictions at test time
- No dropout - dropout Will increase the predicted noise
Understanding Dropout

- Intuition: purple note Cannot rely on one input, Because every one of them input Can be random eliminate, therefore dropout Sure spread out weights, So that's what happened shrink weights The role of , So with L2 normalization Same effect .
- Downside:loss function J Difficult to calculate , Because every time dropout It's all random , So we can't go through loss To see how well the model is trained . The common practice is to put dropout Get rid of , If loss function The curve drops well , Then take it. dropout add , Look at the change of the final result .
Other Regularization Methods
Data augmentation
Early stopping
Setting Up your Optimization Problem
Normalizing Inputs
- Normalize training data. Then use same μ \mu μ and σ \sigma σ to normalize test data because we want to guarantee the train and test data go through same transformation.
Why normalize inputs?
- Rough intuition:Your cost function will be in a more round and easier to optimize when your features are on similar scales.
- For dramatic difference of scales in features, it is important to normalize them. If your features come in on similar scales, then this step is less important although performing this normalization pretty much never does any harm.
Vanishing / Exploding Gradients
- If your activations or gradients increase or decrease exponentially as a function of L(number of layers), then these values could get really big or small. This will make training very difficult.
- Especially for exponentially small, the gradient descent will take tiny little steps, which will take a long time for gradient descent to learn anything.
Weight Initialization for Deep Networks
边栏推荐
- Network knowledge-03 data link layer PPP
- Sword finger offer question brushing record - offer 06 Print linked list from end to end
- 网络知识-05 传输层-TCP
- AB Testing Review
- Network knowledge-04 network layer IPv4 protocol
- 组件emit基础
- Review of 4705 NLP
- 剑指Offer刷题记录——Offer 03. 数组中重复的数字
- Review - 5703 Statistical Inference and Modeling
- 基于simulink的转速反馈单闭环直流调速系统
猜你喜欢

MySQL正则表达式^和$用法

爬虫基础—代理的基本原理
JS不使用async/await解决数据异步/同步问题

SQL刷题总结 SQL Leetcode Review

m基于Simulink的高速跳频通信系统抗干扰性能分析

The principle of SYN Flood attack and the solution of SYN Flood Attack

Network knowledge-04 network layer IPv6

网络知识-04 网络层-IPv4协议
Paper reading: deep residual shrink networks for fault diagnosis
Fundamentals of crawler - basic principles of agent
随机推荐
Connaissance du réseau - 03 couche de liaison de données - PPPoE
字典、元組和列錶的使用及區別,
解决Mysql (1064) 错误: 1064 - You have an error in your SQL syntax;
FreeBSD 12 domestic source speed up PKG and ports take a note
express
Debug wechat one hop under linxu (Fedora 27)
Security自动登录与防CSRF攻击冲突解决办法
剑指Offer刷题记录——Offer 04. 二维数组中的查找
Execute shell script under Linux to call SQL file and transfer it to remote server
剑指Offer刷题记录——Offer 07.重建二叉树
m基于matlab的超宽带MIMO雷达对目标的检测仿真,考虑时间反转
【量化笔记】波动volatility相关技术指标以其含义
9. Account and authority
4.IDEA的安装与使用
How does the advanced anti DDoS server confirm which are malicious ip/ traffic? ip:103.88.32. XXX
剑指Offer刷题记录——Offer 05. 替换空格
Ivew shuttle box transfer component highlights the operation value
Sword finger offer question brushing record - offer 05 Replace spaces
网络知识-03 数据链路层-PPPoE
Summary of Statistics for Interview