当前位置:网站首页>Pytorch deep learning practice-b station Liu erden-day3
Pytorch deep learning practice-b station Liu erden-day3
2022-07-19 06:41:00 【Watermelon that loves programming】
Back propagation back propagation
B standing Lord Liu , Portal PyTroch Deep learning practice —— Back propagation
Code instructions :
1、w yes Tensor( Tensor type ),Tensor Contained in the data and grad,data and grad It's also Tensor.grad For the initial None, call l.backward() After the method w.grad by Tensor, So update w.data To be used w.grad.data. If w You need to calculate the gradient , In the constructed calculation diagram , Follow w dependent tensor By default, you need to calculate the gradient .
In Teacher Liu's video a = torch.Tensor([1.0]) In this article, it is changed to a = torch.tensor([1.0]). Either way , Personal habits second .
import torch
a = torch.tensor([1.0])
a.requires_grad = True # perhaps a.requires_grad_()
print(a)
print(a.data)
print(a.type()) # a The type is tensor
print(a.data.type()) # a.data The type is tensor
print(a.grad)
print(type(a.grad))
The result is :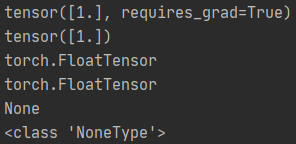
2、w yes Tensor, forward The return value of the function is also Tensor,loss The return value of the function is also Tensor
3、 Back propagation in this algorithm is mainly embodied in ,l.backward(). After calling this method w.grad from None Updated to Tensor type , And w.grad.data The value of is used for subsequent w.data Update .
l.backward() Will calculate all the required gradients in the graph (grad) All places will be found , Then the gradients are stored in the corresponding parameters to be solved , The final calculation diagram is released .
take tensor Medium data The calculation diagram will not be built .
import torch
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = torch.tensor([1.0]) # w The initial value for the 1.0
w.requires_grad = True # You need to calculate the gradient
def forward(x):
return x*w # w It's a Tensor
def loss(x, y):
y_pred = forward(x)
return (y_pred - y)**2
print("predict (before training)", 4, forward(4).item())
for epoch in range(100):
for x, y in zip(x_data, y_data):
l =loss(x,y) # l It's a tensor ,tensor Mainly in the establishment of calculation diagram forward, compute the loss
l.backward() # backward,compute grad for Tensor whose requires_grad set to True
print('\tgrad:', x, y, w.grad.item())
w.data = w.data - 0.01 * w.grad.data # Weight update , Be careful grad Also a tensor
w.grad.data.zero_() # after update, remember set the grad to zero
print('progress:', epoch, l.item()) # Take out loss Use l.item, Don't use... Directly l(l yes tensor Will build a calculation diagram )
print("predict (after training)", 4, forward(4).item())
Three assignments left in the course
1、 Manually derive the linear model y=w*x, Loss function loss=(ŷ-y)² Next , When data sets x=2,y=4 When , The process of back propagation .
answer :
2、 Manually derive the linear model y=w*x+b, Loss function loss=(ŷ-y)² Next , When data sets x=1,y=2 When , The process of back propagation .
answer :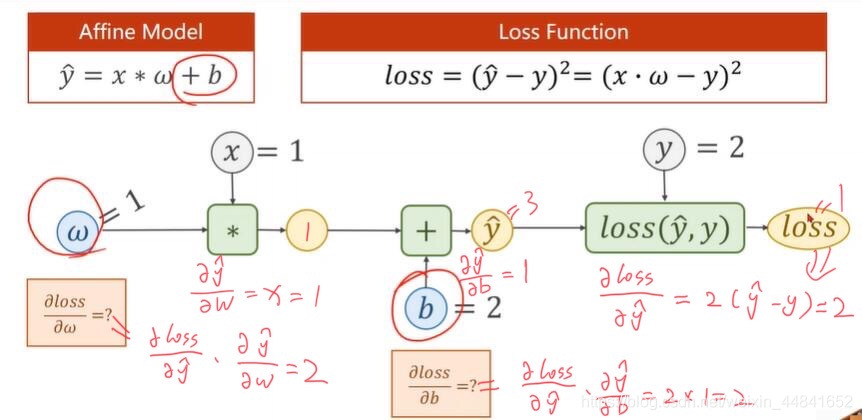
3、 Draw a quadratic model y=w1x²+w2x+b, Loss function loss=(ŷ-y)² The calculation chart of , And manually deduce the process of back propagation , Last use pytorch Code implementation of .
answer :
The process of construction and derivation 
import numpy as np
import matplotlib.pyplot as plt
import torch
x_data = [1.0,2.0,3.0]
y_data = [2.0,4.0,6.0]
w1 = torch.Tensor([1.0])# Initial weight
w1.requires_grad = True# Calculate the gradient , The default is not calculated
w2 = torch.Tensor([1.0])
w2.requires_grad = True
b = torch.Tensor([1.0])
b.requires_grad = True
def forward(x):
return w1 * x**2 + w2 * x + b
def loss(x,y):# Build a calculation diagram
y_pred = forward(x)
return (y_pred-y) **2
print('Predict (befortraining)',4,forward(4))
for epoch in range(100):
l = loss(1, 2)# In order to be in for Define before the loop l, So that later output , No practical significance
for x,y in zip(x_data,y_data):
l = loss(x, y)
l.backward()
print('\tgrad:',x,y,w1.grad.item(),w2.grad.item(),b.grad.item())
w1.data = w1.data - 0.01*w1.grad.data # Notice the grad It's a tensor, So take his data
w2.data = w2.data - 0.01 * w2.grad.data
b.data = b.data - 0.01 * b.grad.data
w1.grad.data.zero_() # Release the gradient calculated before
w2.grad.data.zero_()
b.grad.data.zero_()
print('Epoch:',epoch,l.item())
print('Predict(after training)',4,forward(4).item())
Conclusion
In use y=w1x²+w2x+b Model training 100 You can see when x=4 when ,y=8.5, And correct value 8 There's a big difference . The reason may be that the data set itself is the data of a function , The model is a quadratic function . So the model itself is not suitable for this data set , That is why there is a big difference between the predicted result and the correct value .
边栏推荐
猜你喜欢

wireshark抓包:报文信息

Perceive the attention status of users on smart phones

自下而上和自上而下的注意力:不同的过程和重叠的神经系统 2014sci
![Open source online markdown editor -- [editor.md]](/img/f3/b37acf934aa2526d99c8f585b6f229.png)
Open source online markdown editor -- [editor.md]

机器学习篇-逻辑回归的分类预测

Visual saliency based visual gaze estimation

Restclient query document

Hand in hand building a home NAS universal server (1) | configuration selection and preparation

DSL implements bucket aggregation
基于视觉显著性的外观注视估计
随机推荐
UDP的报文结构
Preparation of blast Library of rust language from scratch (1) -- Introduction to the basics of blas
Part of the second Shanxi Network Security Skills Competition (Enterprise Group) WP (IV)
网络中的一些基本概念
Visual saliency based visual gaze estimation
锁
From entering URL to displaying page
Binary search and its extension
Open source online markdown editor -- [editor.md]
三维凝视估计,没有明确的个人校准2018
Color histogram grayscale image & color image
Eye tracking in virtual reality
Depth first search (DFS for short)
Get the current month, day, hour, minute, second and week, and update them in real time
无80和443端口下申请域名SSL证书(适用于 acme.sh 和 certbot)
網絡中的一些基本概念
Face recognition error
人脸识别错误
Restapi implements aggregation (dark horse tutorial)
网络层及ip学习