当前位置:网站首页>Relationship between standardization, normalization and regularization
Relationship between standardization, normalization and regularization
2022-07-19 10:07:00 【A Sheng】
First , Standardized English is Standardization, Normalized English is Normalization, Regularization in English is Regularization. Standardization is a way of scaling features , It should be noted that the data distribution after standardization is not necessarily normal , Because standardization does not change the distribution of raw data . The purpose of normalization is to eliminate the influence of different dimensions and units , Improve the comparability between data . The purpose of regularization is to prevent over fitting . The article involves code download reference [5].
One . Standardization
1. Standardized equation
The most commonly used standardization is Z-Score Standardization , The simple understanding is to reduce the mean , And divide it by the standard deviation . The equation is as follows :
among , That's the sample mean , Is the sample standard deviation .
2. Standardized visualization
The standardization process is divided into 2 A step , The first 1 Step is to subtract the mean value , The first 2 The first step is to divide by the standard deviation . The visual analysis is as follows : 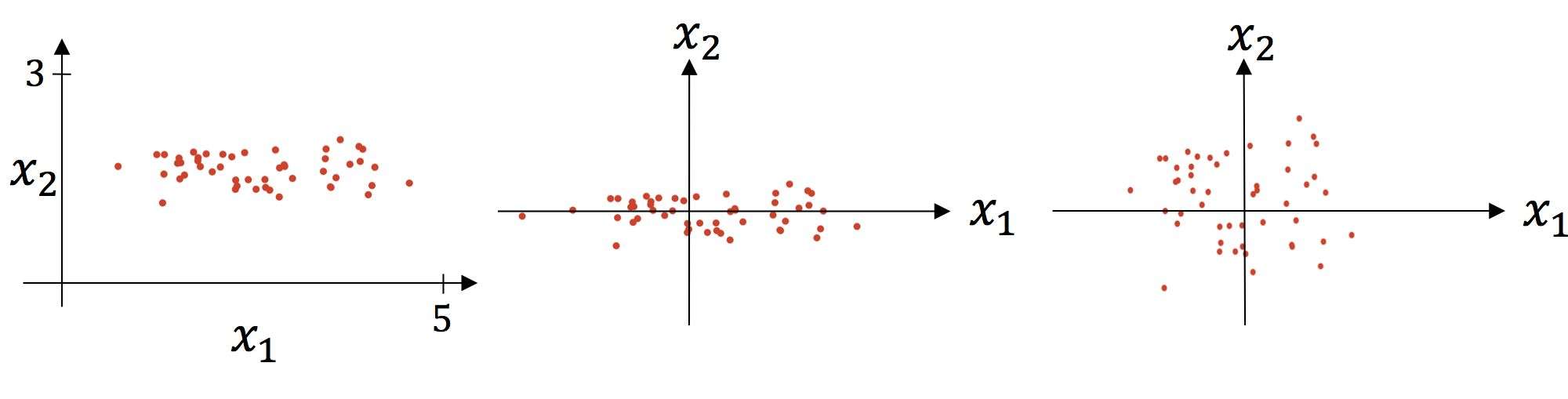 The left figure in the above figure is the visualization of the original figure , The middle figure is the visualization after subtracting the mean , The right figure is the visualization after dividing by the standard deviation .
The left figure in the above figure is the visualization of the original figure , The middle figure is the visualization after subtracting the mean , The right figure is the visualization after dividing by the standard deviation .
3. Standardized implementation
from sklearn import preprocessing
import numpy as np
X_train = np.array([[1., -1., 2.], [2., 0., 0.], [0., 1., -1.]])
X_train_result = preprocessing.scale(X_train, axis=0) #axis=0 Means to standardize by column
print(X_train_result)
print(X_train_result.mean(axis=0)) # The mean for 0
print(X_train_result.std(axis=0)) # The standard deviation is 1
The output is as follows :
[[ 0. -1.22474487 1.33630621]
[ 1.22474487 0. -0.26726124]
[-1.22474487 1.22474487 -1.06904497]]
[0. 0. 0.]
[1. 1. 1.]
If you are doing machine learning model training , I want to apply the scaling standard of the training set to the test set , Then use StandardScaler() This class . The code is as follows :
from sklearn import preprocessing
import numpy as np
X_train = np.array([[1., -1., 2.], [2., 0., 0.], [0., 1., -1.]])
scaler = preprocessing.StandardScaler().fit(X_train)
X_scaled = scaler.transform(X_train)
print(X_scaled.mean(axis=0)) # The mean for 0
print(X_scaled.std(axis=0)) # The standard deviation is 1
X_test = [[-1., 1., 0.]] # Use the scaling criteria of the training set to standardize the test set , The scaling standard here refers to the mean and standard deviation of the columns of the training set
print(scaler.transform(X_test))
The output is as follows :
[0. 0. 0.]
[1. 1. 1.]
[[-2.44948974 1.22474487 -0.26726124]]
Two . normalization
Normalization is to compress the data into an interval , such as [0,1]、[-1,1]. frequently-used 2 The two methods are as follows :
1.Min-Max Normalization
The equation is as follows :
The normalized range is [0,1]. The code implementation is as follows :
import numpy as np
from sklearn import preprocessing as pp
X_train = np.array([[ 1., -5., 8.], [ 2., -3., 0.], [ 0., -1., 1.]])
scaler = pp.MinMaxScaler().fit(X_train) # The default data compression range is [0,1]
print(scaler.transform(X_train))
The output is as follows :
[[0.5 0. 1. ]
[1. 0.5 0. ]
[0. 1. 0.125]]
2.Mean Normalization
The equation is as follows :
The normalized range is [-1,1].
import numpy as np
from sklearn import preprocessing as pp
X_train = np.array([[ 1., -5., 8.], [ 2., -3., 0.], [ 0., -1., 1.]])
scaler = pp.MinMaxScaler(feature_range=(-1, 1)) # Set the data compression range to [-1,1]
scaler = scaler.fit(X_train)
print(scaler.transform(X_train))
The output is as follows :
[[ 0. -1. 1. ]
[ 1. 0. -1. ]
[-1. 1. -0.75]]
The above code mainly uses scikit-learn Preprocessing sub module of preprocessing Provide MinMaxScaler Class to realize the normalization function .MinMaxScaler Class has an important parameter feature_range, This parameter is used to set the range of data compression , The default value is [0,1].
3、 ... and . Regularization
Simply understand that the purpose of using regularization is to prevent over fitting , Of course, there are other ways to prevent over fitting , For example, reduce the feature dimension . Let's take an example to explain why reducing the feature dimension can also prevent over fitting , Then explain how regularization can prevent over fitting . First of all, we should understand the essence of fitting ? That is, the noise is also modeled as the characteristics of things . If a bird gets hurt , Can't fly for the time being , When building bird classifiers , The noise of flying can also be learned into the characteristics of the model , In this way, a normal bird that can fly is judged not to be a bird , Of course, this is a far fetched example of over fitting , But it can also explain some problems . How does regularization prevent over fitting ?
For a given data set , Consider the simplest linear regression model , Take the square error as the loss function , The optimization objectives are as follows :
introduce L2 Norm regularization , It is called ridge regression [ridge regression], As shown below :
introduce L1 Norm regularization , be called LASSO[Least Absolute Shrinkage and Selection Operator] Return to , As shown below :
Suppose the data dimension is 2 dimension , Through the equation ( There is no derivation here , If you are interested, please refer to [3]) You can make the following figure , The left figure is , The picture on the right is . It can be seen that with increase , More and more parameters will become 0:  The purpose is to find the weight value corresponding to the minimum value of the loss function , The blue circle in the figure below is the isoline of the square error term , When taking the center point of the ellipse , Loss function ( The loss function mentioned here does not include regularization ) Minimum value . The total loss function ( The loss function here includes regularization ) Is to ask for the blue circle + The minimum value of the sum of the red circle .
The purpose is to find the weight value corresponding to the minimum value of the loss function , The blue circle in the figure below is the isoline of the square error term , When taking the center point of the ellipse , Loss function ( The loss function mentioned here does not include regularization ) Minimum value . The total loss function ( The loss function here includes regularization ) Is to ask for the blue circle + The minimum value of the sum of the red circle .
The regularization method is a constant , It limits the complexity of the model , So that complex models can be trained on limited data sets , Without serious over fitting . The smaller the regular term , The smaller the punishment , In extreme cases, the regular term is 0 when , It will cause over fitting problems ; The larger the regularization , The more severe the punishment is , It will be prone to the problem of under fitting . From the above figure, you can see intuitively the adoption of L1 The intersection of the isoline of the norm time square error term and the isoline of the regularization term appears on the coordinate axis , namely perhaps . When L2 When the norm is , The intersection of the two often appears in a quadrant , namely And . In this way L1 Regularization ratio L2 Regularization is easier to get sparse solution .L2 The advantage of regularization is that it can be derived everywhere ,L1 Regularization has inflection points , It is not differentiable everywhere , But we can get a more sparse solution .
From the above figure, you can see intuitively the adoption of L1 The intersection of the isoline of the norm time square error term and the isoline of the regularization term appears on the coordinate axis , namely perhaps . When L2 When the norm is , The intersection of the two often appears in a quadrant , namely And . In this way L1 Regularization ratio L2 Regularization is easier to get sparse solution .L2 The advantage of regularization is that it can be derived everywhere ,L1 Regularization has inflection points , It is not differentiable everywhere , But we can get a more sparse solution .
reference :
[1]Preprocessing data:https://scikit-learn.org/stable/modules/preprocessing.html
[2] What is the meaning of regularization often mentioned in machine learning :https://www.zhihu.com/question/20924039
[3] Pattern recognition and machine learning [ Chinese version ]:https://url39.ctfile.com/f/2501739-616549609-5fe8d7?p=2096 ( Access password : 2096)
[4] Pattern recognition and machine learning [ English version ]:https://url39.ctfile.com/f/2501739-616549614-9897ab?p=2096 ( Access password : 2096)
[5] Standardization 、 The relationship between normalization and regularization .py:https://url39.ctfile.com/f/2501739-616549789-16fc6a?p=2096 ( Access password : 2096)
边栏推荐
- 【C语言】浅涉常量、变量
- 【摸鱼神器】UI库秒变低代码工具——表单篇(二)子控件
- 华为无线设备配置动态负载均衡
- Online education knowledge payment website source code system + live broadcast + applet, installation tutorial
- cmake -- 笔记
- vc查看内存泄漏
- 网络安全学习(千锋网络安全笔记)1--搭建虚拟机
- es索引、类型(mapping)、文档、ik分词器
- Flink introduction to actual combat - phase IV (time and window diagram)
- 硫化镉负载MIL-125(Ti)|链霉亲和素(SA)-锆基卟啉MOF复合材料([email protected])|壳核结构
猜你喜欢





![[C language] involves constants and variables](/img/4c/1ec1a47865eeccfb490ebf4732256f.png)



随机推荐
【摸鱼神器】UI库秒变低代码工具——表单篇(二)子控件
NPM usage
光辉使用输出
Huawei wireless device configuration dynamic load balancing
Vim详解
[C language] a brief introduction to the first C language program and data type
The module created by yourself uses CMD to open the report modulenotfounderror: no module named solution
卫星网络中基于时变图的节能资源分配策略
FAW Toyota Asia lion's first product refresh
Chapter 4 - first order multi-agent system consistency - > switching topology system consistency
软件工程——软科中国大学专业排名
工程效能CI/CD之流水线引擎的建设实践
[C language] string, escape character and comment
[fishing artifact] UI library second low code tool - form part (II) sub control
mof定制材料|双金属CuNi-MOF纳米材料|核—壳结构[email protected]纳米复合材料|ZIF-8/聚偏氟乙烯复合纳米纤维膜PVDF
Database overview
VIM details
Week 1: introduction to deep learning and foundation of pytorch
钴铁双金属有机骨架Cox/MIL-100(Fe)|光敏剂@[email protected]|负载CQDs的FeMIL101材料|mof试剂
node+express搭建服务器环境